
论文原址:https://arxiv.org/abs/1904.01169
摘要
视觉任务中多尺寸的特征表示十分重要,作为backbone的CNN的对尺寸表征能力越强,性能提升越大。目前,大多数多尺寸的表示方法是layer-wise的。本文提出的Res2Net通过在单一残差块中对残差连接进行分级,进而可以达到细粒度层级的多尺度表征,同时,提高了网络每层的感受野大小。该Res2Net结构可以嵌入到其他网络模型中。
介绍
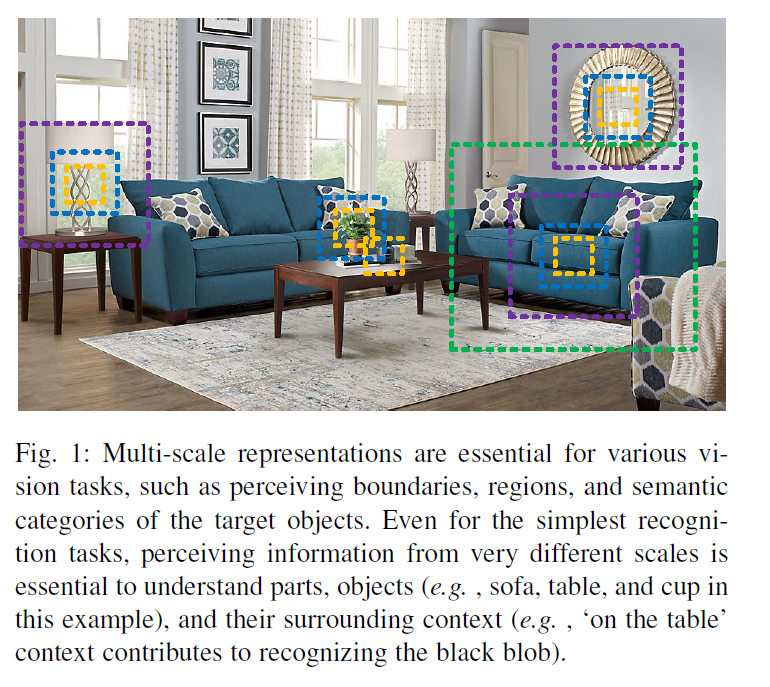
在自然场景中,视觉模式经常表现多尺寸特征。如下图所示,(1)一张图片中可能会存在不同尺寸的物体。比如,沙发及被子的大小是不同的。(2)一个物体自身的上下文信息可能会覆盖比自身更大范围的区域。比如,依赖于桌子的上下文信息,进而判断桌子上的黑色斑点是杯子还是笔筒。(3)不同尺寸的感知信息对于像细粒度分类及分割等对于理解目标物局部信息的任务十分重要。
为了获得多尺寸表示能力,要求特征提取可以以较大范围的感受野来描述不同尺寸的 object/part/context。CNN通过简单的堆叠卷积操作得到coarse-to-fine的多尺寸特征。早期的工作像VGG,Alex通过简单的堆积卷积让多尺寸信息成为了可能。后来,通过组合不同大小的卷积核来获得多尺寸信息,比如Inception系列。作为backbone的CNN表现更高效,多尺寸的表征能力更强。
本文提出了简单高效的多尺寸模块,不同于以前的模型提高layer-wise的多尺寸表征能力,本文以更精细的水平提高模型的多尺寸表征能力。为此,本文将3x3xn的卷积核替换为3x3xw的group filters,其中,n = w x s。如下图所示,更小的filter group通过类似于残差连接的方式进行连接,从而提高输出的表示数量,首先,将输入分成几部分,一组filter从对应的一组输入feature map中提取信息。前面得到的信息送到另一组filter中作为输入。重复此操作,知道处理完所有输入feature map。最后,每组输出的feature map通过拼接操作送入1x1的卷积中用于进行特征融合。此方法引入了一个新的维度scale,用于控制group的数量。scale同height,width,cardinality相似,都为基本量,本文实验发现,通过增加scale的数量的提升效果要比其他量要好。
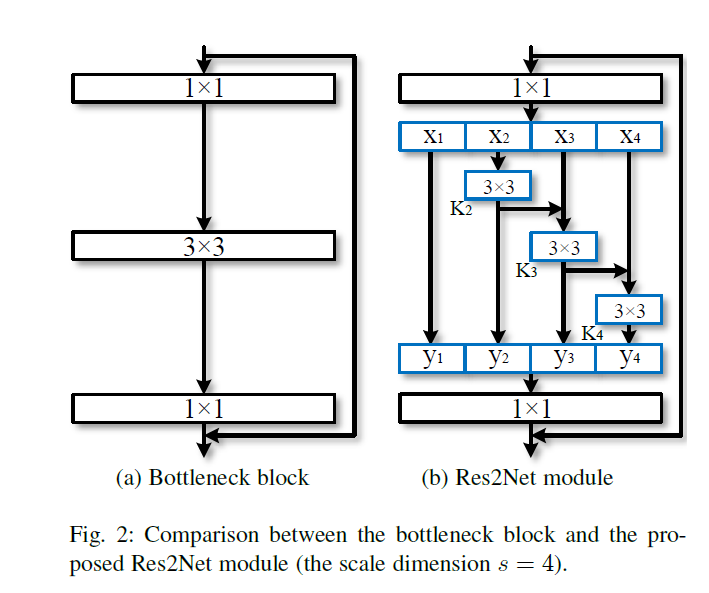
Res2Net
上图是backbone网络中比较常见的结构。本文将其中的3x3的卷积核替换为几组小的卷积核并以残差的方式进行连接,在计算力相同的条件下获得更强的多尺寸表征信息。如上图b所示,将输入feature map分为s个subset,由xi表示,![]() ,每个subuset的宽及高相同,但是通道数为输入feature map的1/s。除了x1,每个xi都有一个3x3的卷积核Ki,其输出由yi表示。同时,子集xi与Ki-1的输出相加并作为Ki的输入。为了忽略参数量,并提高s,x1中并不存在3x3的卷积核,因此,yi的表达式如下
,每个subuset的宽及高相同,但是通道数为输入feature map的1/s。除了x1,每个xi都有一个3x3的卷积核Ki,其输出由yi表示。同时,子集xi与Ki-1的输出相加并作为Ki的输入。为了忽略参数量,并提高s,x1中并不存在3x3的卷积核,因此,yi的表达式如下
![]()
值得注意的是,每个3x3的卷积核可以接受来自该层前面的所有分离的特征![]() ,每次分类特征经过3x3的卷积处理后,其输出的感受野要比输入更大,由于不同的组合方式,Res2Net的输出包含不同大小及数量的感受野。在Res2Net中,Split以多尺寸的方式进行处理,有利于提取全局及局部特征。为了融合不同尺寸的信息,将输出送入到1x1的卷积中。分离拼接操作可以增强卷积的处理能力。为了减少参数量,忽略了第一个group的卷积,这也可以看作是feature map的再利用。
,每次分类特征经过3x3的卷积处理后,其输出的感受野要比输入更大,由于不同的组合方式,Res2Net的输出包含不同大小及数量的感受野。在Res2Net中,Split以多尺寸的方式进行处理,有利于提取全局及局部特征。为了融合不同尺寸的信息,将输出送入到1x1的卷积中。分离拼接操作可以增强卷积的处理能力。为了减少参数量,忽略了第一个group的卷积,这也可以看作是feature map的再利用。
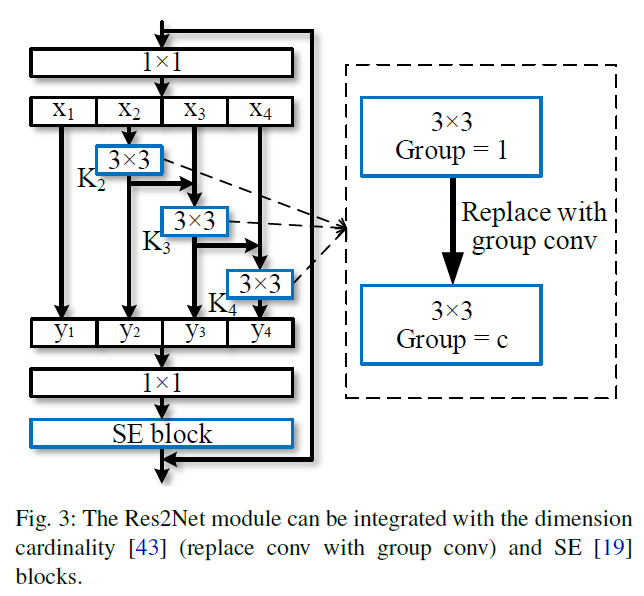
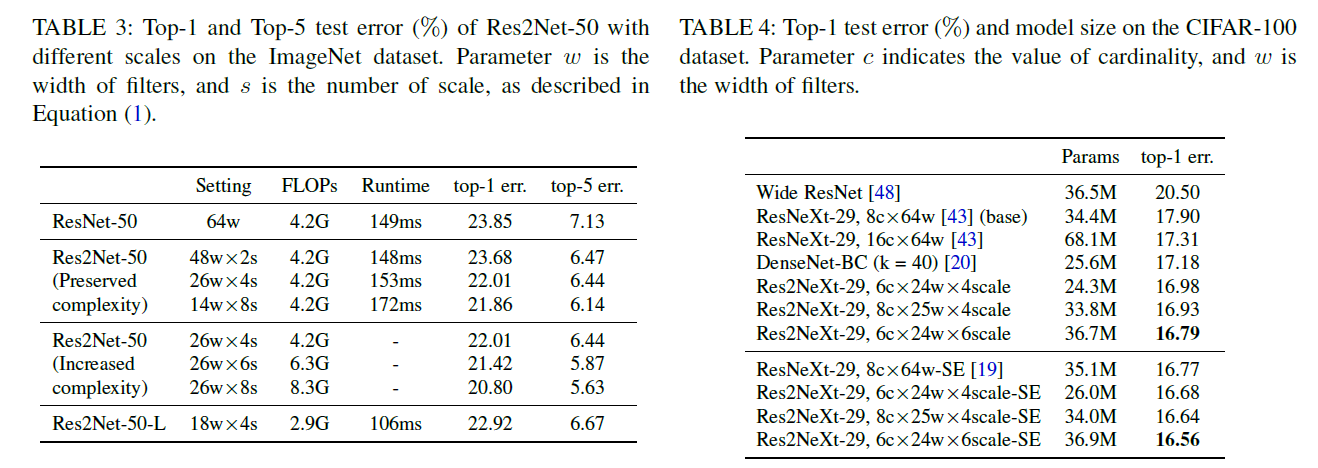
本文使用一个s作为控制尺寸维度的参数量。s越大,多尺寸表征能力更强,通过引入拼接操作,并未增加计算及内存消耗。如下图所示,Res2Net可以很方便的与现代模型进行结合。
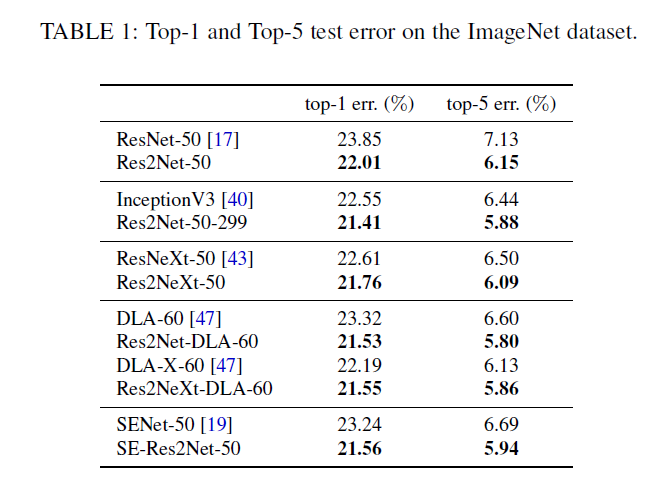
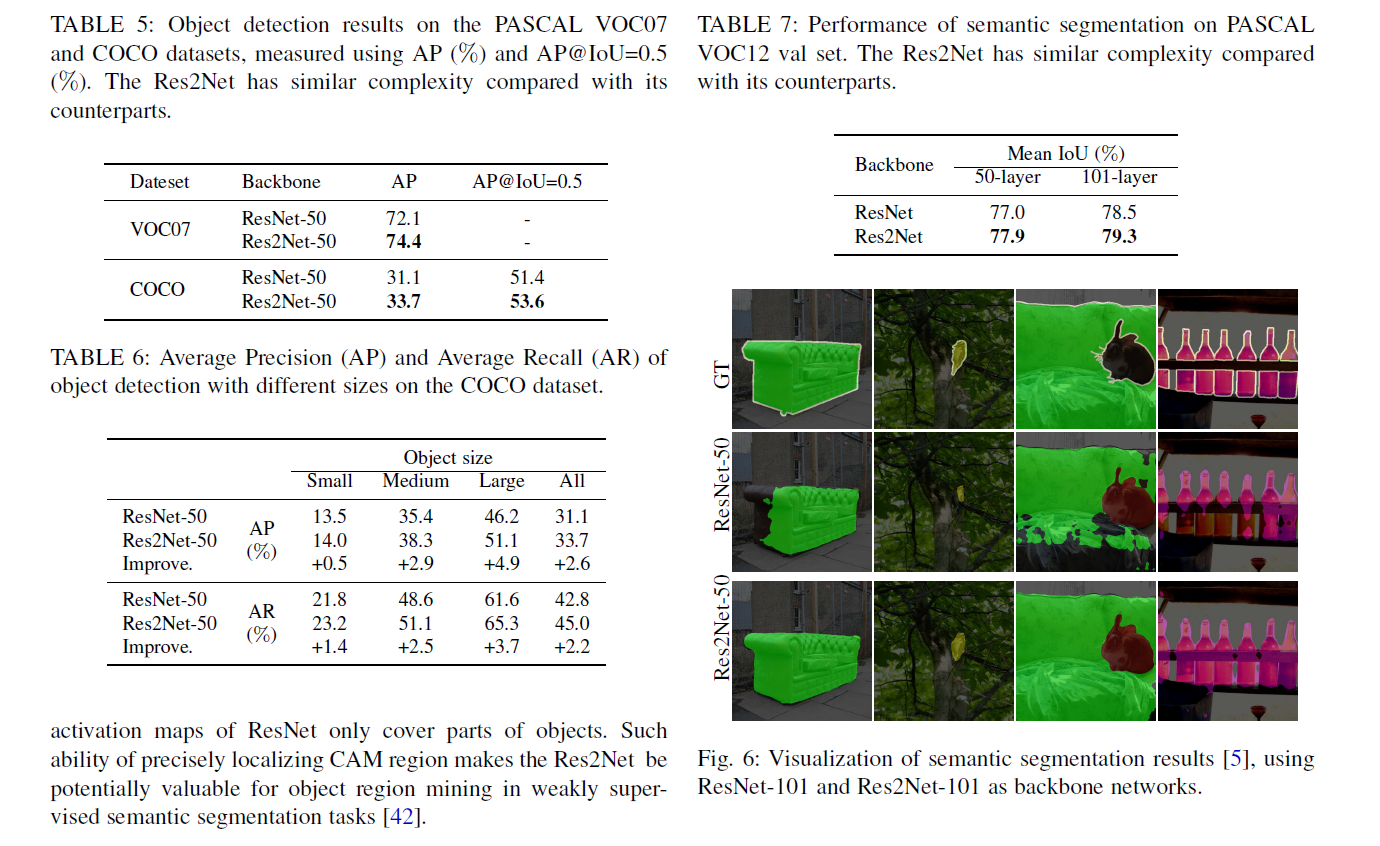
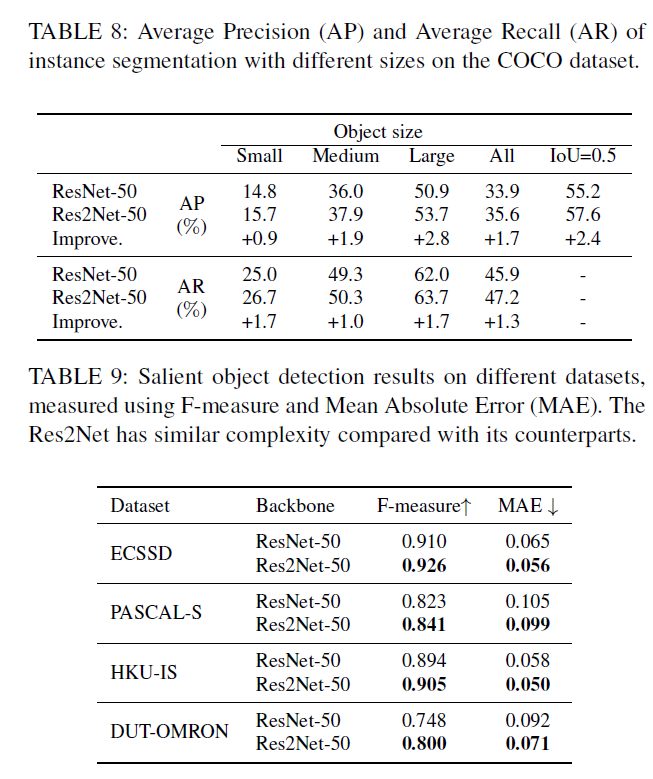
实验




Reference
[1] S. Belongie, J. Malik, and J. Puzicha. Shape matching and object recognition using shape contexts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(4):509–522, 2002.
[2] A. Borji, M.-M. Cheng, H. Jiang, and J. Li. Salient object detection: A benchmark. IEEE Transactions on Image Processing, 24(12):5706–5722, 2015.
[3] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille.Deeplab: Semantic image segmentation with deep convolutional nets,atrous convolution, and fully connected crfs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(4):834–848, 2018.