Deep Reinforcement Learning Based Trading Application at JP Morgan Chase
https://medium.com/@ranko.mosic/reinforcement-learning-based-trading-application-at-jp-morgan-chase-f829b8ec54f2
FT released a story today about the new application that will optimize JP Morgan Chase trade execution ( Business Insider article on the same topic for readers that do not have FT subscription ). The intent is to reduce market impact and provide best trade execution results for large orders.
It is a complex application with many moving parts:
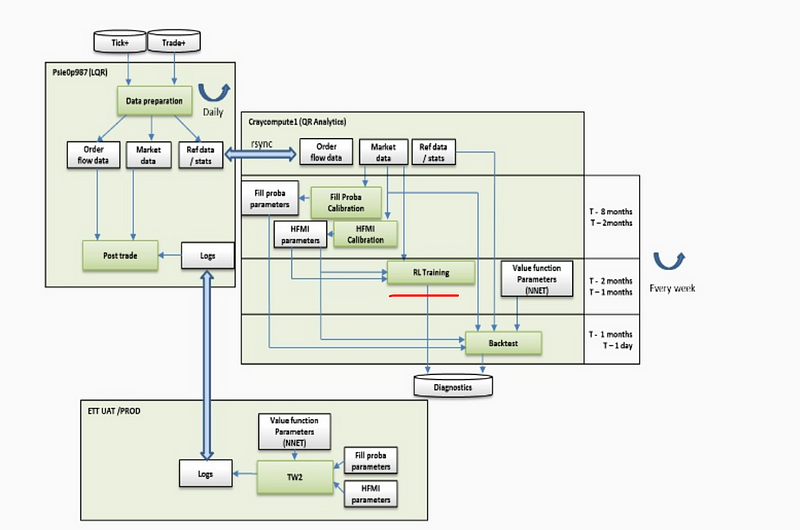
Its core is an RL algorithm that learns to perform the best action ( choose optimal price, duration and order size ) based on market conditions. It is not clear if it is Sarsa ( On-Policy TD Control) or Q-learning (Off-Policy Temporal Difference Control Algorithm ) as both algorithms are present in JP Morgan slides:
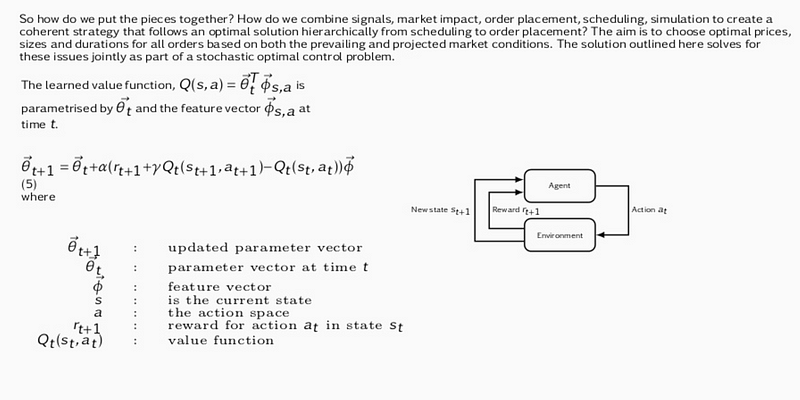
Sarsa

Q-learning
State consists of price series, expected spread cost, fill probability, size placed, as well as elapsed time, %progress, etc. Rewards are immediate rewards ( price spread ) and terminal ( end of episode ) rewards like completion, order duration and market penalties ( obviously those are negative rewards that punish the agent along these dimensions ).
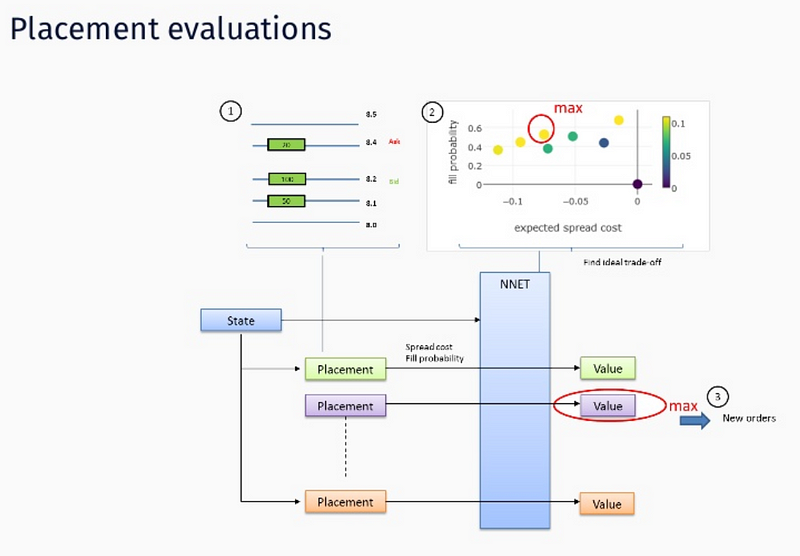
Actions are memorized as weights of a Deep Neural Network — function approximation via NN is used since state, action space is too big to be handled in tabular form. We assume stochastic gradient descent is used for both feed forward and backprop operation operation ( hence Deep designation ):
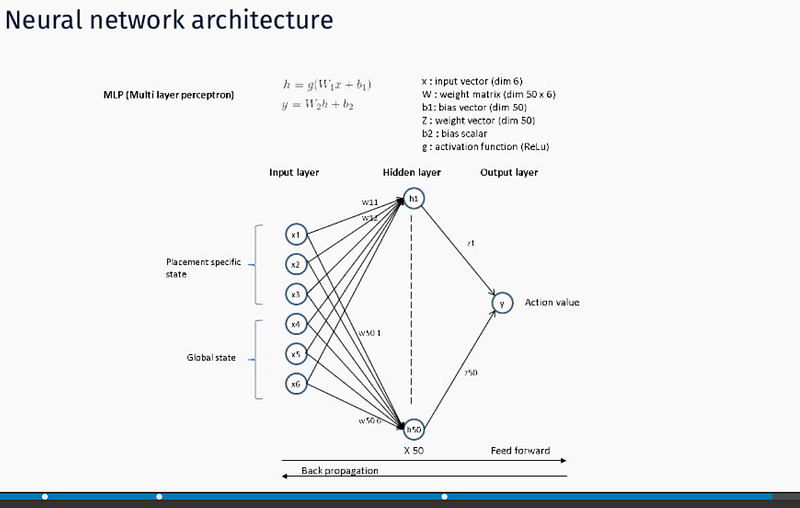
JP Morgan is convinced this is the very first real time trading AI/ML application on Wall Street. We are assuming this is not true i.e. there are surely other players operating in this space as RL implementation to order execution is known for quite a while now ( Kearns and Nevmyvaka 2006 ).
The latest LOXM developments will be presented at QuantMinds Conference in Lisbon (May of 2018).
Instinet is also using Q-learning, probably for the same purpose ( market impact reduction ).