一 Hive SQL练习之影评案例
案例说明
现有如此三份数据:
1、users.dat 数据格式为: 2::M::56::16::70072,
共有6040条数据
对应字段为:UserID BigInt, Gender String, Age Int, Occupation String, Zipcode String
对应字段中文解释:用户id,性别,年龄,职业,邮政编码
2、movies.dat 数据格式为: 2::Jumanji (1995)::Adventure|Children's|Fantasy,
共有3883条数据
对应字段为:MovieID BigInt, Title String, Genres String
对应字段中文解释:电影ID,电影名字,电影类型
3、ratings.dat 数据格式为: 1::1193::5::978300760,
共有1000209条数据
对应字段为:UserID BigInt, MovieID BigInt, Rating Double, Timestamped String
对应字段中文解释:用户ID,电影ID,评分,评分时间戳
题目要求
数据要求:
(1)写shell脚本清洗数据。(hive不支持解析多字节的分隔符,也就是说hive只能解析':', 不支持解析'::',所以用普通方式建表来使用是行不通的,要求对数据做一次简单清洗)
(2)使用Hive能解析的方式进行
Hive要求:
(1)正确建表,导入数据(三张表,三份数据),并验证是否正确
(2)求被评分次数最多的10部电影,并给出评分次数(电影名,评分次数)
(3)分别求男性,女性当中评分最高的10部电影(性别,电影名,影评分)
(4)求movieid = 2116这部电影各年龄段(因为年龄就只有7个,就按这个7个分就好了)的平均影评(年龄段,影评分)
(5)求最喜欢看电影(影评次数最多)的那位女性评最高分的10部电影的平均影评分(观影者,电影名,影评分)
(6)求好片(评分>=4.0)最多的那个年份的最好看的10部电影
(7)求1997年上映的电影中,评分最高的10部Comedy类电影
(8)该影评库中各种类型电影中评价最高的5部电影(类型,电影名,平均影评分)
(9)各年评分最高的电影类型(年份,类型,影评分)
(10)每个地区最高评分的电影名,把结果存入HDFS(地区,电影名,影评分)
数据下载
https://files.cnblogs.com/files/qingyunzong/hive%E5%BD%B1%E8%AF%84%E6%A1%88%E4%BE%8B.zip
解析
之前已经使用MapReduce程序将3张表格进行合并,所以只需要将合并之后的表格导入对应的表中进行查询即可。
1、正确建表,导入数据(三张表,三份数据),并验证是否正确
(1)分析需求
需要创建一个数据库movie,在movie数据库中创建3张表,t_user,t_movie,t_rating
t_user:userid bigint,sex string,age int,occupation string,zipcode string
t_movie:movieid bigint,moviename string,movietype string
t_rating:userid bigint,movieid bigint,rate double,times string
原始数据是以::进行切分的,所以需要使用能解析多字节分隔符的Serde即可
使用RegexSerde
需要两个参数:
input.regex = "(.*)::(.*)::(.*)"
output.format.string = "%1$s %2$s %3$s"
(2)创建数据库
drop database if exists movie; create database if not exists movie; use movie;
(3)创建t_user表
create table t_user(
userid bigint,
sex string,
age int,
occupation string,
zipcode string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)::(.*)::(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s %4$s %5$s')
stored as textfile;
(4)创建t_movie表
use movie;
create table t_movie(
movieid bigint,
moviename string,
movietype string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s')
stored as textfile;
(5)创建t_rating表
use movie;
create table t_rating(
userid bigint,
movieid bigint,
rate double,
times string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)::(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s %4$s')
stored as textfile;
(6)导入数据
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/movie/users.dat" into table t_user; No rows affected (0.928 seconds) 0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/movie/movies.dat" into table t_movie; No rows affected (0.538 seconds) 0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/movie/ratings.dat" into table t_rating; No rows affected (0.963 seconds) 0: jdbc:hive2://hadoop3:10000>
(7)验证
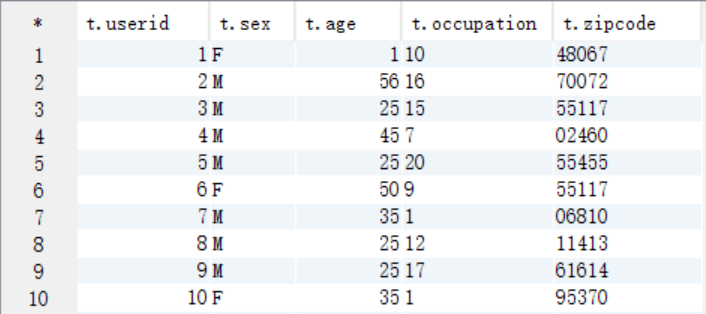
select t.* from t_user t;
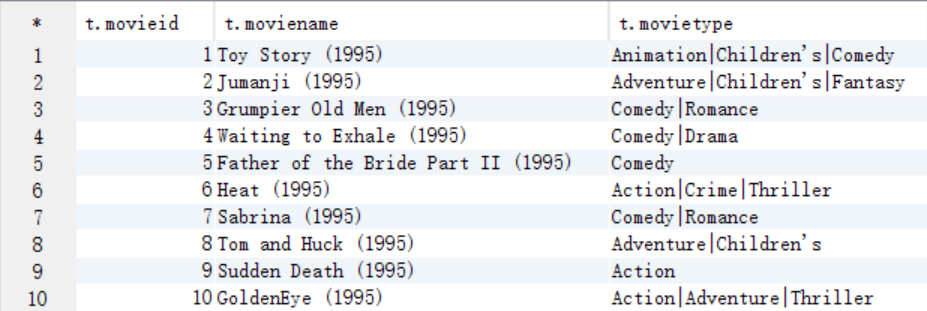
select t.* from t_movie t;
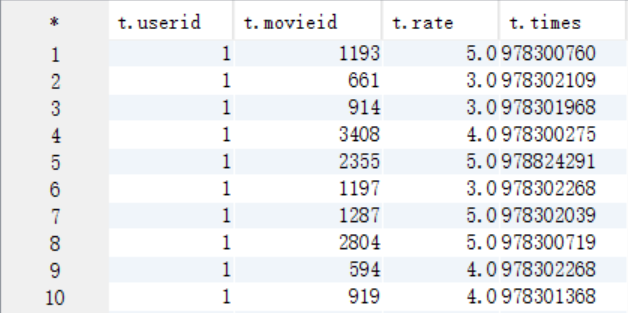
select t.* from t_rating t;
2、求被评分次数最多的10部电影,并给出评分次数(电影名,评分次数)
(1)思路分析:
1、需求字段:电影名 t_movie.moviename
评分次数 t_rating.rate count()
2、核心SQL:按照电影名进行分组统计,求出每部电影的评分次数并按照评分次数降序排序
(2)完整SQL:
create table answer2 as select a.moviename as moviename,count(a.moviename) as total from t_movie a join t_rating b on a.movieid=b.movieid group by a.moviename order by total desc limit 10;
select * from answer2;

3、分别求男性,女性当中评分最高的10部电影(性别,电影名,影评分)
(1)分析思路:
1、需求字段:性别 t_user.sex
电影名 t_movie.moviename
影评分 t_rating.rate
2、核心SQL:三表联合查询,按照性别过滤条件,电影名作为分组条件,影评分作为排序条件进行查询
(2)完整SQL:
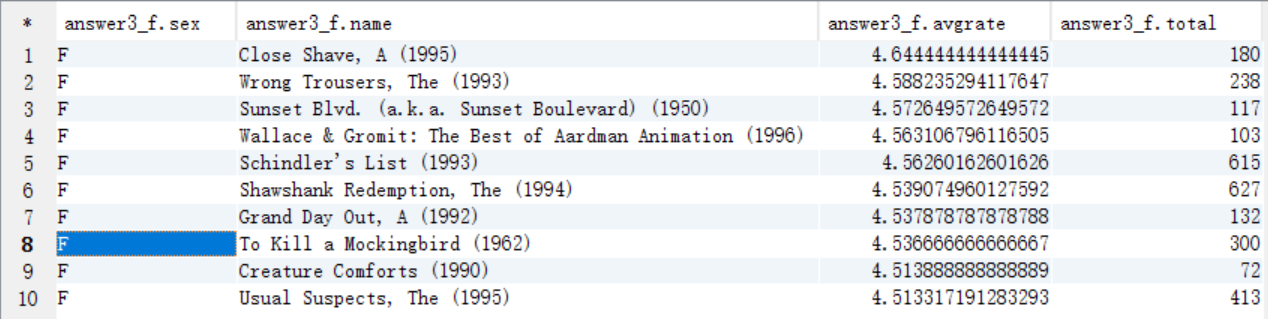
女性当中评分最高的10部电影(性别,电影名,影评分)评论次数大于等于50次
create table answer3_F as select "F" as sex, c.moviename as name, avg(a.rate) as avgrate, count(c.moviename) as total from t_rating a join t_user b on a.userid=b.userid join t_movie c on a.movieid=c.movieid where b.sex="F" group by c.moviename having total >= 50 order by avgrate desc limit 10;
select * from answer3_F;
男性当中评分最高的10部电影(性别,电影名,影评分)评论次数大于等于50次
create table answer3_M as select "M" as sex, c.moviename as name, avg(a.rate) as avgrate, count(c.moviename) as total from t_rating a join t_user b on a.userid=b.userid join t_movie c on a.movieid=c.movieid where b.sex="M" group by c.moviename having total >= 50 order by avgrate desc limit 10;
select * from answer3_M;

4、求movieid = 2116这部电影各年龄段(因为年龄就只有7个,就按这个7个分就好了)的平均影评(年龄段,影评分)
(1)分析思路:
1、需求字段:年龄段 t_user.age
影评分 t_rating.rate
2、核心SQL:t_user和t_rating表进行联合查询,用movieid=2116作为过滤条件,用年龄段作为分组条件
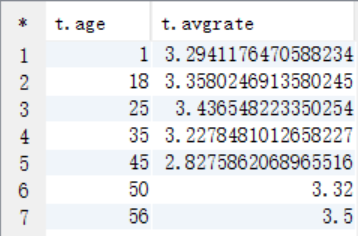
(2)完整SQL:
create table answer4 as select a.age as age, avg(b.rate) as avgrate from t_user a join t_rating b on a.userid=b.userid where b.movieid=2116 group by a.age;
select * from answer4;
5、求最喜欢看电影(影评次数最多)的那位女性评最高分的10部电影的平均影评分(观影者,电影名,影评分)
(1)分析思路:
1、需求字段:观影者 t_rating.userid
电影名 t_movie.moviename
影评分 t_rating.rate
2、核心SQL:
A. 需要先求出最喜欢看电影的那位女性
需要查询的字段:性别:t_user.sex
观影次数:count(t_rating.userid)
B. 根据A中求出的女性userid作为where过滤条件,以看过的电影的影评分rate作为排序条件进行排序,求出评分最高的10部电影
需要查询的字段:电影的ID:t_rating.movieid
C. 求出B中10部电影的平均影评分
需要查询的字段:电影的ID:answer5_B.movieid
影评分:t_rating.rate
(2)完整SQL:
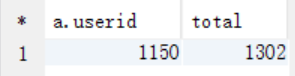
A. 需要先求出最喜欢看电影的那位女性
select a.userid, count(a.userid) as total from t_rating a join t_user b on a.userid = b.userid where b.sex="F" group by a.userid order by total desc limit 1;
B. 根据A中求出的女性userid作为where过滤条件,以看过的电影的影评分rate作为排序条件进行排序,求出评分最高的10部电影
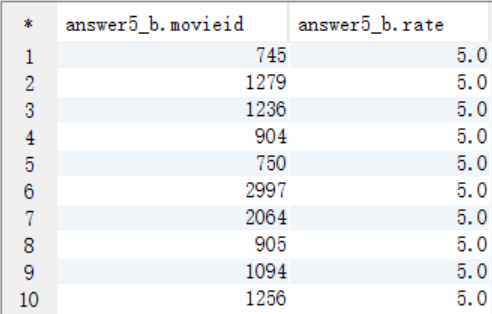
create table answer5_B as select a.movieid as movieid, a.rate as rate from t_rating a where a.userid=1150 order by rate desc limit 10;
select * from answer5_B;
C. 求出B中10部电影的平均影评分
create table answer5_C as select b.movieid as movieid, c.moviename as moviename, avg(b.rate) as avgrate from answer5_B a join t_rating b on a.movieid=b.movieid join t_movie c on b.movieid=c.movieid group by b.movieid,c.moviename;
select * from answer5_C;
6、求好片(评分>=4.0)最多的那个年份的最好看的10部电影
(1)分析思路:
1、需求字段:电影id t_rating.movieid
电影名 t_movie.moviename(包含年份)
影评分 t_rating.rate
上映年份 xxx.years
2、核心SQL:
A. 需要将t_rating和t_movie表进行联合查询,将电影名当中的上映年份截取出来,保存到临时表answer6_A中
需要查询的字段:电影id t_rating.movieid
电影名 t_movie.moviename(包含年份)
影评分 t_rating.rate
B. 从answer6_A按照年份进行分组条件,按照评分>=4.0作为where过滤条件,按照count(years)作为排序条件进行查询
需要查询的字段:电影的ID:answer6_A.years
C. 从answer6_A按照years=1998作为where过滤条件,按照评分作为排序条件进行查询
需要查询的字段:电影的ID:answer6_A.moviename
影评分:answer6_A.avgrate
(2)完整SQL:
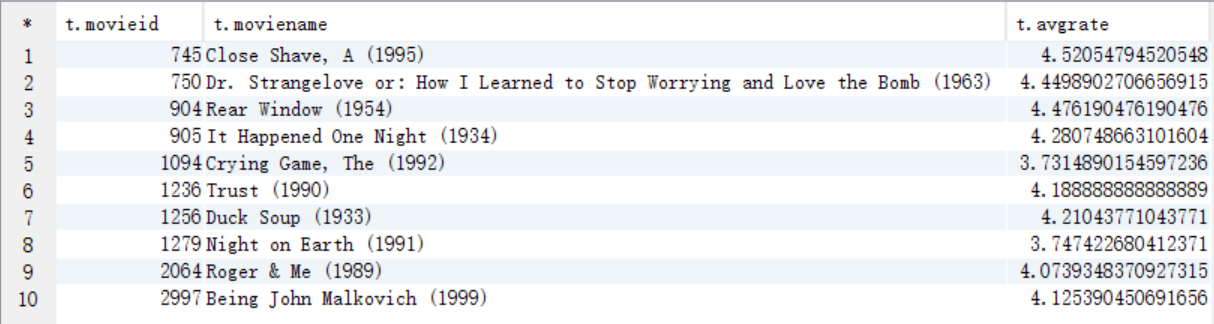
A. 需要将t_rating和t_movie表进行联合查询,将电影名当中的上映年份截取出来
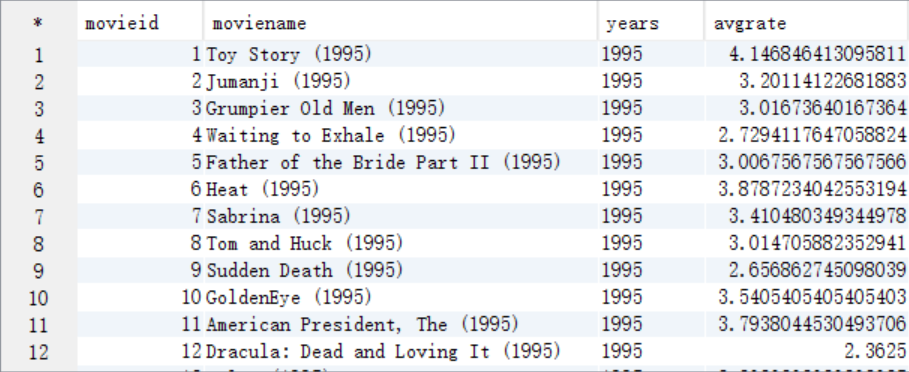
create table answer6_A as select a.movieid as movieid, a.moviename as moviename, substr(a.moviename,-5,4) as years, avg(b.rate) as avgrate from t_movie a join t_rating b on a.movieid=b.movieid group by a.movieid, a.moviename;
select * from answer6_A;
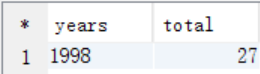
B. 从answer6_A按照年份进行分组条件,按照评分>=4.0作为where过滤条件,按照count(years)作为排序条件进行查询
select years, count(years) as total from answer6_A a where avgrate >= 4.0 group by years order by total desc limit 1;
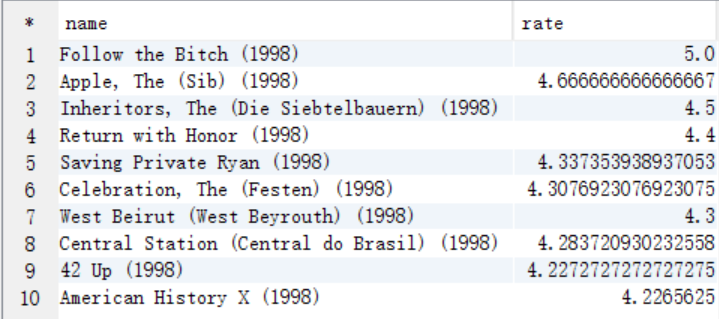
C. 从answer6_A按照years=1998作为where过滤条件,按照评分作为排序条件进行查询
create table answer6_C as select a.moviename as name, a.avgrate as rate from answer6_A a where a.years=1998 order by rate desc limit 10;
select * from answer6_C;
7、求1997年上映的电影中,评分最高的10部Comedy类电影
(1)分析思路:
1、需求字段:电影id t_rating.movieid
电影名 t_movie.moviename(包含年份)
影评分 t_rating.rate
上映年份 xxx.years(最终查询结果可不显示)
电影类型 xxx.type(最终查询结果可不显示)
2、核心SQL:
A. 需要电影类型,所有可以将第六步中求出answer6_A表和t_movie表进行联合查询
需要查询的字段:电影id answer6_A.movieid
电影名 answer6_A.moviename
影评分 answer6_A.rate
电影类型 t_movie.movietype
上映年份 answer6_A.years
B. 从answer7_A按照电影类型中是否包含Comedy和按上映年份作为where过滤条件,按照评分作为排序条件进行查询,将结果保存到answer7_B中
需要查询的字段:电影的ID:answer7_A.id
电影的名称:answer7_A.name
电影的评分:answer7_A.rate
(2)完整SQL:
A. 需要电影类型,所有可以将第六步中求出answer6_A表和t_movie表进行联合查询
create table answer7_A as select b.movieid as id, b.moviename as name, b.years as years, b.avgrate as rate, a.movietype as type from t_movie a join answer6_A b on a.movieid=b.movieid;
select t.* from answer7_A t;
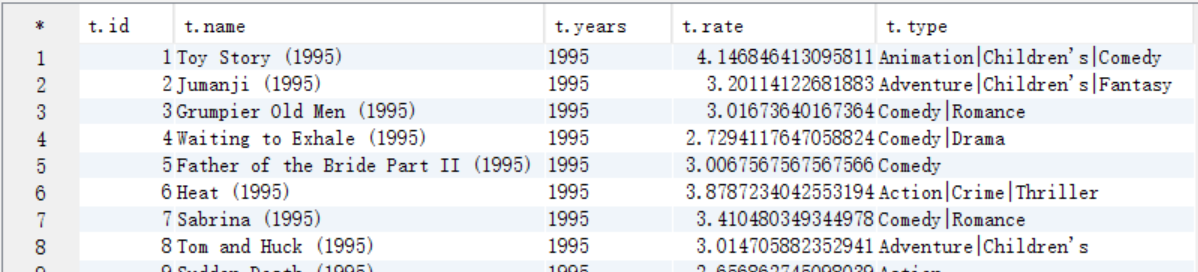
B. 从answer7_A按照电影类型中是否包含Comedy和按照评分>=4.0作为where过滤条件,按照评分作为排序条件进行查询,将结果保存到answer7_B中
create table answer7_B as select t.id as id, t.name as name, t.rate as rate from answer7_A t where t.years=1997 and instr(lcase(t.type),'comedy') >0 order by rate desc limit 10;
select * from answer7_B;
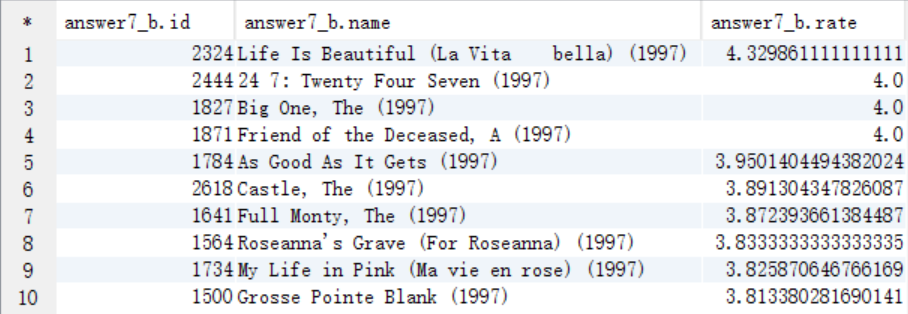
8、该影评库中各种类型电影中评价最高的5部电影(类型,电影名,平均影评分)
(1)分析思路:
1、需求字段:电影id movieid
电影名 moviename
影评分 rate(排序条件)
电影类型 type(分组条件)
2、核心SQL:
A. 需要电影类型,所有需要将answer7_A中的type字段进行裂变,将结果保存到answer8_A中
需要查询的字段:电影id answer7_A.id
电影名 answer7_A.name(包含年份)
上映年份 answer7_A.years
影评分 answer7_A.rate
电影类型 answer7_A.movietype
B. 求TopN,按照type分组,需要添加一列来记录每组的顺序,将结果保存到answer8_B中
row_number() :用来生成 num字段的值
distribute by movietype :按照type进行分组
sort by avgrate desc :每组数据按照rate排降序
num:新列, 值就是每一条记录在每一组中按照排序规则计算出来的排序值
C. 从answer8_B中取出num列序号<=5的
(2)完整SQL:
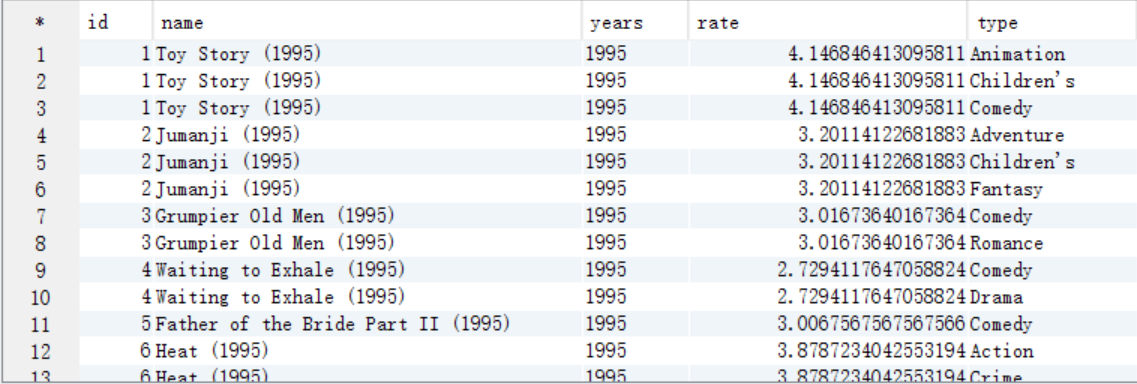
A. 需要电影类型,所有需要将answer7_A中的type字段进行裂变,将结果保存到answer8_A中
create table answer8_A as select a.id as id, a.name as name, a.years as years, a.rate as rate, tv.type as type from answer7_A a lateral view explode(split(a.type,"\|")) tv as type;
select * from answer8_A;
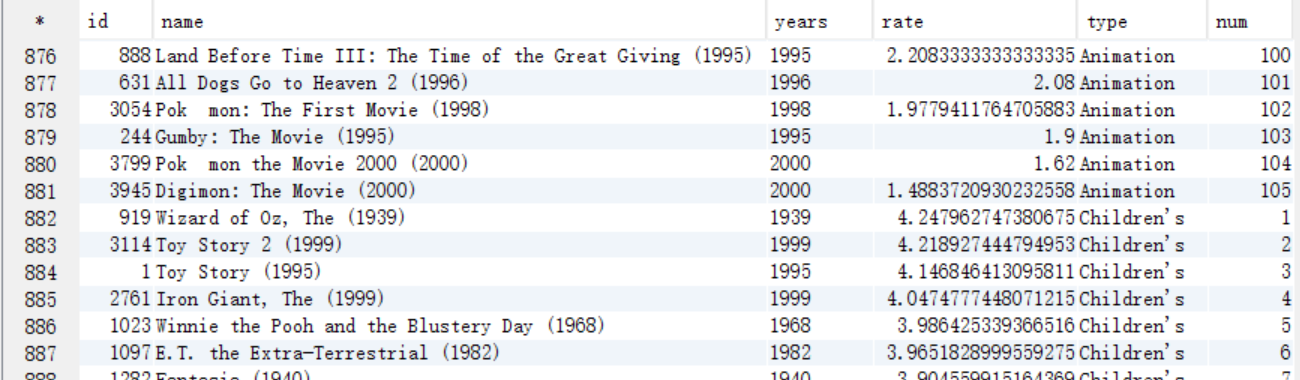
B. 求TopN,按照type分组,需要添加一列来记录每组的顺序,将结果保存到answer8_B中
create table answer8_B as select id,name,years,rate,type,row_number() over(distribute by type sort by rate desc ) as num from answer8_A;
select * from answer8_B;
C. 从answer8_B中取出num列序号<=5的
select a.* from answer8_B a where a.num <= 5;
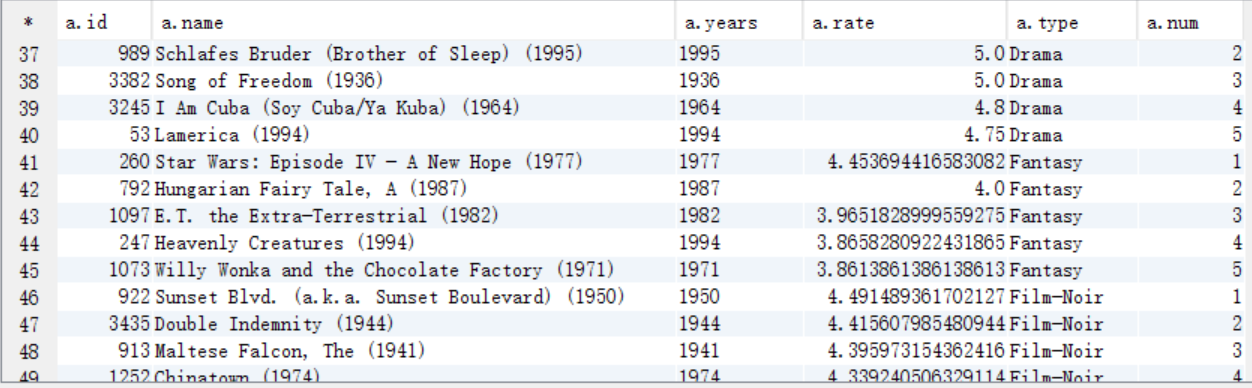
9、各年评分最高的电影类型(年份,类型,影评分)
(1)分析思路:
1、需求字段:电影id movieid
电影名 moviename
影评分 rate(排序条件)
电影类型 type(分组条件)
上映年份 years(分组条件)
2、核心SQL:
A. 需要按照电影类型和上映年份进行分组,按照影评分进行排序,将结果保存到answer9_A中
需要查询的字段:
上映年份 answer7_A.years
影评分 answer7_A.rate
电影类型 answer7_A.movietype
B. 求TopN,按照years分组,需要添加一列来记录每组的顺序,将结果保存到answer9_B中
C. 按照num=1作为where过滤条件取出结果数据
(2)完整SQL:
A. 需要按照电影类型和上映年份进行分组,按照影评分进行排序,将结果保存到answer9_A中
create table answer9_A as select a.years as years, a.type as type, avg(a.rate) as rate from answer8_A a group by a.years,a.type order by rate desc;
select * from answer9_A;
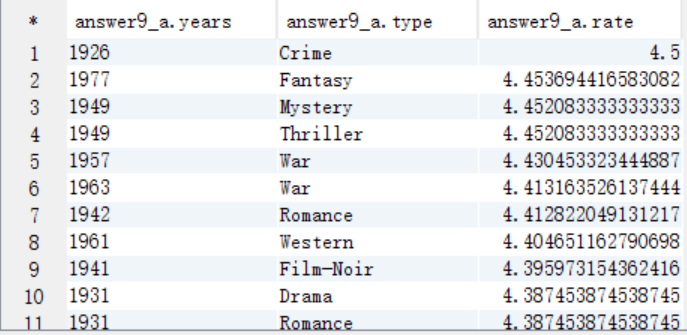
B. 求TopN,按照years分组,需要添加一列来记录每组的顺序,将结果保存到answer9_B中
create table answer9_B as select years,type,rate,row_number() over (distribute by years sort by rate) as num from answer9_A;
select * from answer9_B;
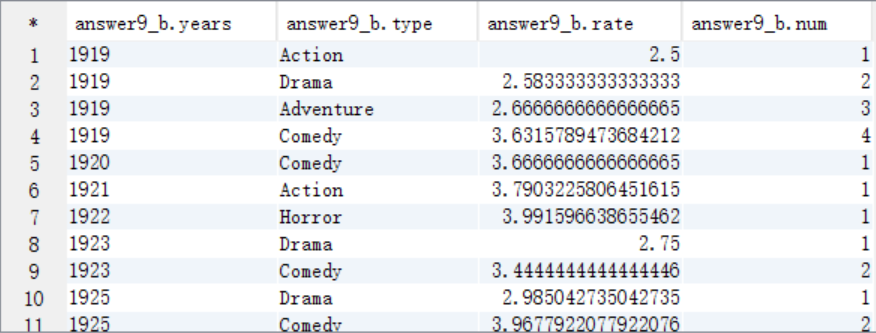
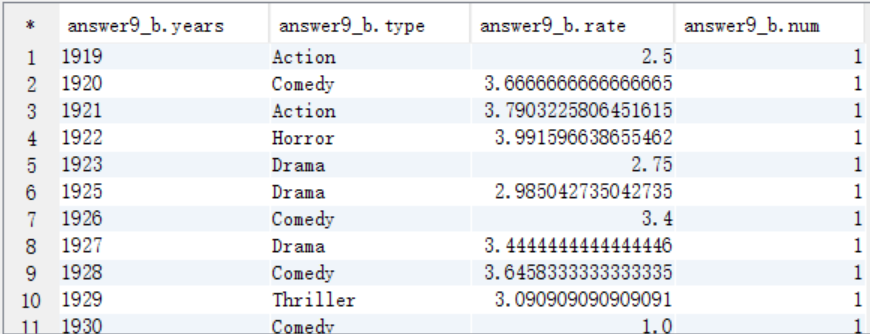
C. 按照num=1作为where过滤条件取出结果数据
select * from answer9_B where num=1;
10、每个地区最高评分的电影名,把结果存入HDFS(地区,电影名,影评分)
(1)分析思路:
1、需求字段:电影id t_movie.movieid
电影名 t_movie.moviename
影评分 t_rating.rate(排序条件)
地区 t_user.zipcode(分组条件)
2、核心SQL:
A. 需要把三张表进行联合查询,取出电影id、电影名称、影评分、地区,将结果保存到answer10_A表中
需要查询的字段:电影id t_movie.movieid
电影名 t_movie.moviename
影评分 t_rating.rate(排序条件)
地区 t_user.zipcode(分组条件)
B. 求TopN,按照地区分组,按照平均排序,添加一列num用来记录地区排名,将结果保存到answer10_B表中
C. 按照num=1作为where过滤条件取出结果数据
(2)完整SQL:
A. 需要把三张表进行联合查询,取出电影id、电影名称、影评分、地区,将结果保存到answer10_A表中
create table answer10_A as select c.movieid, c.moviename, avg(b.rate) as avgrate, a.zipcode from t_user a join t_rating b on a.userid=b.userid join t_movie c on b.movieid=c.movieid group by a.zipcode,c.movieid, c.moviename;
select t.* from answer10_A t;

B. 求TopN,按照地区分组,按照平均排序,添加一列num用来记录地区排名,将结果保存到answer10_B表中
create table answer10_B as select movieid,moviename,avgrate,zipcode, row_number() over (distribute by zipcode sort by avgrate) as num from answer10_A;
select t.* from answer10_B t;
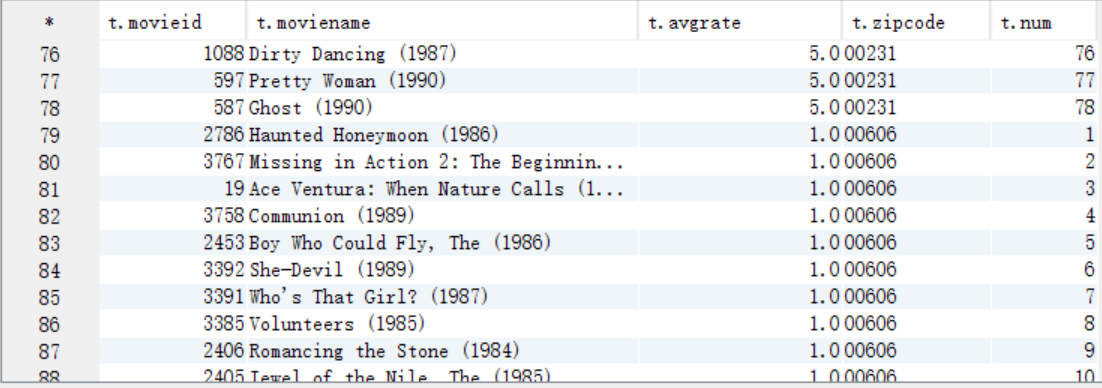
C. 按照num=1作为where过滤条件取出结果数据并保存到HDFS上
insert overwrite directory "/movie/answer10/" select t.* from answer10_B t where t.num=1;

二、求单月访问次数和总访问次数
1、数据说明
数据字段说明
用户名,月份,访问次数
数据格式
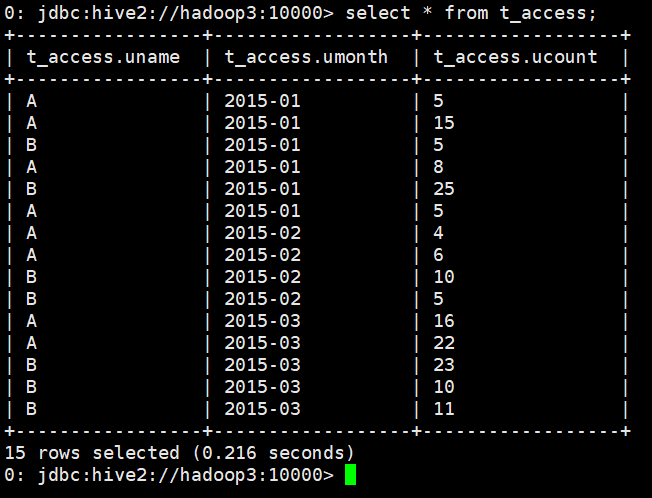
A,2015-01,5 A,2015-01,15 B,2015-01,5 A,2015-01,8 B,2015-01,25 A,2015-01,5 A,2015-02,4 A,2015-02,6 B,2015-02,10 B,2015-02,5 A,2015-03,16 A,2015-03,22 B,2015-03,23 B,2015-03,10 B,2015-03,1
2、数据准备
(1)创建表
use myhive; create external table if not exists t_access( uname string comment '用户名', umonth string comment '月份', ucount int comment '访问次数' ) comment '用户访问表' row format delimited fields terminated by "," location "/hive/t_access";
(2)导入数据
load data local inpath "/home/hadoop/access.txt" into table t_access;
(3)验证数据
select * from t_access;
3、结果需求
现要求出:
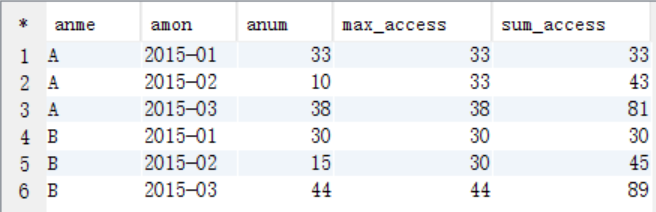
每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数,结果数据格式如下

4、需求分析
此结果需要根据用户+月份进行分组
(1)先求出当月访问次数
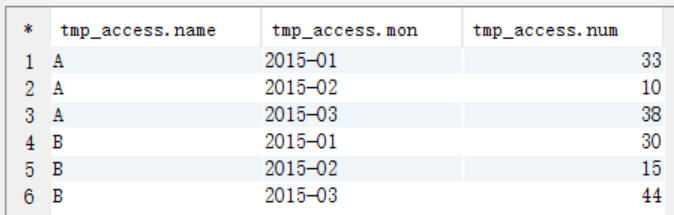
--求当月访问次数 create table tmp_access( name string, mon string, num int ); insert into table tmp_access select uname,umonth,sum(ucount) from t_access t group by t.uname,t.umonth;
select * from tmp_access;
(2)tmp_access进行自连接视图
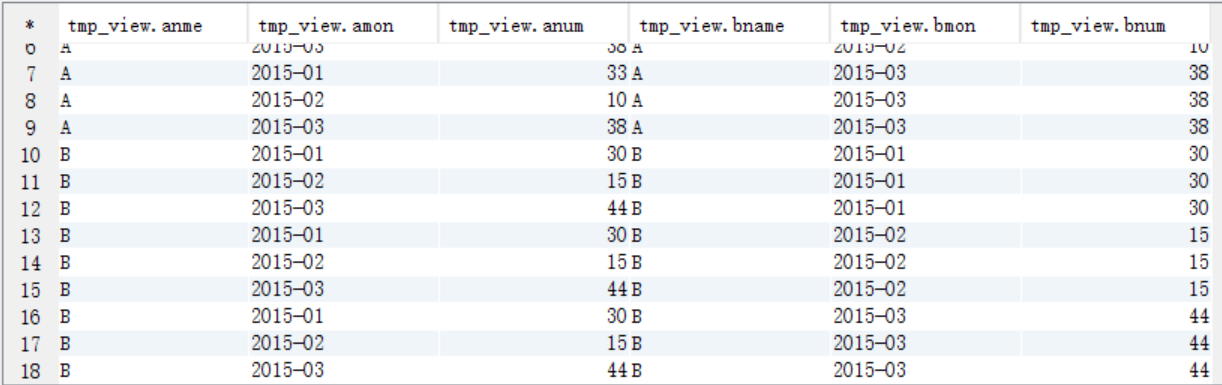
create view tmp_view as select a.name anme,a.mon amon,a.num anum,b.name bname,b.mon bmon,b.num bnum from tmp_access a join tmp_access b on a.name=b.name; select * from tmp_view;
(3)进行比较统计
select anme,amon,anum,max(bnum) as max_access,sum(bnum) as sum_access from tmp_view where amon>=bmon group by anme,amon,anum;
三、学生课程成绩
1、数据准备
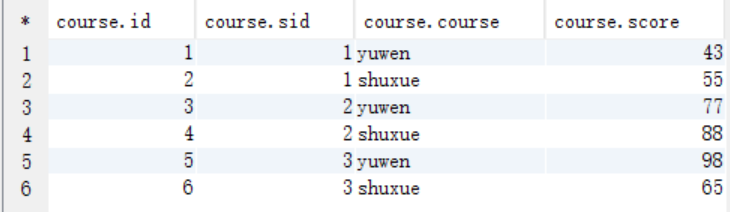
use myhive; CREATE TABLE `course` ( `id` int, `sid` int , `course` string, `score` int ) ;
// 插入数据 // 字段解释:id, 学号, 课程, 成绩 INSERT INTO `course` VALUES (1, 1, 'yuwen', 43); INSERT INTO `course` VALUES (2, 1, 'shuxue', 55); INSERT INTO `course` VALUES (3, 2, 'yuwen', 77); INSERT INTO `course` VALUES (4, 2, 'shuxue', 88); INSERT INTO `course` VALUES (5, 3, 'yuwen', 98); INSERT INTO `course` VALUES (6, 3, 'shuxue', 65);
2、需求
求:所有数学课程成绩 大于 语文课程成绩的学生的学号
1、使用case...when...将不同的课程名称转换成不同的列
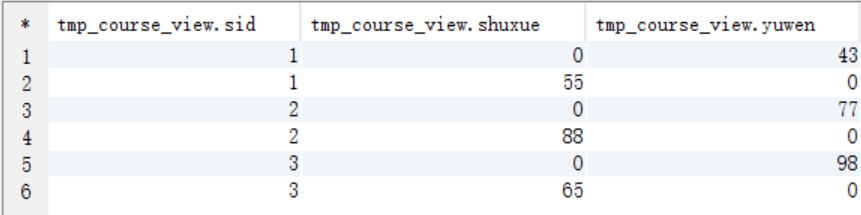
create view tmp_course_view as select sid, case course when "shuxue" then score else 0 end as shuxue, case course when "yuwen" then score else 0 end as yuwen from course; select * from tmp_course_view;
2、以sid分组合并取各成绩最大值
create view tmp_course_view1 as select aa.sid, max(aa.shuxue) as shuxue, max(aa.yuwen) as yuwen from tmp_course_view aa group by sid; select * from tmp_course_view1;

3、比较结果
select * from tmp_course_view1 where shuxue > yuwen;

四、求每一年最大气温的那一天+温度
1、说明
数据格式
2010012325
具体数据
 View Code
View Code数据解释
2010012325表示在2010年01月23日的气温为25度
2、 需求
比如:2010012325表示在2010年01月23日的气温为25度。现在要求使用hive,计算每一年出现过的最大气温的日期+温度。
要计算出每一年的最大气温。我用
select substr(data,1,4),max(substr(data,9,2)) from table2 group by substr(data,1,4);
出来的是 年份 + 温度 这两列数据例如 2015 99
但是如果我是想select 的是:具体每一年最大气温的那一天 + 温度 。例如 20150109 99
请问该怎么执行hive语句。。
group by 只需要substr(data,1,4),
但是select substr(data,1,8),又不在group by 的范围内。
是我陷入了思维死角。一直想不出所以然。。求大神指点一下。
在select 如果所需要的。不在group by的条件里。这种情况如何去分析?
3、解析
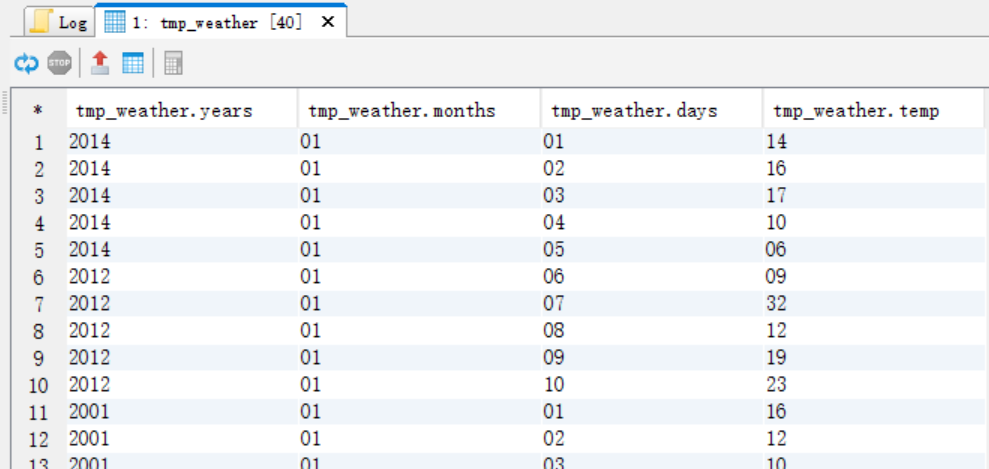
(1)创建一个临时表tmp_weather,将数据切分
create table tmp_weather as select substr(data,1,4) years,substr(data,5,2) months,substr(data,7,2) days,substr(data,9,2) temp from weather;
select * from tmp_weather;
(2)创建一个临时表tmp_year_weather
create table tmp_year_weather as select substr(data,1,4) years,max(substr(data,9,2)) max_temp from weather group by substr(data,1,4);
select * from tmp_year_weather;
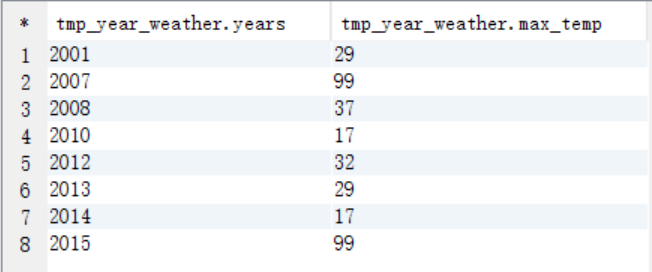
(3)将2个临时表进行连接查询
select * from tmp_year_weather a join tmp_weather b on a.years=b.years and a.max_temp=b.temp;
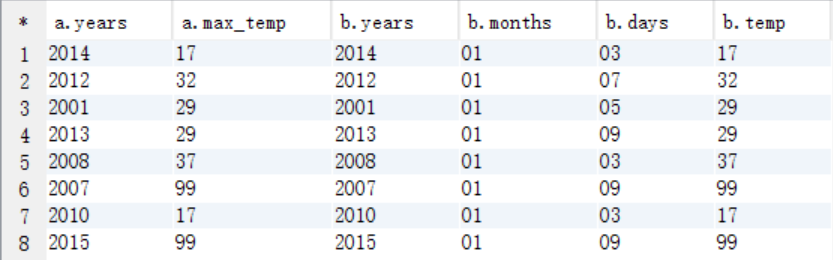
五、求学生选课情况
1、数据说明
(1)数据格式
id course 1,a 1,b 1,c 1,e 2,a 2,c 2,d 2,f 3,a 3,b 3,c 3,e
(2)字段含义
表示有id为1,2,3的学生选修了课程a,b,c,d,e,f中其中几门。
2、数据准备
(1)建表t_course
create table t_course(id int,course string) row format delimited fields terminated by ",";

(2)导入数据
load data local inpath "/home/hadoop/course/course.txt" into table t_course;

3、需求
编写Hive的HQL语句来实现以下结果:表中的1表示选修,表中的0表示未选修
id a b c d e f 1 1 1 1 0 1 0 2 1 0 1 1 0 1 3 1 1 1 0 1 0
4、解析
第一步:
select collect_set(course) as courses from id_course;
第二步:
set hive.strict.checks.cartesian.product=false; create table id_courses as select t1.id as id,t1.course as id_courses,t2.course courses from ( select id as id,collect_set(course) as course from id_course group by id ) t1 join (select collect_set(course) as course from id_course) t2;
启用严格模式:hive.mapred.mode = strict // Deprecated
hive.strict.checks.large.query = true
该设置会禁用:1. 不指定分页的orderby
2. 对分区表不指定分区进行查询
3. 和数据量无关,只是一个查询模式hive.strict.checks.type.safety = true
严格类型安全,该属性不允许以下操作:1. bigint和string之间的比较
2. bigint和double之间的比较hive.strict.checks.cartesian.product = true
该属性不允许笛卡尔积操作
第三步:得出最终结果:
思路:
拿出course字段中的每一个元素在id_courses中进行判断,看是否存在。
select id, case when array_contains(id_courses, courses[0]) then 1 else 0 end as a, case when array_contains(id_courses, courses[1]) then 1 else 0 end as b, case when array_contains(id_courses, courses[2]) then 1 else 0 end as c, case when array_contains(id_courses, courses[3]) then 1 else 0 end as d, case when array_contains(id_courses, courses[4]) then 1 else 0 end as e, case when array_contains(id_courses, courses[5]) then 1 else 0 end as f from id_courses;
六、求月销售额和总销售额
1、数据说明
(1)数据格式
a,01,150 a,01,200 b,01,1000 b,01,800 c,01,250 c,01,220 b,01,6000 a,02,2000 a,02,3000 b,02,1000 b,02,1500 c,02,350 c,02,280 a,03,350 a,03,250
(2)字段含义
店铺,月份,金额
2、数据准备
(1)创建数据库表t_store
use class; create table t_store( name string, months int, money int ) row format delimited fields terminated by ",";
(2)导入数据
load data local inpath "/home/hadoop/store.txt" into table t_store;
3、需求
编写Hive的HQL语句求出每个店铺的当月销售额和累计到当月的总销售额
4、解析
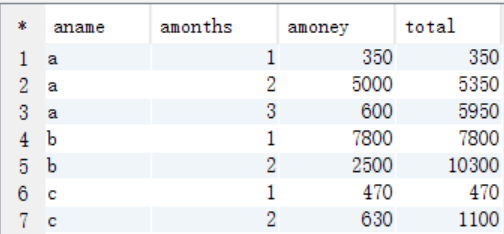
(1)按照商店名称和月份进行分组统计
create table tmp_store1 as select name,months,sum(money) as money from t_store group by name,months; select * from tmp_store1;
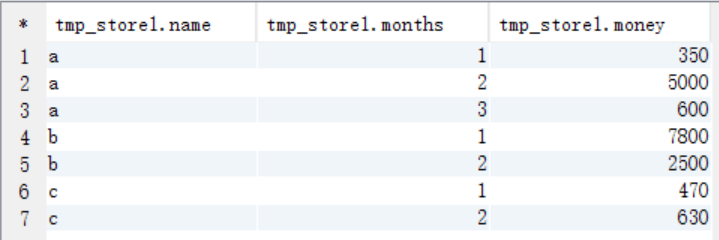
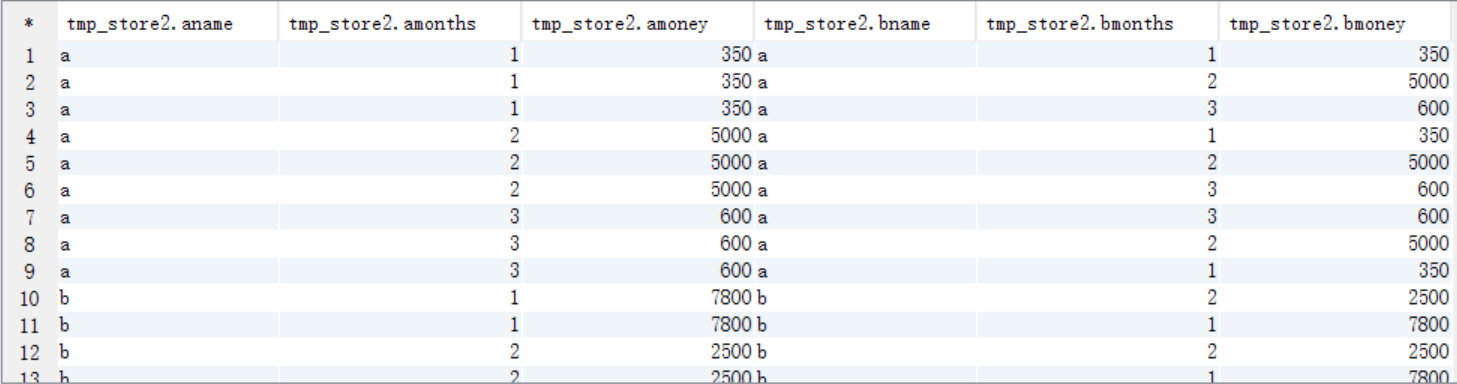
(2)对tmp_store1 表里面的数据进行自连接
create table tmp_store2 as select a.name aname,a.months amonths,a.money amoney,b.name bname,b.months bmonths,b.money bmoney from tmp_store1 a join tmp_store1 b on a.name=b.name order by aname,amonths; select * from tmp_store2;
(3)比较统计
select aname,amonths,amoney,sum(bmoney) as total from tmp_store2 where amonths >= bmonths group by aname,amonths,amoney;