论文源址:https://arxiv.org/pdf/1612.01105.pdf
tensorflow代码:https://github.com/hellochick/PSPNet-tensorflow
基于PSPNet101的钢铁分割实验:https://github.com/fourmi1995/IronSegExperiment-PSPNet
摘要
对于不非特殊条件的场景解析仍十分困难。该文利用金字塔池化模型,融合了图像中不同区域的上下文信息。
介绍
分割可以预测完全理解场景,预测标签,位置,及其形状。目前基于FCN的分割网络提高了理解物体的能力,但面对非特殊条件的场景识别仍有挑战。比如相似物体的误分类。下图中由于船与车有相似的外形因此被误分类为船,但结合上下文信息,船在水面上,所以应大概率判断为一条船。
为了更好的进行场景预测,需要结合场景信息,目前大部分基于FCN的模型大都未有效的利用图片的上下文信息。相比以前将整张图片送入,空间金字塔得到的空间统计信息能更有效的描述图片中潜在的信息。

与上述方法不同,该文提出的PSPNet,除了利用传统的空洞FCN网络,将像素级的特征送入全局金字塔池化层中,局部和全局的信息一起作用于最后的预测,对于深度学习的loss提出了一种新的优化策略。该文主要贡献如下:
(1)提出了金字塔场景分析网络-基于FCN同时结合复杂的场景语义信息进行像素级预测框架。
(2)发现高效优化ResNet网络的策略。
(3)建立有效进行场景分析与语义分割的体系。
相关工作:
该文基于FCN与空洞网络,部分网络大致的两个研究方向为:(1)多尺寸特征信息 -网络的较深层包含更多的语义信息,但缺少位置等细节信息。(2)结构预测- 以前用CRF作为后处理来优化分割的结果。也有网络通过进行端到端的训练来增强结果。这些方法都改进了场景分析中的边界信息。
有基于传统特征(非深度学习得到的特征)提取的全局语义信息,提出了全局平均池化层的FCN可以提高分割结果,但通过实验发现这些操作提取的全局文本信息仍不足,该文利用PSPNet结合不同区域的上下文信息来增强全局信息。
金字塔场景分析网络
普通FCN面向复杂场景分析出现的问题总结:
(1)关系不匹配 - 未有效的利用图片中的上下文信息。
(2)类别混乱 - 比如 mountain and hill,building and skyscraper相似的外形却是不同的类别,解决方法是有效利用类别之间的关系。
(3)不明显的类别 - 场景中包含任意尺寸大小的物体,一些重要的小物体可能检测不到,相反,一些较大的物体超过FCN的感受野,导致无法进行连续的分割预测。因此,需要重视不同区域中不显眼的物体。
总结:上述产生的误差部分或者全部受到不同感受野的文本信息的关系与全局信息影响。一个带有适合全局场景信息的网络可以改善上述问题。
模型分析
在DNN中,感受野的大小可以大致与获得的文本信息量的多少挂钩。虽然理论上ResNet的感受野大小要比输入图像的大小大,但在CNN深层网络上的感受野实际却较小,从而导致无法有效的结合场景信息。不同区域的全局信息有助于区分不同类别。由金字塔池化不同层得到的feature map被拉直然后进行拼接送到全连接层中进行分类。全局优先(利用多尺度信息)的目的是解决用于分类CNN(自带全连接层,假设不同尺寸图片的输入 ,最后一层feature map大小有4x4,3x3,这里就出现问题)的固定尺寸的限制。
为了减少不同子区域上下文信息的损失,该文提出全局场景优先结构夹在CNN最后一层feature map上,结合不同子区域及不同尺寸的语义信息。
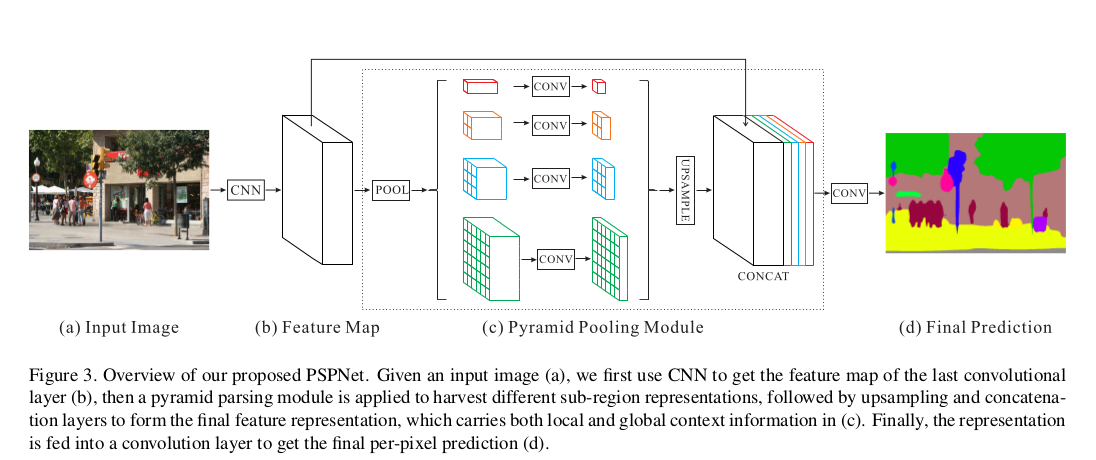
该模型fuse四个不同金字塔尺寸的特征,该结构将输入的feature map分为不同的子区域同时,并生成不同位置的polling 表示,从而产生不同尺寸的输出,为了强化全局特征的权重,在金字塔层数为N的情况下,利用一个1x1的卷积将上下文表示的维度将到1/N。然后将得到的特征通过双线性插值上采样至相同尺寸,进行拼接作为最终的全局金字塔池化特征。
网络结构
用带有空洞卷积的预训练的ResNet作为backbone,最后一层提取的feature map大小为输入图像的1/8。结构特点:相比global pooling,该模型获取多尺寸全局信息效果更好。计算上相比dilated FCN网络也不会增加很多,global pyramid pooling模型与FCN特征提取模型可以同时进行训练优化。
对于基于FCN的ResNet的深层监督
ResNet后部的网络层学习前面层数的參差特征。该文通过额外一个loss监督某一层初始分类结果,然后通过最终的loss对參差进行学习。
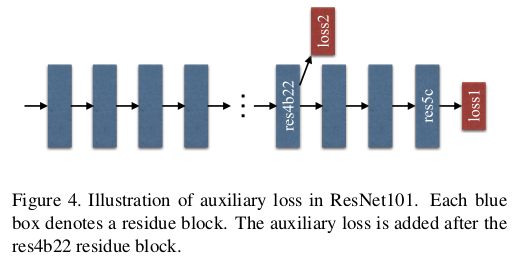
Loss1基于softmax loss用于训练最终的分类器,在ResNet第四阶段处添加了一个分类器进行辅助优化,两个loss一起传播,使用不同的权重,一起优化,最终将二者按权重相加进行平衡。
测试时将辅助loss2移除,只使用效果较好的loss1进行预测。
实验
在ImageNet scene parsing challeng 2016 , PASCAL VOC2012 semantic segmentation, Cityscapes上进行测试
学习策略:poly
base learning:0.01
power:0.9
Momentum:0.9
weigth decay:0.0001
data augmentation
batchsize:16
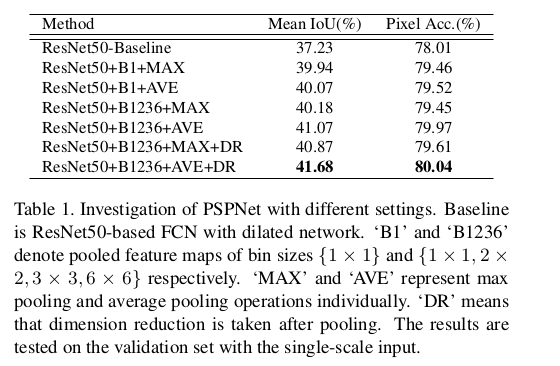
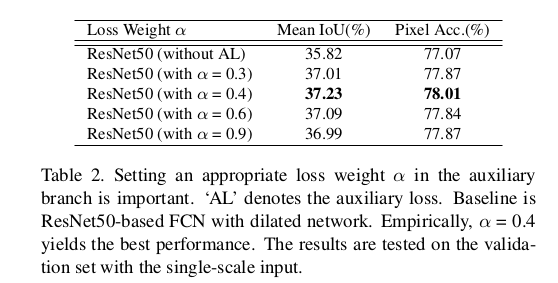
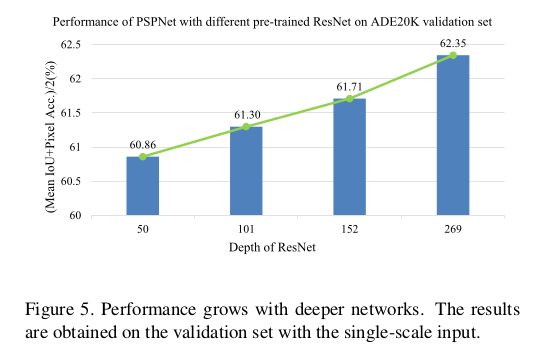
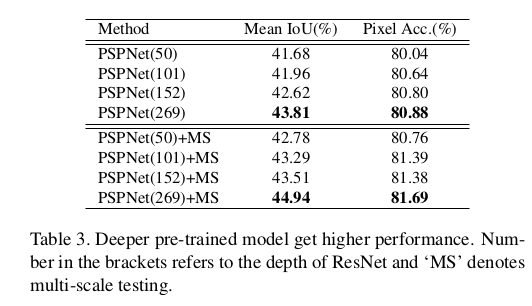
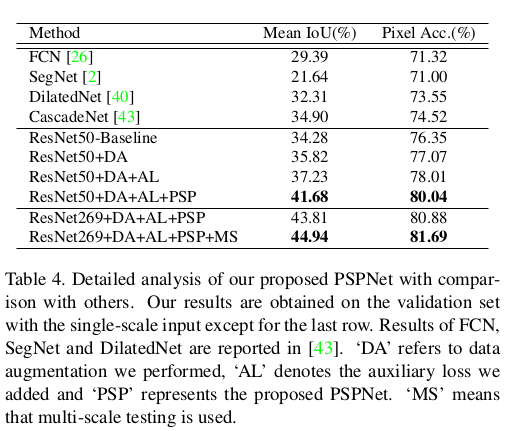
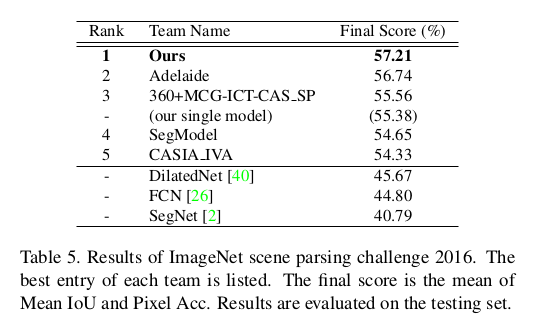
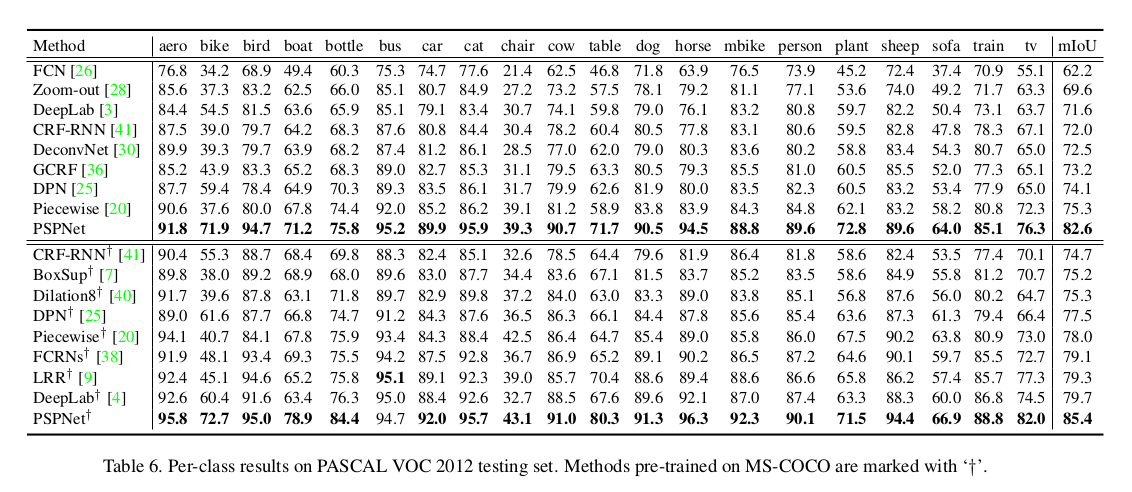
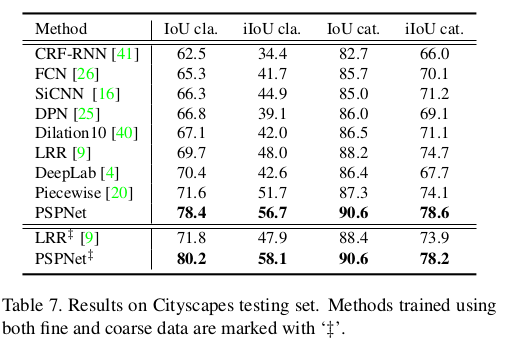 Reference
Reference
[1] A. Arnab, S. Jayasumana, S. Zheng, and P. H. S. Torr. Higherorder conditional random fields in deep neural networks. In ECCV, 2016. 2
[2] V. Badrinarayanan, A. Kendall, and R. Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv:1511.00561, 2015. 6
[3] L. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L.Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv:1412.7062, 2014.1, 2, 4, 7, 8
个人实验结果