转载:https://m.aliyun.com/doc/document_detail/29341.html
测试监控
2017-06-07 13:26:11
- 1 引言
- 1.1 编写目的
- 1.2 适用对象和范围
- 1.3 参考文档
- 2 业务指标监控
- 2.1 监控指标
- 2.2 监控工具
- 3 操作系统指标监控
- 3.1 Linux
- 3.2 Windows
- 4 应用中间件指标监控
- 4.1 Tomcat
- 4.2 JBoss
- 4.3 IIS监控
- 4.4 JVM
- 4.5 .NET CLR
- 5 数据库指标监控
- 5.1 MySQL
- 5.2 SQLServer
- 5.3 MonogoDB
- 5.4 Redis
- 6 前端指标监控
- 6.1 监控指标说明
- 6.2 监控工具
1 引言
1.1 编写目的
本文档主要目标是规范使用性能测试过程中需监控的各项技术指标,描述各指标项的具体含义,并给出相应的监控工具与方法说明。本文档将作为测试监控的指导性规范,用以选取监控关注指标,使用监控工具。
1.2 适用对象和范围
监控指标及监控工具适用于使用性能测试进行性能测试项目技术质量评价依据。 预期读者为测试管理人员、测试实施人员、技术支持人员、项目质量管理人员、项目管理人员等系统技术质量相关人员。
1.3 参考文档
相关的指标定义及解释可以参照:性能测试指标,本章可能会增加及减少相关指标的描述,并不与性能测试指标中相关指标冲突。
2 业务指标监控
2.1 监控指标
业务指标主要包括并发用户数、响应时间、处理能力,成功率这四个指标,目前大部分压测工具都能将这些指标放在压测工具里面。
2.2 监控工具
2.2.1 性能测试
性能测试分布式压测工具,将相关业务指标集成在平台上。
2.2.2 后台日志
通过后台日志log,采用分析工具也可进行分析得出TPS,响应时间等。
3 操作系统指标监控
3.1 Linux
3.1.1 监控指标说明
| 指标类型 | 指标名称 | 指标描述 |
|---|---|---|
| CPU | CPU utilization | CPU 的使用时间百分比 |
| System mode CPU utilization | 在系统模式下使用 CPU 的时间百分比 | |
| User mode CPU utilization | 在用户模式下使用 CPU 的时间百分比 | |
| Memory | Page-in rate | 每秒钟读入到物理内存中的页数 |
| Page-out rate | 每秒钟写入页面文件和从物理内存中删除的页数 | |
| Paging rate | 每秒钟读入物理内存或写入页面文件的页数 | |
| Disk | Disk rate | 磁盘传输速率 |
3.1.2 监控工具
3.1.2.1 性能测试
性能测试压测工具监控操作系统指标主要有:
CPU%:所有CPU资源利用率
网络流量:每秒入网出网多少Kb
磁盘:每秒读写多少Kb
3.1.2.2 命令
Linux提供丰富的命令进行监控,针对CPU、Memory、I/O等有一些列命令及参数进行监控。具体如下:
top : 整体查看资源情况。
sar :CPU资源消耗
vmstat:内存相关消耗
iostat: 磁盘相关消耗
………
具体用法和参数,可以参照联机帮助(man top等)。
3.1.2.3 Shell
可以将以上命令通过shell来包装,每隔多少秒监控一次,总共监控多少次,将监控结果写到文件里面。
例如:下面shell就是将CPU Load每隔3秒写到文件里面。
while true ; do uptime | awk -F' average: ' '{print $2}' ;sleep 3;done >> `hostname`_`date +%Y%m%d_%H%M`.uptime
3.1.2.4 nmon
-
Nmon安装 将 nmonXXX.tar.gz 文件复制到计算机。如果使用 FTP,请记住使用二进制模式。
解压该文件,运行 gzip -d nmonXXX.tar.gz
提取该文件,运行tar xvf nmonXXX.tar -
Nmon实时监控 登陆要监控的系统,进入nmon安装目录中
输入命令nmon,运行 nmon(如root用户可能需要输入./nmon).显示的起始屏幕及CPU等信息。如图:
依次按c,m,d即可显示CPU,内存,磁盘等信息。如图:
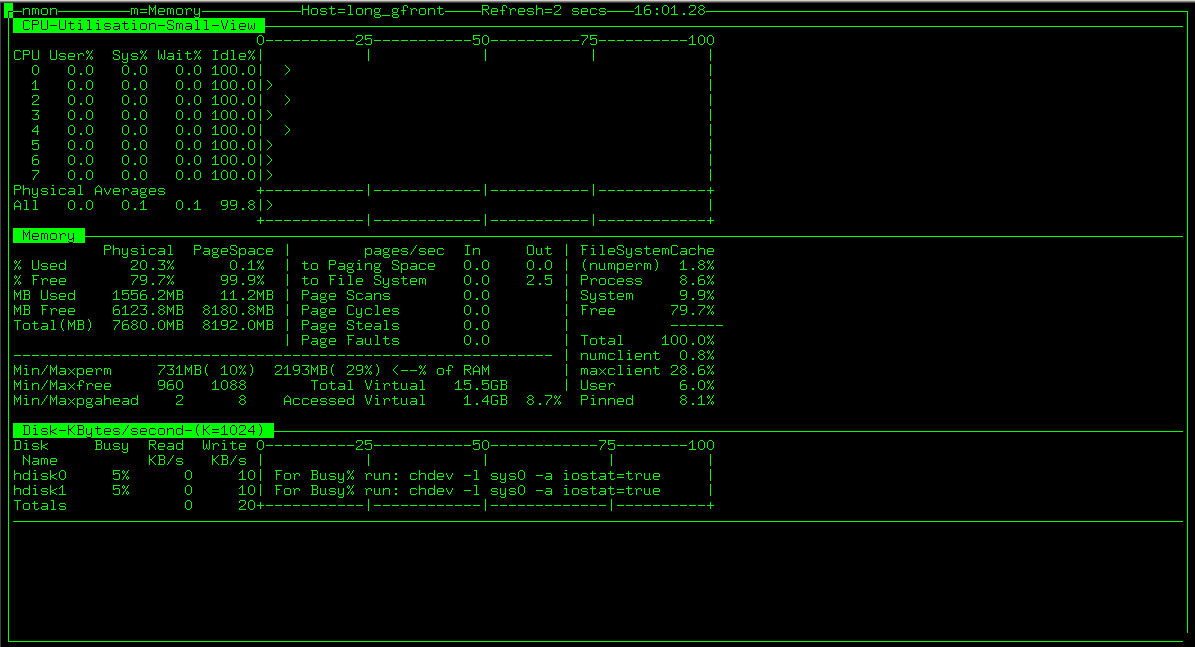
Nmon运行时的键盘命令
| 命令 | 说明 |
|---|---|
| c | 提供关于物理CPU使用的详细信息 |
| m | 提供内存使用的详细信息:系统(内核)和进程,活动虚拟内存 |
| d | 提供关于磁盘,磁盘类型大小,可用空间,卷组,适配器等更详细的信息 |
| t | 当前进程详细情 |
| P | Paging space 使用情况 |
| k | 显示内核信息 |
| + | Nmon 结果保存为文件 |
- Nmon 结果保存为文件 nmon -f -s 60 -c 30(每60s收集一次数据,共收集30次) nmon.sh 赋执行权限:chmod +x nmon.sh 执行nmon.sh 即可运行.
3.2 Windows
3.2.1 监控指标说明
提供的监控指标比较丰富,包括CPU、内存、网络、磁盘以及每个进程的资源。
3.2.2 监控工具
3.2.2.1 性能测试
同3.1.2.1 性能测试
3.2.2.2 资源管理器
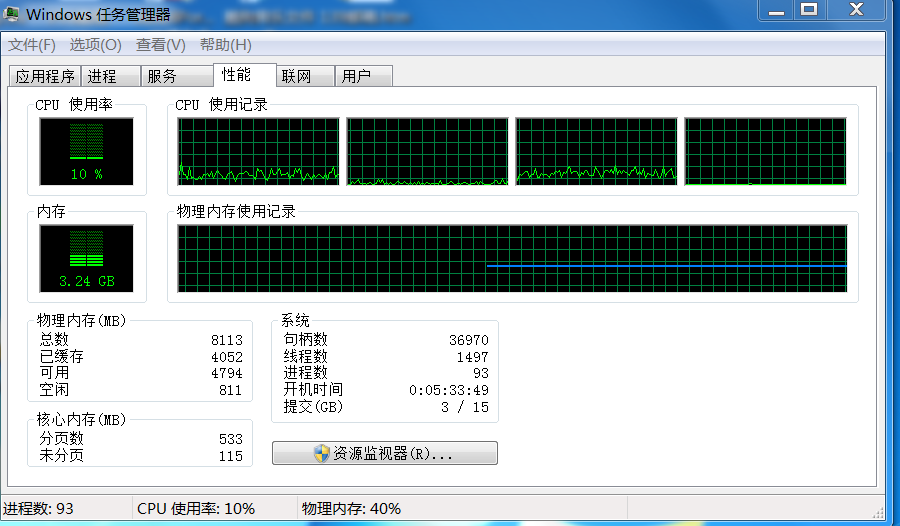
Windows操作系统自带的windows资源管理器,在任务栏里面点击右键,启动任务管理器:
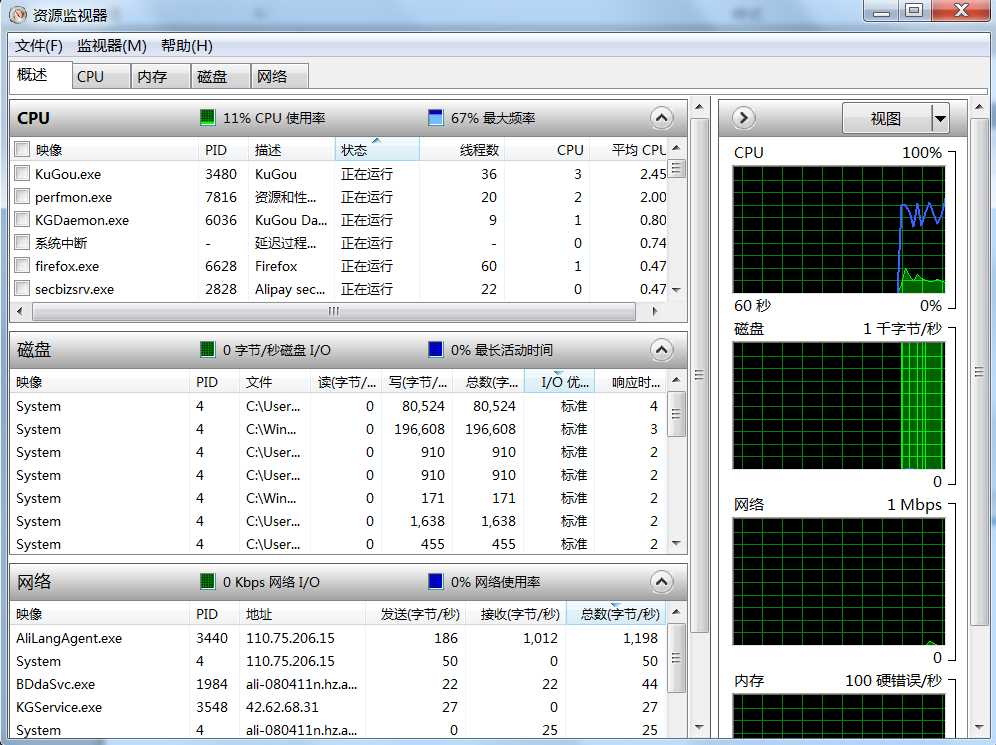
点击性能面板,再点击资源监视器:
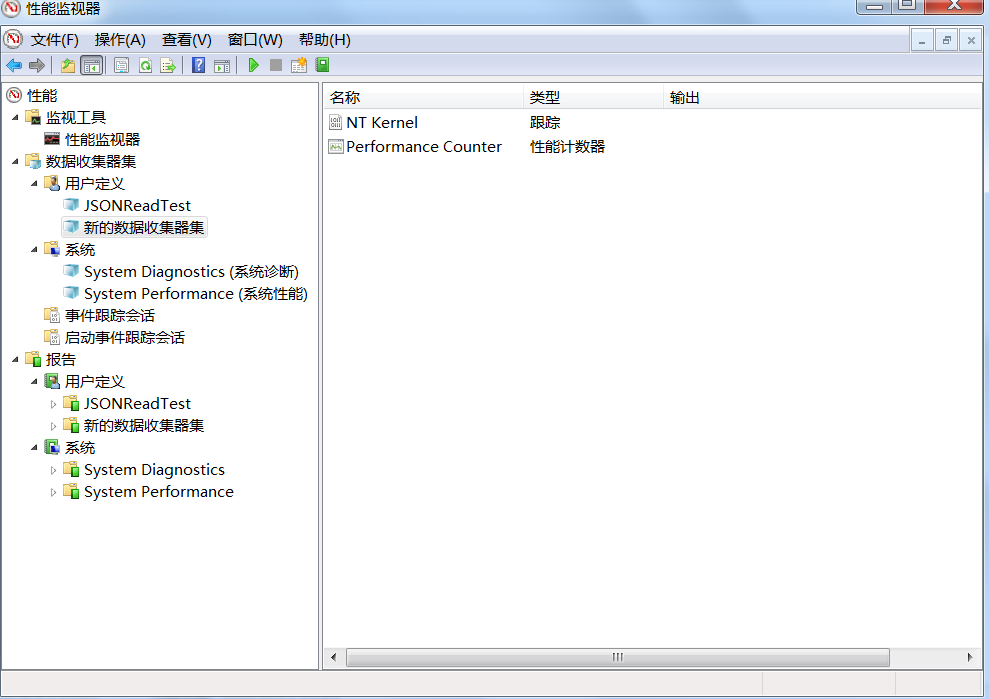
3.2.2.3 性能监视器
Windows有自带的性能监视器,可以指定相关的监控指标进行监控,将结果保存为文件,从windows控制面板->管理工具->性能监视器->新建数据搜集器,添加你感兴趣的指标计数器。
4 应用中间件指标监控
4.1 Tomcat
4.1.1 监控指标说明
Tomcat主要监控线程工作状态、请求数、 会话数、线程数、虚拟主机、JAVA虚拟机内存占用情况。
4.1.2 监控工具
4.1.2.1 Tomcat提供的manager
通过使用Applications Manager(又称opManager)来进行监控。
使用这种方式,所监控Tomcat必须运行manager应用,缺省情况下,该应用总是运行在服务器中的。
-
增加Manager Role: 访问manager应用的用户的角色权限必须是 manager. 修改<TOMCAT_HOME>/conf目录下的tomcat-users.xml文件,在<tomcat-users>节点下添加一个user节点,即可创建一个用户。Tomcat版本不同配置也有差异,5.x和6.x创建的用户角色应为manager,7.x创建的用户角色为manager-jmx,举例如下:
-
在5.x和6.x中创建一个manager角色的用户,用户名为admin,密码为chenfeng: <user username="admin" password="chenfeng" roles="manager"/>
-
在7.x中创建一个manager角色的用户,用户名为admin,密码为xxxxx: <user username="admin" password="chenfeng" roles="manager-jmx,manager-script,manager-status"/> 修改配置后,需要重新启动 Tomcat 服务器。连接manager时将用户名/密码指定为admin/xxxxxxxx
-
-
通过浏览器访问http://localhost:8080/manager/jmxproxy ,输入用户名密码,然后就可以看到返回了所有的监控信息
4.1.2.2 Probe
- 下载: http://www.lambdaprobe.org/downloads/1.7/probe.1.7b.zip
- 解压缩后,把probe.war放到TOMCAT的webapps下,设置server.xml 的context
- 设置用户如下,在tomcat_user.xml中
vi /usr/local/tomcat/conf//tomcat-users.xml
<?xml version='1.0' encoding='utf-8'?>
<tomcat-users>
<role rolename="manager"/>
<role rolename="standard"/>
<role rolename="tomcat"/>
<role rolename="admin"/>
<role rolename="role1"/>
<user username="tomcat" password="tomcat" roles="tomcat"/>
<user username="both" password="tomcat" roles="tomcat,role1"/>
<user username="probe" password="probe" roles="admin,manager"/>
<user username="role1" password="tomcat"roles="role1"/>
</tomcat-users>
-
设置环境变量,获取服务器状态 # vi /etc/profile JAVA_OPTS=-Dcom.sun.management.jmxremote export JAVA_OPTS
-
重启动服务器
- 输入http://localhost/probe/,输入用户名和密码 即可进入,这里比较精彩的是对内存的监视,动态显示了JVM的内存图表
4.1.2.3 JConsole
Linux系统下,需要修改 tomcat主目录\bin\ catalina.sh文件 增加一行 CATALINA_OPTS="$JAVA_OPTS -Djava.rmi.server.hostname=218.28.198.188 -Dcom.sun.management.jmxremote.port=9527 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false" 然后使用JConsole就可以监控Tomcat。 点击%JAVA_HOME%\bin下的jconsole.exe即可
4.1.2.4 JProfile
- 安装 首先到http://www.ej-technologies.com/download/overview.html 上下载 linux 和 windows版本的安装文件. 将 linux版本的文件(jprofiler_linux_7_0_1.sh),上传到服务器上, 将其安装。 安装命令: sh jprofile_linux_7_0_1.sh –c 即可。 Windows版本安装忽略,一路next即可.
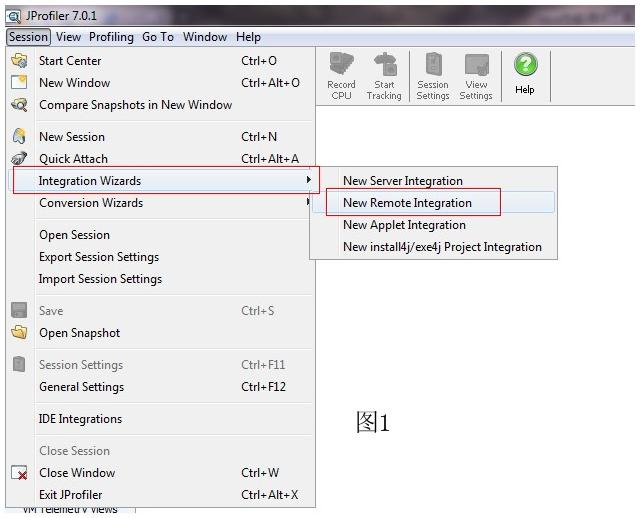
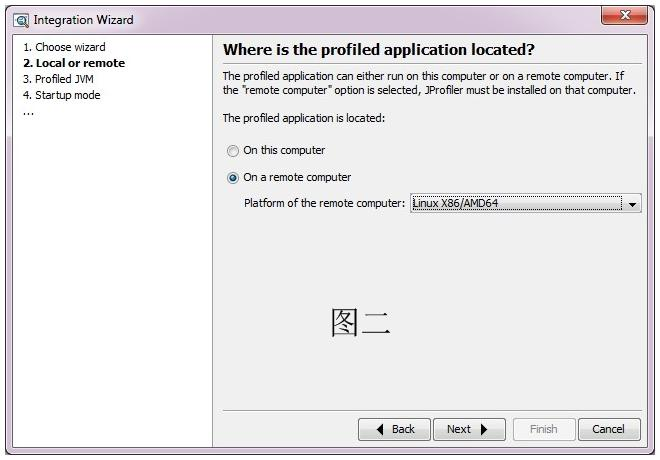
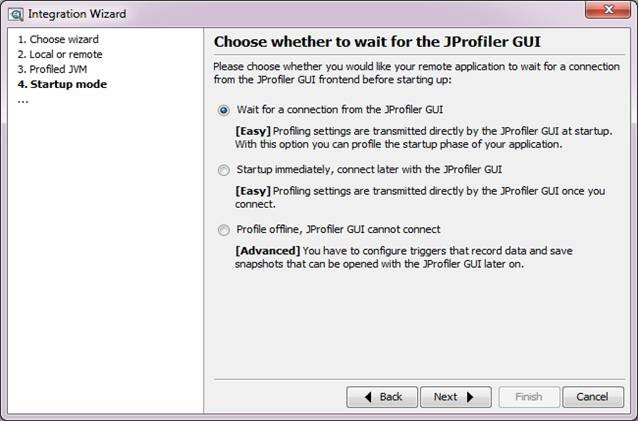
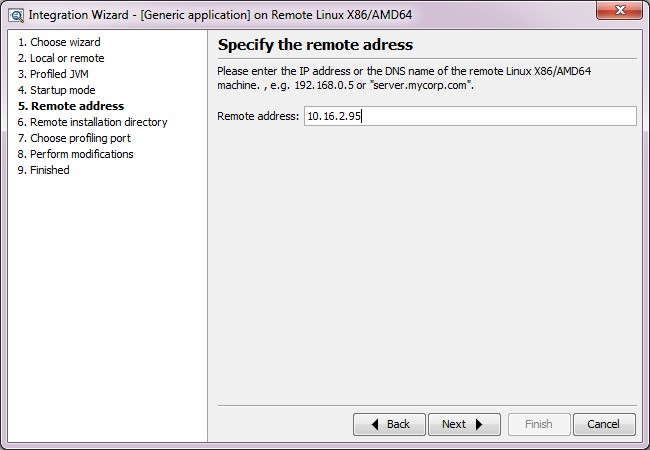
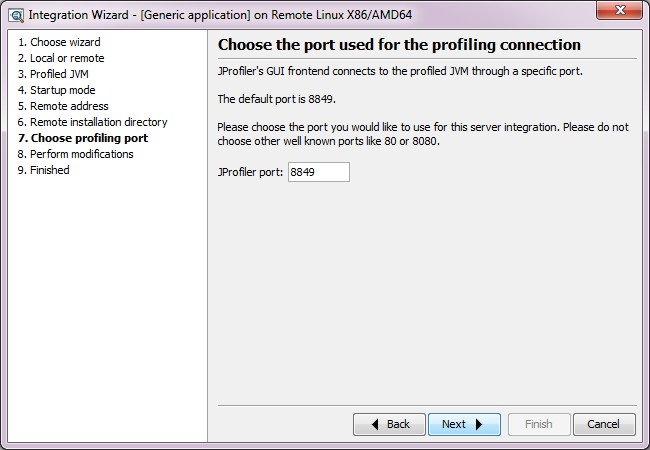
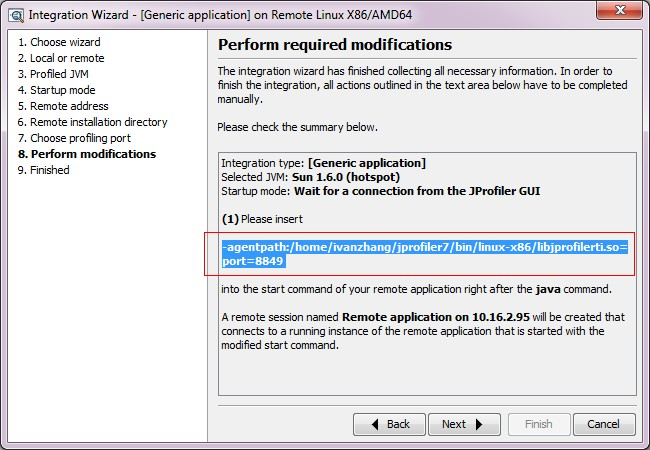
- 按照上图 设置服务器上需要监控的应用启动参数, 如上内容是:
- agentpath:/home/ivanzhang/jprofile7/bin/linux-86/libjprofilerti.so=port=8849 将其加入到应用的启动脚本

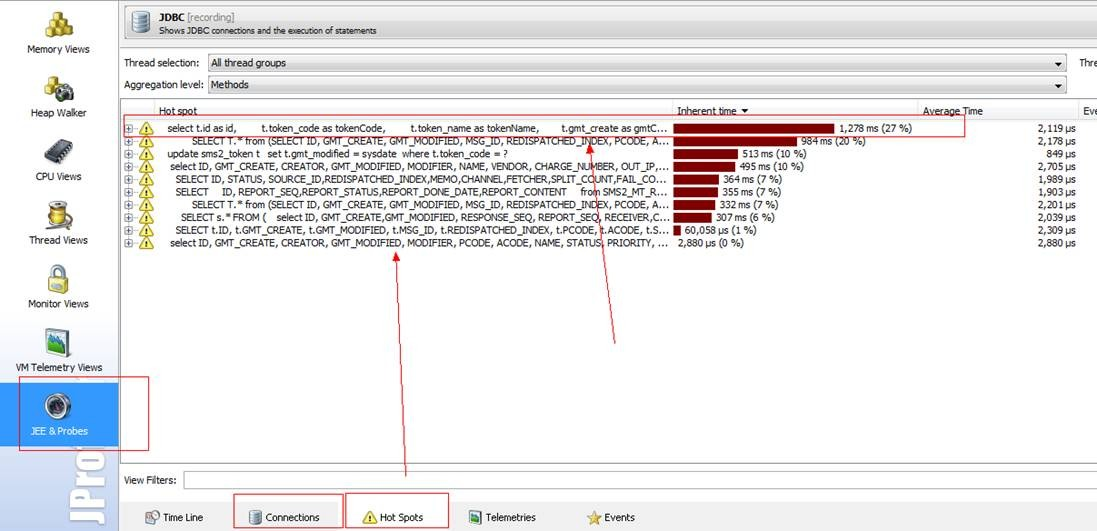
设置好之后, 服务器上的应用,会等待你客户端连接上以后,才真正启动应用。 Jprofile连接上之后,则可以看到一下界面了, 它可以帮助你分析内存信息,线程信息,jdbc连接等等, 以下是监控本地开发机的应用情况,可以看到,哪个线程在跑哪些SQL,由哪些方法调用的。

4.2 JBoss
4.2.1 监控指标说明
JBoss主要监控线程工作状态、请求数、 会话数、线程数、虚拟主机、JAVA虚拟机内存占用情况。
4.2.2 监控工具
4.2.2.1 JBoss管理控制台
如果需要监控jboss的系统资源,如:jboss的基本配置情况,jvm的利用率,线程池的使用情况,可以使用web-console进行监控。
- 配置web-console 具体方法同jmx-console,就是位置不同,具体方法参考jmx-console配置:
- jboss-web xml 、 web.xml 在$JBOSS_HOME/vcom/deploy/management/console-mgr.sar/web-console.war/WEB-INF下;
- login-config.xml还是原来的那个,把application-policy名为$webConsoleDomain的部分改成你需要的web-console;
-
web-console-users.properties、web-console-roles.properties定义了访问 web-console的用户、用户角色,具体位置,使用find /jboss -name web-console-users.properties 找到以后可以修改用户名、密码。
-
监控 使用http://localhost:8080/web-console/ 中,获取当前JBOSS-WEB应用模块的负载分担情况,并可以查看到当前JAVA虚拟机的内存使用情况,及线程池使用情况。 使用http://localhost:8080/web-console/status,可以进一步监控到每个线程的状态。
4.2.2.2 Probe
具体可以参照4.1.2.2 Probe
4.2.2.3 JConsole
具体可以参照4.1.2.3 JConsole
4.2.2.4 JProfile
具体可以参照4.1.2.4 JProfile
4.3 IIS监控
4.3.1 监控指标说明
主要针对会话、事务、缓存、内存、线程池等进行监控,具体如下:
- ASP Session Duration 最近进行的会话所持续的时间(以毫秒为单位)。
- ASP Sessions Current 正在使用服务的会话数。
- IIS Global Total Files Cached 添加到 WWW 和 FTP 服务的缓存的文件总数。
- Web Total Not Found Errors 由于未找到所请求的文档,Web 服务无法满足的请求数;通常以 HTTP 404 错误代码方式向客户端报告。
- ASP Transactions Committed 已提交的事务数。
- ASP Transactions Pending 正在处理的事务数。
- ASP Transactions/Sec 每秒启动的事务数。
- IIS Global URI Cache Hits URI 缓存中的成功查找总数。
- IIS Global URI Cache Hits % URI 缓存命中数占全部缓存请求的比率。
- IIS Global URI Cache Misses URI 缓存中的未成功查找总数
4.3.2 监控工具
4.3.2.1 集成的性能监视器
在性能监视器里面添加IIS应用计数器即可。
4.4 JVM
4.4.1 监控指标说明
JVM关注的指标主要是java虚拟机内存年轻代、年老代堆大小以及GC频率及回收时间。 JVM堆内存结构如下:
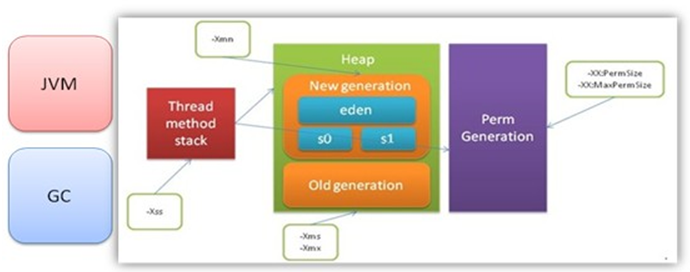
- Young(年轻代) 年轻代分三个区。一个Eden区,两个 Survivor区。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个 Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor区也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空的。
- Tenured(年老代) 年老代存放从年轻代存活的对象。一般来说年老代存放的都是生命期较长的对象。
- Perm(持久代) 用 于存放静态文件,如今Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate等, 在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=进行设置。 发生在年轻代的垃圾回收叫做GC/Minor GC,发生在年老代和永久代的垃圾回收叫做Full GC.
4.4.2 监控工具
4.4.2.1 JVM自带的jstat
- jstat -gc pid 可以显示gc的信息,查看gc的次数,及时间。 其中最后五项,分别是young gc的次数,young gc的时间,full gc的次数,full gc的时间,gc的总时间。
- jstat -gccapacity pid 可以显示,VM内存中三代(young,old,perm)对象的使用和占用大小,如:PGCMN显示的是最小perm的内存使用量,PGCMX显示的是perm的内存最大使用量, PGC是当前新生成的perm内存占用量,PC是但前perm内存占用量。 其他的可以根据这个类推, OC是old内纯的占用量。
- jstat -gcutil pid 统计gc信息统计。
- jstat -gcnew pid 年轻代对象的信息。
- jstat -gcnewcapacity pid 年轻代对象的信息及其占用量。
- jstat -gcold pid old代对象的信息。
- jstat -gcoldcapacity pid old代对象的信息及其占用量。
- jstat -gcpermcapacity pid perm对象的信息及其占用量。
- jstat -class pid 显示加载class的数量,及所占空间等信息。
- jstat -compiler pid 显示VM实时编译的数量等信息。
- jstat -printcompilation pid 当前VM执行的信息。 Jstat显示的信息中一些术语的中文解释:
- S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
- S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
- S0U:年轻代中第一个survivor(幸存区)目前已使用空间 (字节)
- S1U:年轻代中第二个survivor(幸存区)目前已使用空间 (字节)
- EC:年轻代中Eden(伊甸园)的容量 (字节)
- EU:年轻代中Eden(伊甸园)目前已使用空间 (字节)
- OC:Old代的容量 (字节)
- OU:Old代目前已使用空间 (字节)
- PC:Perm(持久代)的容量 (字节)
- PU:Perm(持久代)目前已使用空间 (字节)
- YGC:从应用程序启动到采样时年轻代中gc次数
- YGCT:从应用程序启动到采样时年轻代中gc所用时间(s)
- FGC:从应用程序启动到采样时old代(全gc)gc次数
- FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s)
- GCT:从应用程序启动到采样时gc用的总时间(s)
- NGCMN:年轻代(young)中初始化(最小)的大小 (字节)
- NGCMX:年轻代(young)的最大容量 (字节)
- NGC:年轻代(young)中当前的容量 (字节)
- OGCMN:old代中初始化(最小)的大小 (字节)
- OGCMX:old代的最大容量 (字节)
- OGC:old代当前新生成的容量 (字节)
- PGCMN:perm代中初始化(最小)的大小 (字节)
- PGCMX:perm代的最大容量 (字节)
- PGC:perm代当前新生成的容量 (字节)
- S0:年轻代中第一个survivor(幸存区)已使用的占当前容量百分比
- S1:年轻代中第二个survivor(幸存区)已使用的占当前容量百分比
- E:年轻代中Eden(伊甸园)已使用的占当前容量百分比
- O:old代已使用的占当前容量百分比
- P:perm代已使用的占当前容量百分比
- S0CMX:年轻代中第一个survivor(幸存区)的最大容量 (字节)
- S1CMX :年轻代中第二个survivor(幸存区)的最大容量 (字节)
- ECMX:年轻代中Eden(伊甸园)的最大容量 (字节)
- DSS:当前需要survivor(幸存区)的容量 (字节)(Eden区已满)
- TT: 持有次数限制
- MTT : 最大持有次数限制
4.4.2.2 shell
将jstat中感兴趣的相关指标通过shell保存为文件,例如以下shell是每隔2秒钟将jstat监控的信息保存到文件中。
while true;do /usr/local/java/bin/jstat -gcutil `/usr/local/java/bin/jps | grep -v 'Jps' | grep -v 'Jstat' | egrep 'OrderPlatformLauncher|Bootstrap|TcpServerLauncher'| awk '{print $1}'` | grep -v 'S0' | awk '{print strftime("%m-%d-%H:%M:%S",systime()),$0}';sleep 2;done >> `hostname`_`date +%Y%m%d_%H%M`.jstat
4.4.2.3 jmap
jmap命令可以获得运行中的jvm的堆的快照,从而可以离线分析堆,以检查内存泄漏,检查一些严重影响性能的大对象的创建,检查系统中什么对象最多,各种对象所占内存的大小等等
命令格式 jmap [options] pid -dump:[live,]format=b,file=<filename> --dump堆到文件,live指明是活着的对象,file指定文件名。
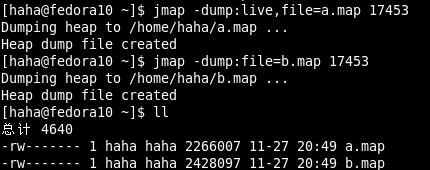
因为在dump:live前会进行full gc,因此不加live的堆大小要大于加live堆的大小 -finalizerinfo 打印等待回收对象的信息
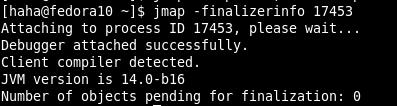
-heap 打印堆总结
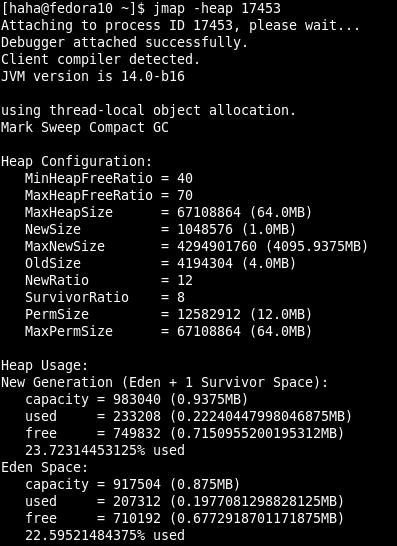
-histo[:live] 打印堆的对象统计,包括对象数、内存大小等等
-permstat 打印java堆perm区的classloader统计
-F 强制,在jmap -dump或jmap -histo中使用,如果pid没有相应的回复 -J 提供jvm选项,如:-J-Xms256m
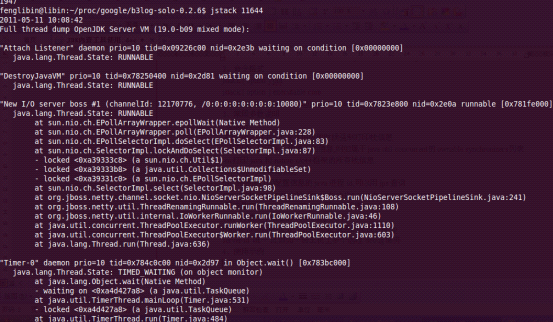
4.4.2.4 jstack
- 介绍 jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息,如果是在64位机器上,需要指定选项"-J-d64",Windows的jstack使用方式只支持以下的这种方式:
jstack [-l] pid
如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而 可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序 的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。 - 命令格式
jstack [ option ] pid
jstack [ option ] executable core
jstack [ option ] [server-id@]remote-hostname-or-IP - 常用参数说明
- options:
executable Java executable from which the core dump was produced.
(可能是产生core dump的java可执行程序)
core 将被打印信息的core dump文件
remote-hostname-or-IP 远程debug服务的主机名或ip
server-id 唯一id,假如一台主机上多个远程debug服务 - 基本参数:
-F当’jstack [-l] pid’没有相应的时候强制打印栈信息
-l长列表. 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表.
-m打印java和native c/c++框架的所有栈信息.
-h | -help打印帮助信息
pid 需要被打印配置信息的java进程id,可以用jps查询. - 使用示例
4.4.2.5 JProfile
JProfile也可以监控JVM,并且以图形化的方式进行展示,方便信息的查看及分析。具体可以参照4.1.2.4章节。
4.4.2.6 JConsole
JConsole也可以监控JVM,并且以图形化的方式进行展示,方便信息的查看及分析。具体可以参照4.1.2.3章节。
4.5 .NET CLR
4.5.1 监控指标说明
.NET CLR是有微软开发的一台虚拟平台,支持C#/C++/VB等,此虚拟平台功能类似于JVM. .NET CLR主要功能如下:
- 平台无关
- 跨语言集成
- 自动内存管理
- 版本控制
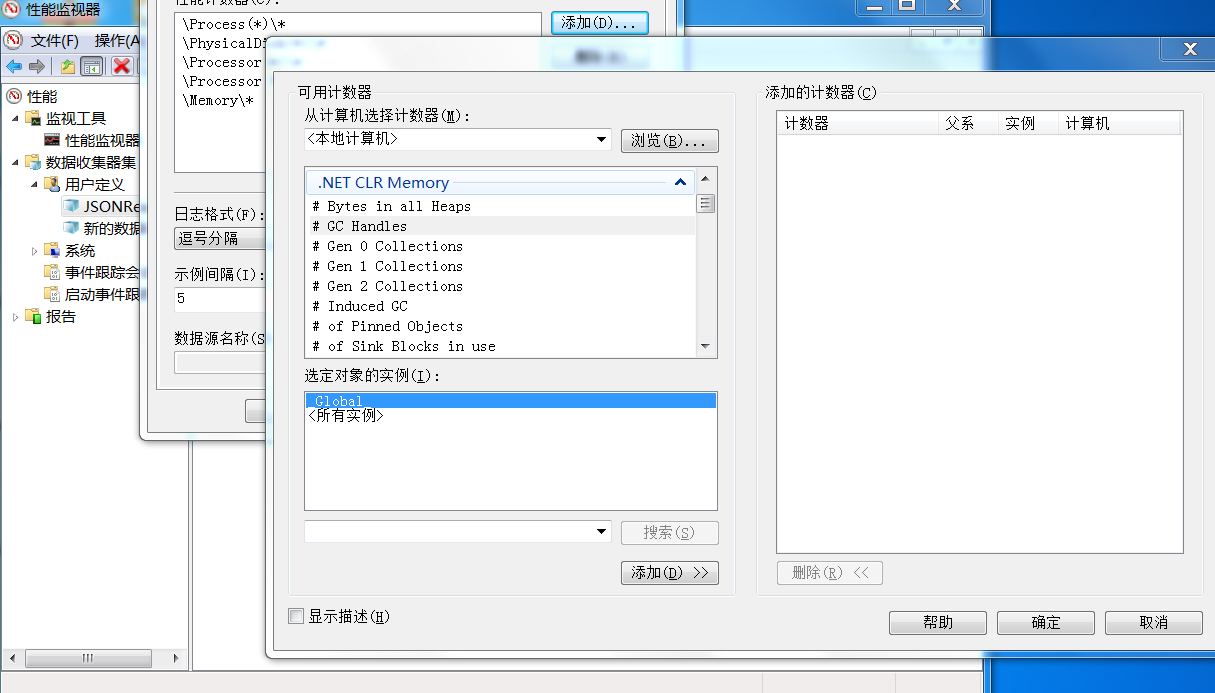
- 安全 .NET CLR Memory计数器如下:
性能计数器 说明
| 指标 | 解释 |
|---|---|
| # Bytes in all Heaps(所有堆中的字节数) | 显示以下计数器值的总和,此计数器指示在垃圾回收堆上分配的当前内存(以字节为单位)。 |
| # GC Handles(GC 处理数目) | 显示正在使用的垃圾回收处理的当前数目。 |
| # Gen 0 Collections(第 2 级回收次数) | 显示自应用程序启动后第 0 级对象(即最年轻、最近分配的对象)被垃圾回收的次数。 |
| # Gen 1 Collections(第 2 级回收次数) | 显示自应用程序启动后对第 1 级对象进行垃圾回收的次数。 |
| # Gen 2 Collections(第 2 级回收次数) | 显示自应用程序启动后对第 2 级对象进行垃圾回收的次数。此计数器在第 2 级垃圾回收(也称作完整垃圾回收)结束时递增。 |
| # Induced GC(引发的 GC 的数目) | 显示由于对 GC.Collect 的显式调用而执行的垃圾回收的峰值次数。让垃圾回收器对其回收的频率进行微调是切实可行的。 |
| # of Pinned Objects(钉住的对象的数目) | 显示上次垃圾回收中遇到的钉住的对象的数目。钉住的对象是垃圾回收器不能移入内存的对象。 |
| # of Sink Blocks in use(正在使用的接收块的数目) | 显示正在使用的同步块的当前数目。同步块是为存储同步信息分配的基于对象的数据结构。 |
| # Total committed Bytes(提交字节的总数) | 显示垃圾回收器当前提交的虚拟内存量(以字节为单位)。提交的内存是在磁盘页面文件中保留的空间的物理内存。 |
| # Total reserved Bytes(保留字节的总数) | 显示垃圾回收器当前保留的虚拟内存量(以字节为单位)。保留内存是为应用程序保留(但尚未使用任何磁盘或主内存页)的虚拟内存空间。 |
| % Time in GC(GC 中时间的百分比) | 显示自上次垃圾回收周期后执行垃圾回收所用运行时间的百分比。 |
| Allocated Bytes/second(每秒分配的字节数) | 显示每秒在垃圾回收堆上分配的字节数。 |
| Finalization Survivors(完成时存留对象数目) | 显示因正等待完成而从回收后保留下来的进行垃圾回收的对象的数目。如果这些对象保留对其他对象的引用,则那些对象也保留下来,但此计数器不对它们计数。 |
| Gen 0 heap size(第 2 级堆大小) | 显示在第 0 级中可以分配的最大字节数;它不指示在第 0 级中当前分配的字节数。 |
| Gen 0 Promoted Bytes/Sec(从第 1 级提升的字节数/秒) | 显示每秒从第 0 级提升到第 1 级的字节数。内存在从垃圾回收保留下来后被提升。 |
| Gen 1 heap size(第 2 级堆大小) | 显示第 1 级中的当前字节数;此计数器不显示第 1 级的最大大小。 |
| Gen 1 Promoted Bytes/Sec(从第 1 级提升的字节数/秒) | 显示每秒从第 1 级提升到第 2 级的字节数。在此计数器中不包括只因正等待完成而被提升的对象。 |
| Gen 2 heap size(第 2 级堆大小) | 显示第 2 级中当前字节数。不直接在此代中分配对。 |
| Large Object Heap size(大对象堆大小) | 显示大对象堆的当前大小(以字节为单位)。垃圾回收器将大于 20 KB 的对象视作大对象并且直接在特殊堆中分配大对象; |
| Promoted Finalization-Memory from Gen 0(从第 1 级提升的完成内存) | 显示只因等待完成而从第 0 级提升到第 1 级的内存的字节数。 |
| Promoted Finalization-Memory from Gen 1(从第 1 级提升的完成内存) | 显示只因等待完成而从第 1 级提升到第 2 级的内存的字节数。 |
| Promoted Memory from Gen 0(从第 1 级提升的内存) | 显示在垃圾回收后保留下来并且从第 0 级提升到第 1 级的内存的字节数。 |
| Promoted Memory from Gen 1(从第 1 级提升的内存) | 显示在垃圾回收后保留下来并且从第 1 级提升到第 2 级的内存的字节数。 |
4.5.2 监控工具
4.5.2.1 集成的性能监视器
Windows性能监视器中,可以将.NET CLR Memory中相关的计数器加入到监控中。
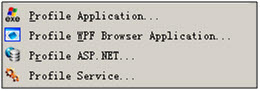
4.5.2.2 .NET Memory Profiler
Profiler可以调试4种类型的.NET程序,分别为:
- 桌面应用程序
- WPF程序
- ASP.NET程序
- .NET Service程序 对应选择软件的文件菜单如下
Profler调试共有三种方式选择:
- 启动跟踪(Profiler Application)
选定对应的调试方式,如调试桌面程序,选中Profiler Application,然后选择需要启动的执行文件,Profiler将作为宿主程序启动程序开始实时监控内存. - 附加进程(Attach Process)
将Profiler附加到指定的进程上,此时不能实时监控内存情况,只能够收集内存镜像. - 导入内存镜像(Import Memory Dump)
可以选择dmp为后缀的内存镜像文件,比如Windbg以及DebugDiag导出的镜像文件,此时不能实时监控内存情况,只能够收集内存镜像且不能跟踪非托管资源.
具体操作如下: - 启动程序
首先,选择需要调试类型,选择 Profiler Application,选择好需要启动的程序exe文件.
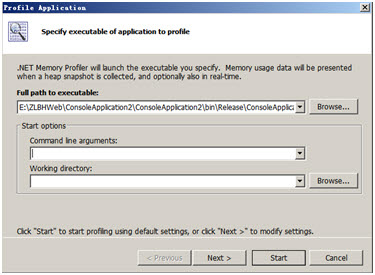
如果需要设置启动参数,则设置好命令行参数以及工作目录.
选择”Next”进行收集数据的一些选项设置,一般直接按”Star”按钮开始调试程序.
- 收集数据
选择菜单栏的收集按钮,收集堆数据,第一个为收集全部堆上的数据,第二个为只收集第0代的数据.

- 重新启动和停止
调试完毕后通过停止按钮跟踪程序,通过启动按钮重新启动上一次的调试程序. -
查看收集数据
Profiler上有6个页卡,分别为: -
Type/Resource 类型/资源页卡
- Type/Resource Details类型/资源明细页卡
- Instance Details 实例明细页卡
- Call Stacks/Methods调用堆栈页卡
- Navtive Memory 本地内存页卡
- Real-Time-实时跟踪页卡
5 数据库指标监控
5.1 MySQL
5.1.1 监控指标说明
主要针对SQL耗时、吞吐量(QPS/TPS)、命中率、锁等待等指标进行监控。
5.1.2 监控工具
5.1.2.1 命令
- 效率低下SQL
mysqldumpslow -s at -t 20 host-slow.log - #mysql qps查询 QPS = Questions(or Queries) / Seconds
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL / STATUS LIKE "Questions"'
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL / STATUS LIKE "Queries"' - #mysql Key Buffer 命中率
key_buffer_read_hits = (1 - Key_reads / Key_read_requests) 100% key_buffer_write_hits= (1 - Key_writes / Key_write_requests) 100%
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL / STATUS LIKE "Key%"' - #mysql Innodb Buffer 命中率
innodb_buffer_read_hits=(1-Innodb_buffer_pool_reads/ Innodb_buffer_pool_read_requests) 100%
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL */ STATUS LIKE "Innodb_buffer_pool_read%"' - #mysql Query Cache 命中率
Query_cache_hits= (Qcache_hits / (Qcache_hits + Qcache_inserts)) 100%
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL */ STATUS LIKE "Qcache%"' - #mysql Table Cache 状态量
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL / STATUS LIKE "Open%"' - #mysql Thread Cache 命中率
Thread_cache_hits = (1 - Threads_created / Connections) 100% 正常来说,Thread Cache 命中率要在 90% 以上才算比较合理。
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL */ STATUS LIKE "Thread%"' - #mysql 锁定状态
锁定状态包括表锁和行锁两种,我们可以通过系统状态变量获得锁定总次数,锁定造成其他线程等待的次数,以及锁定等待时间信息
mysql -u root -p123456 -e 'SHOW /!50000 GLOBAL / STATUS LIKE "%lock%"'
5.1.2.2 iDBCloud
- 在阿里云RDS管理控制台,点击登陆数据库

- 输入实例名、用户名和密码
- 点击实例性能
- 点击实例性能
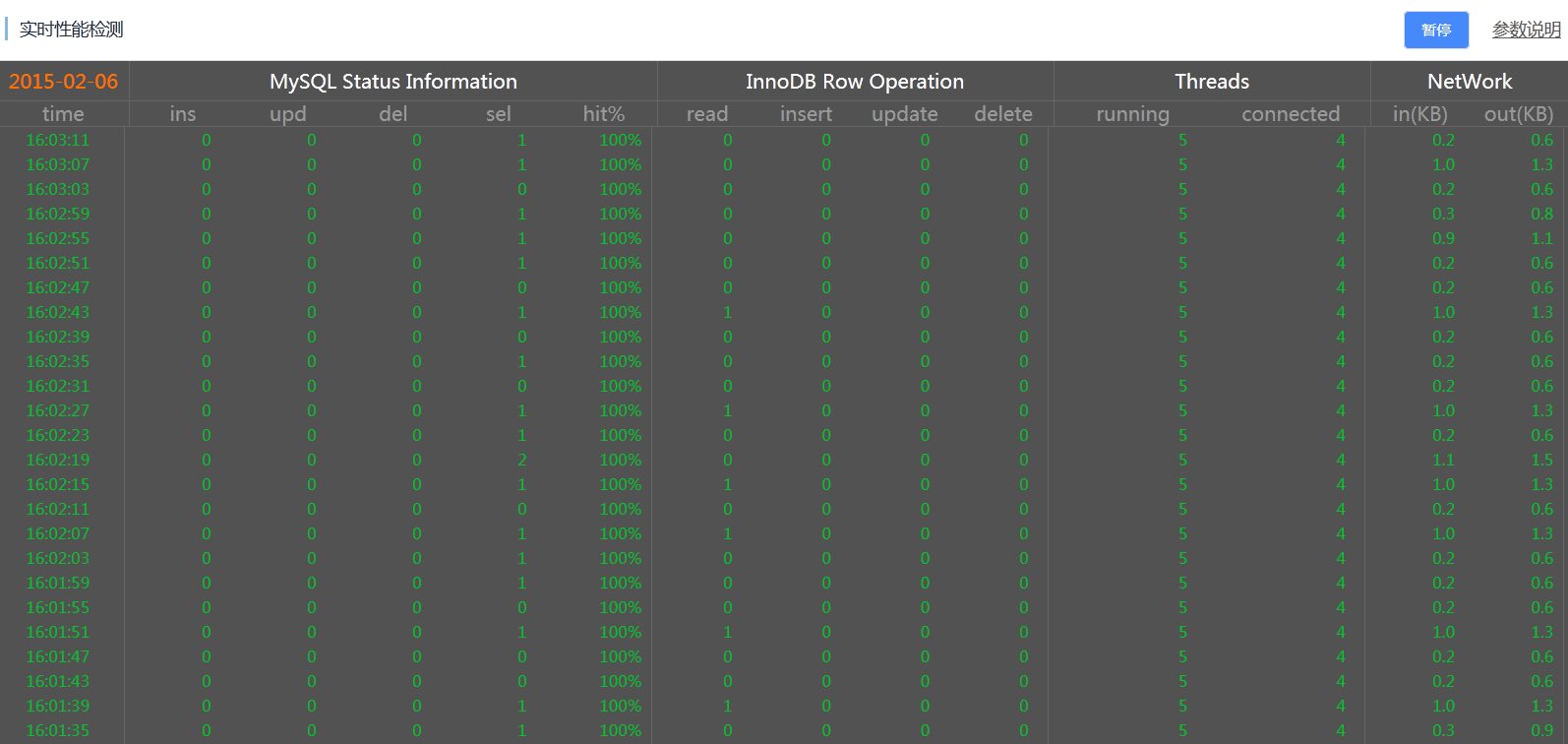
MySQL Status Inoformation : MySQL状态信息
【ins】表示insert语句每秒执行次数
【upd】表示update语句每秒执行次数
【del】表示delete语句每秒执行次数
【sel】表示select语句每秒执行次数
【hit%】表示缓存命中率,主要指innodb_buffer_pool的命中率
InnoDB Row Operation : InnoDB存储引擎行操作
【read】表示InnoDB存储引擎表的读取记录行数
【insert】表示InnoDB存储引擎表的写入记录行数
【update】表示InnoDB存储引擎表的更新记录行数
【delete】表示InnoDB存储引擎表的写入记录行数
Thread : 连接数相关
【running】表示活跃的连接数,即正在执行sql的连接
【connected】表示连接在实例上的空闲连接,即未执行sql的连接
Network : 网络流量,单位为KB
【in】表示进入实例的网络流量
【out】表示流出实例的网络流量
5.1.2.3 PHPMyAdmin
phpMyAdmin是Mysql的管理工具。相比一些Mysql客户端的GUI管理工具(如“MySQL Administrator”),phpMyAdmin是Web模式的。phpMyAdmin 是以PHP为基础,以Web-Base方式架构在网站主机上的MySQL的资料库管理工具。
在phpMyAdmin直接点击状态,可以查看SQL查询,InnoDB,Cache,线程等状态信息。
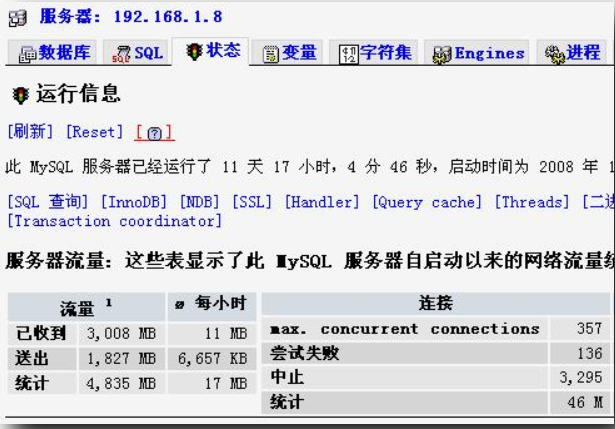
5.1.2.4 性能测试
通过性能测试RDS监控,可以监控当前活跃连接数、IOPS、TPS、磁盘容量、QPS。
5.2 SQLServer
5.2.1 监控指标说明
| 监控项 | 解释 |
|---|---|
| 连接数 | 当前总连接数 |
| 缓存命中率 | 缓存命中率 |
| 平均每秒全表扫描数 | 平均每秒全表扫描次数 |
| 每秒SQL编译 | 实例中每秒编译的SQL语句数 |
| 每秒检查点写入Page数 | 每秒检查点写入Page数 |
| 每秒登录次数 | 每秒登录次数 |
| 每秒锁超时次数 | 每秒锁超时次数 |
| 每秒死锁次数 | 每秒死锁次数 |
| 每秒锁等待次数 | 每秒锁等待次数 |
| 网络流量 | SQL Server实例平均每秒钟输入和输出的流量。单位为KB。 |
| QPS/TPS | 平均每秒SQL语句执行次数和事务数。 |
| CPU使用率 | RDS实例CPU使用率(占操作系统总数) |
| IOPS | RDS实例的IOPS(每秒IO请求次数) |
| 磁盘空间 | RDS实例空间占用 |
5.2.2 监控工具
5.2.2.1 SQLServer活动监视器
SQL Server 数据库提供了专门的工具对数据库的活动进行监控,这个工具称为“活动监视器”。使用活动监视器可以获取与数据库引擎相关的用户连接状态及其所保存的锁等有用信息。
- 打开活动监视器
- 打开SQL Server Management Studio并连接到数据库引擎服务器。
- 在“对象资源管理器”窗口中,展开“管理”节点。
- 双击“活动监视器”节点,打开“活动监视器”对话框,如图1所示。
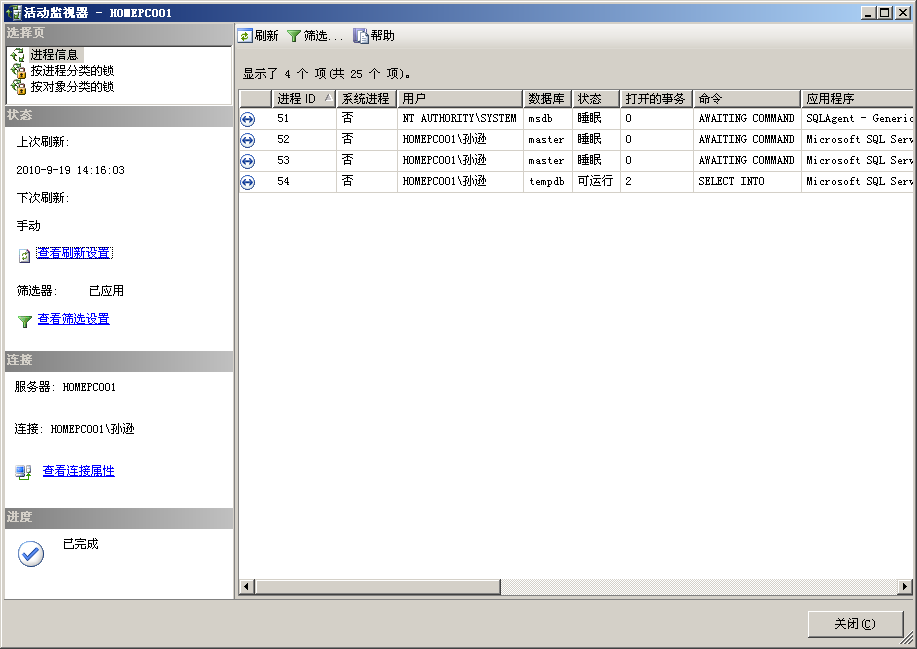
该“活动监视器”对话框包含3组选项,分别是“进程信息”选项、“按进程分类的锁”选项和“按对象分类的锁”选项。
“进程信息”选项:包含有关连接到数据库的信息
“按进程分类的锁”选项:显示按连接对锁进行排序
“按对象分类的锁”选项:显示按对象名称对锁进行排序
- 查看当前进程的属性
用户可以使用“进程信息”选项:查看当前进程的属性。
用户可以通过对话框顶部的“筛选器”按钮,打开“筛选设置”对话框,如图2所示。
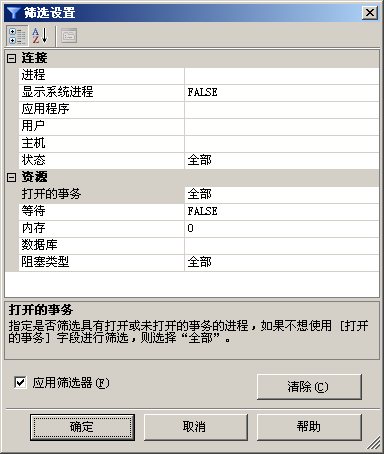
应用筛选器可以减少显示的信息量。对数据库锁定问题进行故障排除时,可以使用“活动监视器”终止死锁或无响应的进程。
- 查看某一个进程的详细信息
若要查看某一个进程的详细信息,可以右击某一进程,在弹出的快捷菜单中选择“详细信息”命令,打开“进程详细信息”对话框。
5.2.2.2 SQLServer Profile
SQL Server Profiler(事件探查器)是SQL跟踪的图形用户界面,用于监视SQL Server 数据库引擎或SQL Server Analysis Services(分析服务)的实例。用户可以捕获有关每个事件的数据,并将其保存到文件或表中供以后分析。
- 创建跟踪
用户可以使用SQL Server Profiler工具创建跟踪,具体过程如下: - 依次选择“开始”|“所有程序”|“Microsoft SQL Server”|“性能工具”|“SQL Server Profiler”,打开事件探查器。
- 打开“文件”菜单,选择“新建跟踪”命令,并连接到SQL Server实例。此时,将显示“跟踪属性”对话框,如图所示:
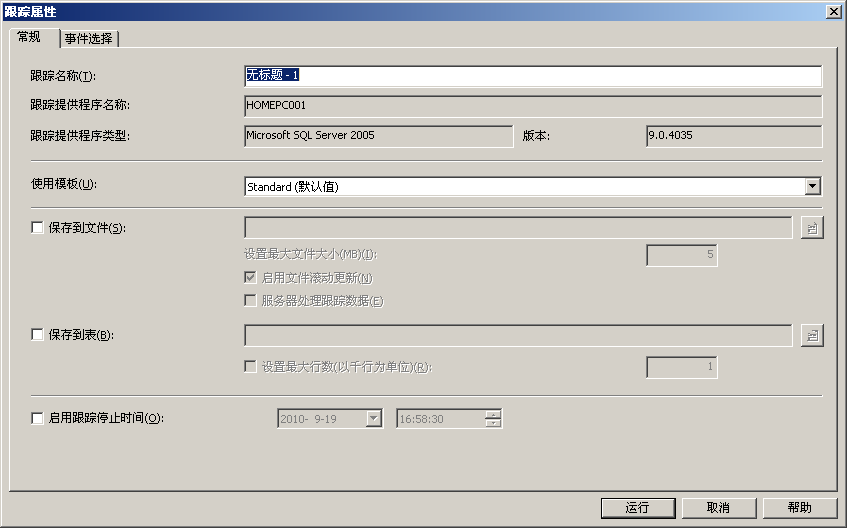
- 在“跟踪名称”文本框中输入跟踪的名称。在“使用模板”下拉列表框中,为此跟踪选择一个跟踪模板。如果不想使用模板,则选择“空白”选项。
- 设置全局跟踪选项 用户可以设置应用于SQL Server 2005 Profiler的全局选项,具体操作如下:
- 依次选择“开始”|“所有程序”|“Microsoft SQL Server 2005”|“性能工具”|“SQL Server Profiler”,打开事件探查器。
- 依次选择“工具”|“选项”命令,打开“常规选项”对话框,如图所示:
- 指定跟踪文件的事件和数据列
用户可以使用SQL Server Profiler指定跟踪的事件类和数据列,具体操作过程如下: - 依次选择“开始”|“所有程序”|“Microsoft SQL Server”|“性能工具”|“SQL Server Profiler”,打开事件探查器。
- 依次选择“文件”|“新建跟踪”命令,或者在正在运行跟踪时,选择“文件”|“属性”命令,打开“跟踪属性”选项卡。
- 选择“事件选择”选项卡,如图所示:
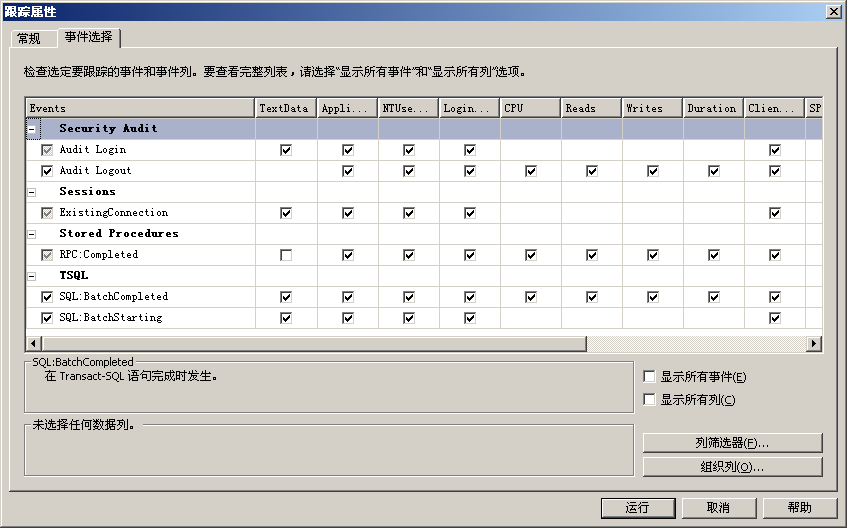
“事件选项”选项卡包含一个网格控件,网格控件是包含所有可跟踪事件类的表。每个事件类在表中占一行。根据用户所连接的服务器的类型和版本的不同,事件类会略有不同。事件类是由网格的“Events”列进行标识,并按事件类别进行分组。其余列则列出每个事件类可以返回的数据列。
- 将跟踪结果保存到表
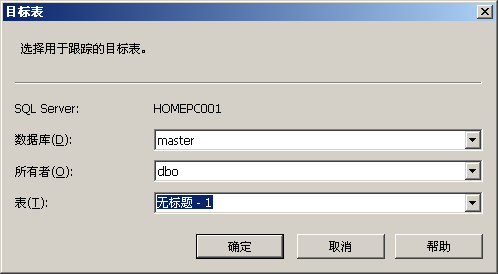
用户可以使用SQL Server Profiler将跟踪结果保存到数据库表,具体操作过程如下:
依次选择“开始”|“所有程序”|“Microsoft SQL Server ”|“性能工具”|“SQL Server Profiler”,打开事件探查器。在“文件”菜单上,选择“新建跟踪”命令,并连接到SQL Server实例。此时,将显示“跟踪属性”对话框。输入跟踪的名称,然后选中“保存到表”复选框。弹出“连接到服务器”对话框,连接到将包含跟踪表的SQL Server 2005数据库服务器实例。在“目标表”对话框中,从“数据库”列表中选择相应的数据库,所有者,输入表的名称,如图所示:
完成设置后,单击“确定”按钮,返回“跟踪属性”对话框。
5.2.2.3 性能监视器
系统性能监视器可以用于监视系统资源的使用率。它使用计数器形式收集和查看服务器资源(如处理器和内存使用的情况)和许多SQL Server 2005资源(如锁和事务)的实时性能数据。
- 运行系统性能监视器
系统监视器使用远程过程调用从SQL Server 2005收集信息。拥有运行系统监视器的Windows权限的任何用户都可以使用系统监视器来监视SQL Server 2005。与所有性能监视器工具一样,使用系统监视器监视SQL Server 2005时,性能方面会受到一些影响。特定实例中的实际影响取决于硬件平台、计数器数量以及所选更新间隔。但是,将系统监视器与SQL Server 2005集成可以尽量减少对性能的影响。 - SQL Server 2005性能对象
SQL Server 2005数据库提供了一组针对性能的数据对象,供用户监视SQL Server 2005时使用。当监视SQL Server 2005和Windows操作系统以调查与性能有关的问题时,请关注3个主要方面:磁盘活动、处理器使用率和内存使用量。这些性能对象在系统的“性能监视器”工具的“添加计数器”对话框的“性能对象”下拉列表框中可以找到。
5.2.2.4 iDBCloud
参照5.1.2.2 iDBCloud.
5.3 MonogoDB
5.3.1 监控指标说明
主要监控如下指标:
- inserts/s 每秒插入次数
- query/s 每秒查询次数
- update/s 每秒更新次数
- delete/s 每秒删除次数
- getmore/s 每秒执行getmore次数
- command/s 每秒的命令数,比以上插入、查找、更新、删除的综合还多,还统计了别的命令
- flushs/s 每秒执行fsync将数据写入硬盘的次数。
- mapped/s 所有的被mmap的数据量,单位是MB,
- vsize 虚拟内存使用量,单位MB
- res 物理内存使用量,单位MB
- faults/s 每秒访问失败数(只有Linux有),数据被交换出物理内存,放到swap。不要超过100,否则就是机器内存太小,造成频繁swap写入。此时要升级内存或者扩展
- locked % 被锁的时间百分比,尽量控制在50%以下吧
- idx miss % 索引不命中所占百分比。如果太高的话就要考虑索引是不是少了
- q t|r|w 当Mongodb接收到太多的命令而数据库被锁住无法执行完成,它会将命令加入队列。这一栏显示了总共、读、写3个队列的长度,都为0的话表示mongo毫无压力。高并发时,一般队列值会升高。
- 慢查,效率低下的查询
5.3.2 监控工具
5.3.2.1 MonogoStat命令
mongostat是mongdb自带的状态检测工具,在命令行下使用。它会间隔固定时间获取mongodb的当前运行状态,并输出。如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用mongostat来查看mongo的状态。
5.3.2.2 Profiler
类似于MySQL的slow log, MongoDB可以监控所有慢的以及不慢的查询。
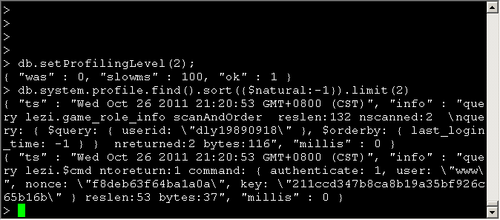
Profiler默认是关闭的,你可以选择全部开启,或者有慢查询的时候开启。 例如:
> use test
switched to db test
> db.setProfilingLevel(2);
{"was" : 0 , "slowms" : 100, "ok" : 1} // "was" is the old setting
> db.getProfilingLevel()
查看Profiler日志:
> db.system.profile.find().sort({$natural:-1})
{"ts" : "Thu Jan 29 2009 15:19:32 GMT-0500 (EST)" , "info" :
"query test.$cmd ntoreturn:1 reslen:66 nscanned:0 query: { profile: 2 } nreturned:1 bytes:50" ,
"millis" : 0} ...
3个字段的意义ts:时间戳、info:具体的操作、millis:操作所花时间,毫秒。
5.3.2.3 使用profiler
类似于MySQL的slow log, MongoDB可以监控所有慢的以及不慢的查询。
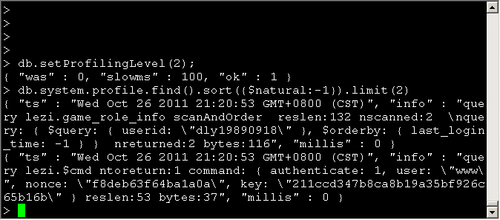
Profiler默认是关闭的,你可以选择全部开启,或者有慢查询的时候开启。
> use test
switched to db test
> db.setProfilingLevel(2);
{"was" : 0 , "slowms" : 100, "ok" : 1} // "was" is the old setting
> db.getProfilingLevel()
查看Profile日志
> db.system.profile.find().sort({$natural:-1})
{"ts" : "Thu Jan 29 2009 15:19:32 GMT-0500 (EST)" , "info" :
"query test.$cmd ntoreturn:1 reslen:66 nscanned:0 query: { profile: 2 } nreturned:1 bytes:50" ,
"millis" : 0} ...
3个字段的意义ts:时间戳、info:具体的操作、millis:操作所花时间,毫秒
注意,造成慢查询可能是索引的问题,也可能是数据不在内存造成因此磁盘读入造成。
5.3.2.4 使用Web控制台
Mongodb自带了Web控制台,默认和数据服务一同开启。他的端口在Mongodb数据库服务器端口的基础上加1000,如果是默认的Mongodb数据服务端口(Which is 27017),则相应的Web端口为28017
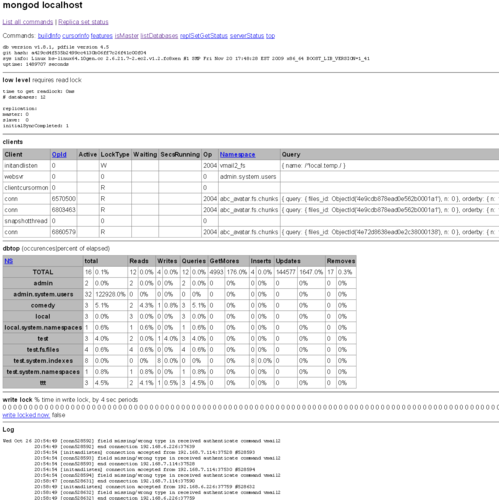
这个页面可以看到
- 当前Mongodb的所有连接
- 各个数据库和Collection的访问统计,包括:Reads, Writes, Queries, GetMores ,Inserts, Updates, Removes
- 写锁的状态
- 以及日志文件的最后几百行(CentOS+10gen yum 安装的mongodb默认的日志文件位于/var/log/mongo/mongod.log)
5.3.2.5 MongoDB Monitoring Service
MongoDB Monitoring Service(MMS)是Mongodb厂商提供的监控服务,可以在网页和Android客户端上监控你的MongoDB状况。
5.4 Redis
5.4.1 监控指标说明
Redis主要监空Server、Clients、Memory、Persistence、Stats、Replication、CPU、Keyspace 8大部分,具体如下:
-
Server
redis_version:2.8.8 # Redis 的版本
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:bf5d1747be5380f
redis_mode:standalone
os:Linux 2.6.32-220.7.1.el6.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
gcc_version:4.4.7 #gcc版本
process_id:49324 # 当前 Redis 服务器进程id
run_id:bbd7b17efcf108fdde285d8987e50392f6a38f48
tcp_port:6379
uptime_in_seconds:1739082 # 运行时间(秒)
uptime_in_days:20 # 运行时间(天)
hz:10
lru_clock:1734729
config_file:/home/s/apps/RedisMulti_video_so/conf/zzz.conf -
Clients
connected_clients:1 #连接的客户端数量
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0 -
Memory
used_memory:821848 #Redis分配的内存总量
used_memory_human:802.59K
used_memory_rss:85532672 #Redis分配的内存总量(包括内存碎片)
used_memory_peak:178987632
used_memory_peak_human:170.70M #Redis所用内存的高峰值
used_memory_lua:33792
mem_fragmentation_ratio:104.07 #内存碎片比率
mem_allocator:tcmalloc-2.0 -
Persistence
loading:0
rdb_changes_since_last_save:0 #上次保存数据库之后,执行命令的次数
rdb_bgsave_in_progress:0 #后台进行中的 save 操作的数量
rdb_last_save_time:1410848505 #最后一次成功保存的时间点, rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
aof_enabled:0 #redis是否开启了aof
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok -
Stats
total_connections_received:5705 #运行以来连接过的客户端的总数量
total_commands_processed:204013 #运行以来执行过的命令的总数量
instantaneous_ops_per_sec:0
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:34401 #运行以来过期的 key 的数量
evicted_keys:0 #运行以来删除过的key的数量
keyspace_hits:2129 #命中key 的次数
keyspace_misses:3148 #没命中key 的次数
pubsub_channels:0 #当前使用中的频道数量
pubsub_patterns:0 #当前使用中的模式数量
latest_fork_usec:4391 -
Replication
role:master #当前实例的角色master还是slave
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0 -
CPU
used_cpu_sys:1551.61
used_cpu_user:1083.37
used_cpu_sys_children:2.52
used_cpu_user_children:16.79 -
Keyspace
db0:keys=3,expires=0,avg_ttl=0 #各个数据库的 key 的数量及生存周期
5.4.2 监控工具
5.4.2.1 redis-faina
使用redis自带命令monitor的输出结果做分析的python脚本,在命令行下使用,可以做实时分析使用。 官网:https://github.com/Instagram/redis-faina
cd /opt/test
git clone https://github.com/Instagram/redis-faina.git
cd redis-faina/
redis-cli -p 6379 MONITOR | head -n 100 | ./redis-faina.py --redis-version=2.4
测试结果如下:
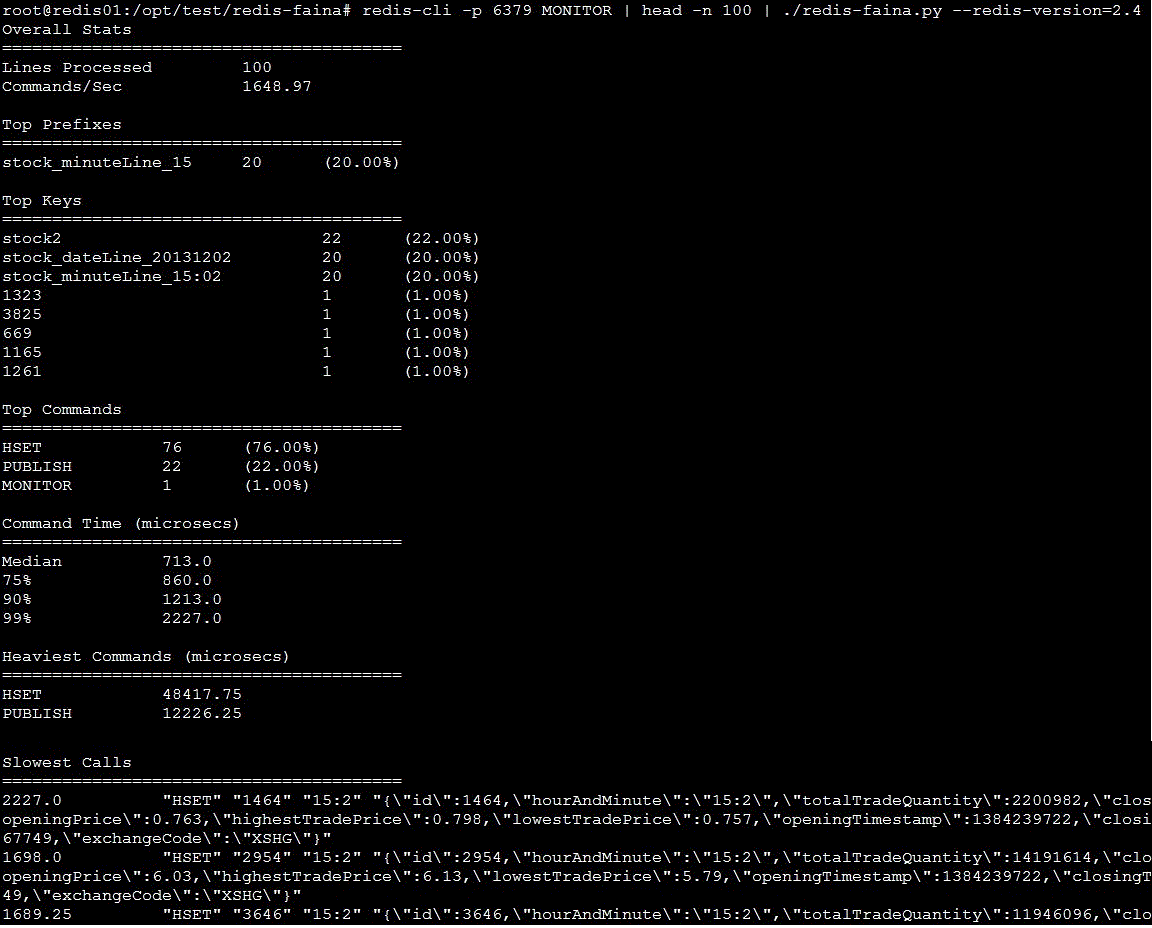
可以看到一些实时的数据,并且有一定的统计数据,可以作为一个命令行工具使用。推荐使用,不过redis版本要大于2.4。
5.4.2.2 redis-live
用来监控redis实例,分析查询语句并且有web界面的监控工具,python编写。 官网:https://github.com/nkrode/RedisLive 运行环境依赖包安装:http://www.nkrode.com/article/real-time-dashboard-for-redis redis-live安装:
cd /root
git clone https://github.com/nkrode/RedisLive.git
cd RedisLive/src ###修改redis-live.conf文件 {
"RedisServers": [ {
"server": "10.20.111.188",
"port" : 6379
} ],
"DataStoreType" : "redis", "RedisStatsServer":
{
"server" : "10.20.111.188",
"port" : 6380},
"SqliteStatsStore" :
{
"path": "to your sql lite file"
} }
修改完毕
启动监控服务,每30秒监控一次 ./redis-monitor.py --duration=30 ###再次开启一个终端,进入/root/RedisLive/src目录,启动web服务 ./redis-live.py 在浏览器输入: http://10.20.111.188:8888/index.html 即可看到下图:
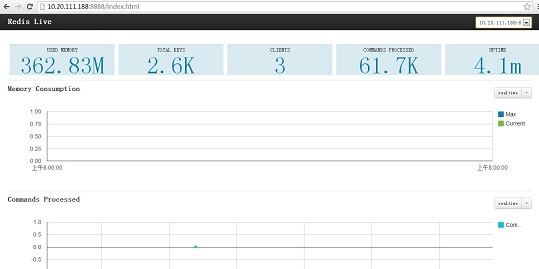
一个web界面,可以同时监控多个redis实例,做集中监控比较好。
5.4.2.3 redis-stat
用ruby写成的监控redis的程序,基于info命令获取信息,而不是通过monitor获取信息,性能应该比monitor要好。
官网:https://github.com/junegunn/redis-stat
运行环境安装:
apt-get install ruby
apt-get install rubygems
redis-stat安装:
cd /root
git clone https://github.com/junegunn/redis-stat.git
cd /root/redis-stat/bin ###./redis-stat --help 可以看到使用帮助
./redis-stat 1
redis-stat的具体用法
usage: redis-stat [HOST[:PORT] ...] [INTERVAL [COUNT]]
-a, --auth=PASSWORD Password
-v, --verbose Show more info
--style=STYLE Output style: unicode|ascii
--no-color Suppress ANSI color codes
--csv=OUTPUT_CSV_FILE_PATH Save the result in CSV format
--server[=PORT] Launch redis-stat web server (default port: 63790)
--daemo Daemonize redis-stat. Must used with --server option.
--version Show version --help
redis-stat命令行模式:
redis-stat
redis-stat 1
redis-stat 1 10
redis-stat --verbose
redis-stat localhost:6380 1 10
redis-stat localhost localhost:6380 localhost:6381 5
redis-stat localhost localhost:6380 1 10 --csv=/tmp/output.csv --verbose
redis-stat web模式:
redis-stat --server
redis-stat --verbose --server=8080 5
redis-stat --server --daemon
效果如下:
运行web模式
cd /root/redis-stat/bin
./redis-stat --server=8080 5 --daemon
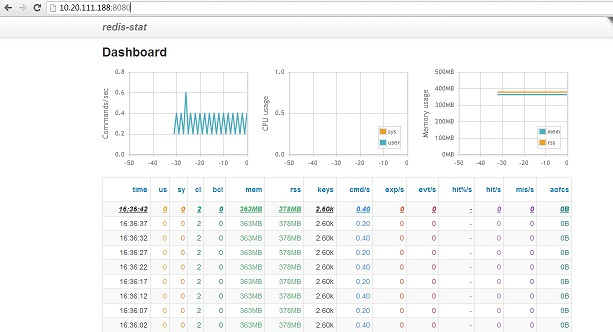
在浏览器输入: http://10.20.111.188:8080/ 结果如下:
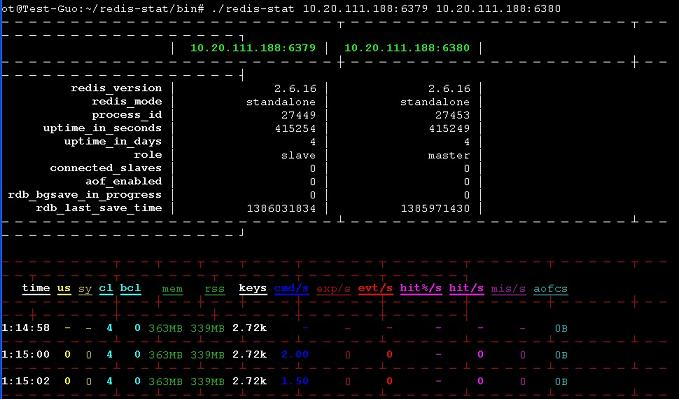
不错的工具,既有命令行又有web界面,可以放到后台运行,数据比redis-live感觉直观 ,ruby开发的,唯一的缺点是如果同时监控多个redis实例,不能单独显示每一个实例的数据信息,貌似是总和。
5.4.2.4 redis-monitor
一个国人用java写的,官网的是在win下编译的,看着不错,官网:https://github.com/litiebiao2012/redis-monitor,个人感觉,做集中监控可以使用redis-live,在命令行使用可以使用redis-stat,也可以根据自己的情况自行编写,总之就是根据info和monitor命令获取并展示信息。
6 前端指标监控
6.1 监控指标说明
前端指标主要包括页面展示、网络所花的时间以及前端有哪些地方需要优化。
6.2 监控工具
6.2.1 FireBug
Firebug是firefox下的一个扩展,能够调试所有网站语言,如Html,Css等,但FireBug最吸引我的就是javascript调试功能,使用起来非常方便,而且在各种浏览器下都能使用(IE,Firefox,Opera, Safari)。
Firebug主要功能有:CSS调试、CSS尺标、网络监视器、JS调试器、Console 控制台、修改HTML、DOM查看器。
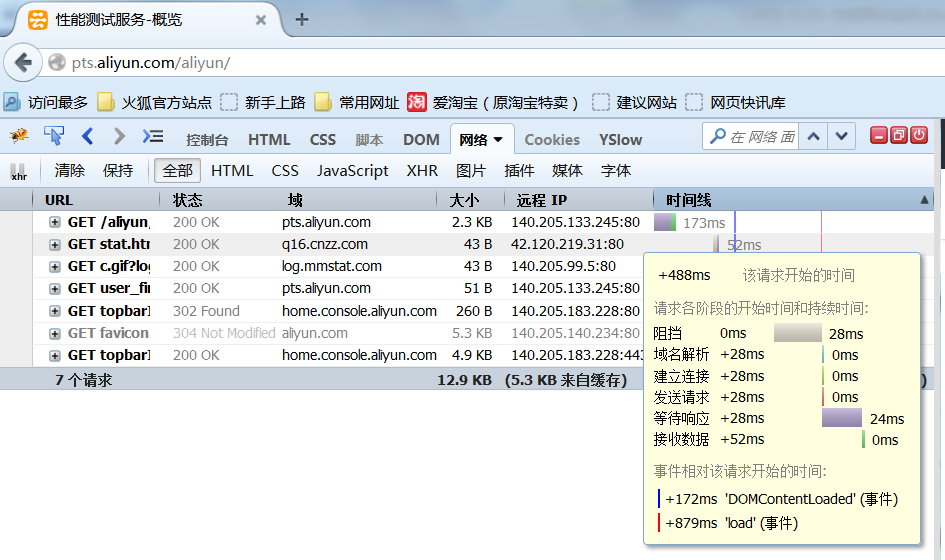
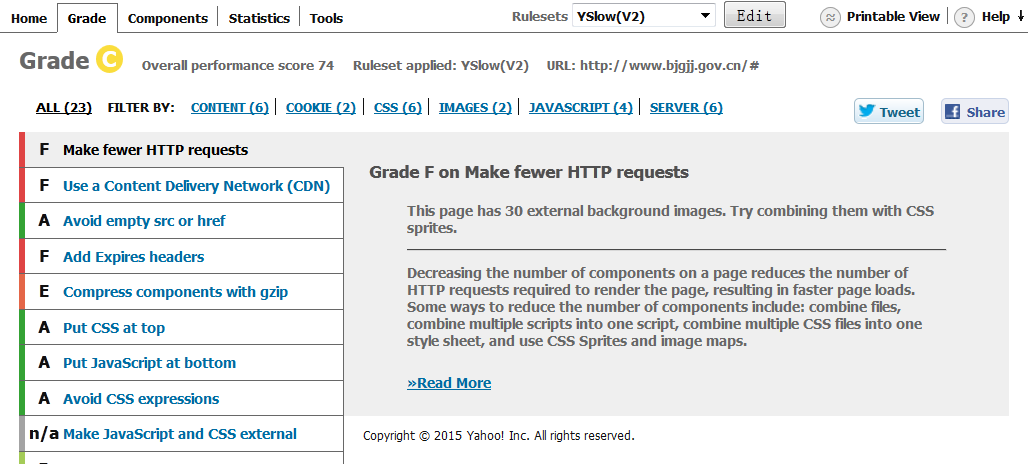
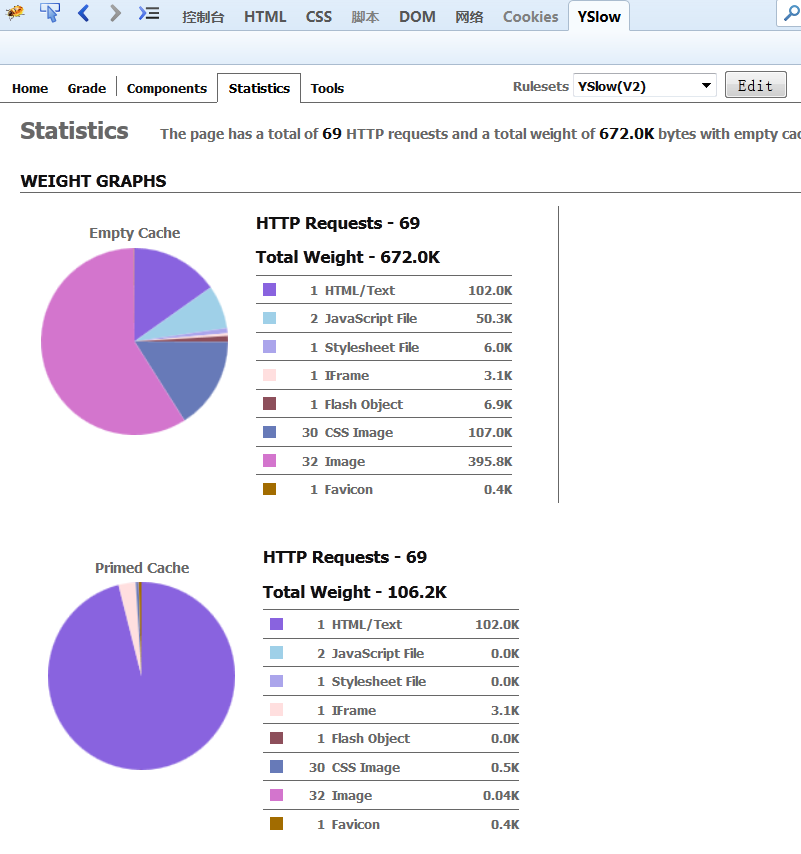
6.2.2 YSlow
YSlow可以对网站的页面进行分析,并告诉你为了提高网站性能,如何基于某些规则而进行优化。 安装YSlow必须首先先安装 Firebug,然后下载YSlow,再对其安装。
YSlow可以分析任何网站,并为每一个规则产生一个整体报告,如果页面可以进行优化,则YSlow会列出具体的修改意见。