原创声明
本文作者:黄小斜
转载请务必在文章开头注明出处和作者。
本文思维导图
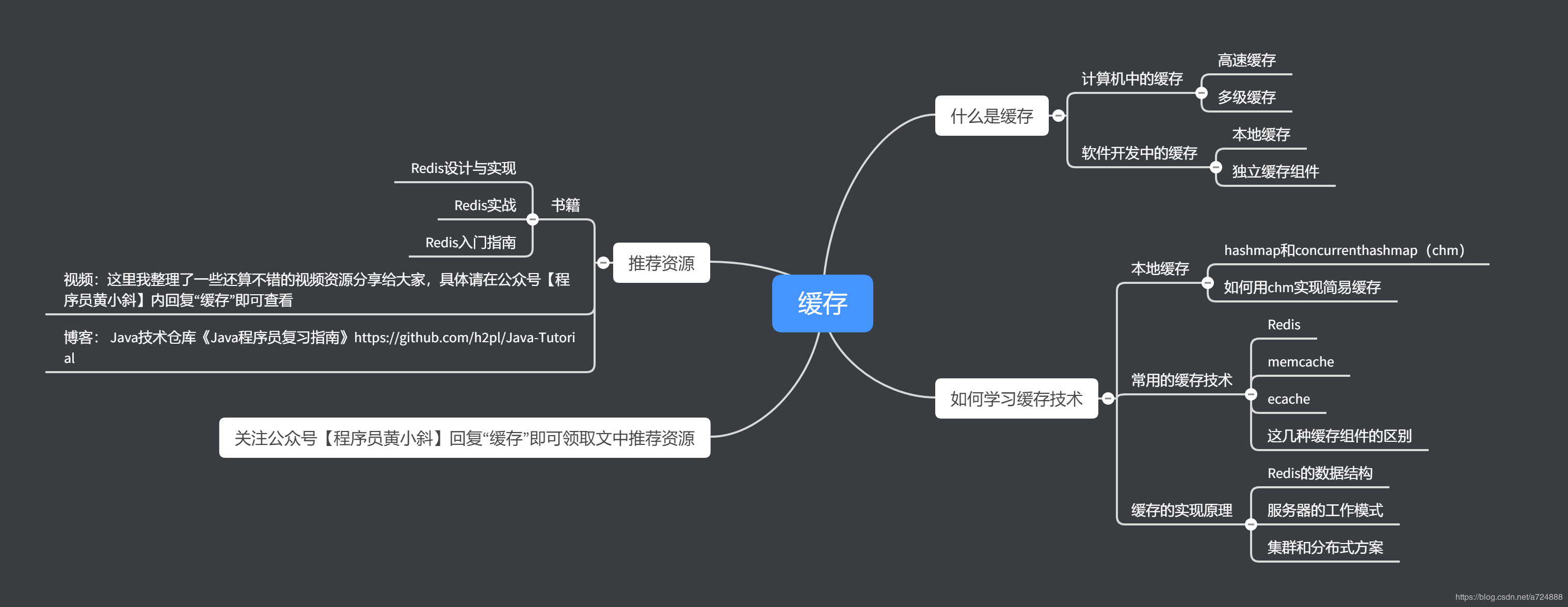
什么是缓存
计算机中的缓存
做后端开发的同学,想必对缓存都不会陌生了,平时我们可能会使用Redis,MemCache这类缓存组件,或者是本地缓存,来实现一些后端的应用。
那么,严格来说,到底什么才是缓存呢,先来看看百度百科的定义。
缓存(cache),原始意义是指访问速度比一般随机存取存储器(RAM)快的一种高速存储器,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。缓存的设置是所有现代计算机系统发挥高性能的重要因素之一。
最早,“缓存”一词是用来指代计算机硬件中的高速缓存,因为CPU和内存的运算速度差距过大,如果CPU直接和内存交互的话,会浪费掉CPU的大量运算时间,于是有了高速缓存,来为这两个速度差距甚远的组件做中介。
具体的工作原理是,CPU要取数据的时候,先找高速缓存要,由于它们俩的速度差距并不大,所以CPU不会损失掉太多性能,如果数据就在缓存中,那么就直接在缓存里取,否则则到内存去取,取完之后还要留在高速缓存中,以便于下次CPU要使用时无需再到内存中去取。
其实,高速缓存还可以分为一级缓存,二级缓存和三级缓存等,每往下一级,速度也就越慢,价格也越低,毕竟,成本是我们不得不考虑的因素,要不然一切硬件都上顶配,就不需要讨论软件的优化了。
除了高速缓存外,其实还有硬盘缓存、网络缓存等操作系统自身实现的缓存,目的也是为了在两个运算速度不同的组件之间建立一个桥梁,并且,缓存中的数据往往都是局部数据,又称热点数据,这部分数据经常被使用,因此更具有被缓存的价值
软件开发中的缓存
上面讲了一些关于计算机中已有的缓存,那么,我们平时在代码开发中用的缓存又是什么东西呢?好像不太一样啊。
相信大家都听过Redis,这是业界最流行的缓存组件之一,不妨看看它是如何被定义的。
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
根据上文的描述,我们可以看出,Redis是一个K/V的存储系统,并且它是把数据缓存在内存中的,大家都知道,内存比硬盘的速度要快得多,而我们平时经常使用的数据库,本质上还是基于硬盘IO来工作的,每次读写数据库都要经过硬盘的IO操作。
所以,读写数据库的耗时要比读内存要慢得多,刚刚我们说了,CPU读写内存和高速缓存的速度差异也很大,所以,这里Redis和高速缓存扮演了同一个角色,只不过一个是硬件,一个是软件,一个连接的是内存和CPU,另一个连接的是磁盘和内存。
除了Redis以外,还有很多缓存组件比如memcache也是基于这种方式来实现的,通过缓存数据库的热点数据,来提高应用的访问速率,在后端开发中是非常常见的一种技术应用。
如何学习缓存技术
作为一个后端开发工程师,不懂缓存是不行的,即使你天天做的是CRUD,至少也要会使用本地缓存吧。
另外,面试的时候经常也会有缓存方面的问题,简单点的,可能就让你说一说Redis的基础和实现原理,复杂点的,会结合场景,问你缓存可能引发的一些问题,又或者,分布式场景下的缓存如何设计。
从会使用到了解原理,再到学习进阶的用法,学习缓存和学习其他技术一样,需要先易后难,现在就让我们一起来看看,如何搞定缓存这个难缠的小妖精吧。
本地缓存chm
第一次接触缓存,其实是我在学习hashmap的时候,hashmap本身就是一个KV的键值对对象,和咱们刚刚说的Redis似乎有点像,那么,如何让hashmap真正变成一个缓存呢,其实也不难。
实际上,很多本地缓存就是直接用concurrenthashmap来实现的,注意,这里用的是支持并发的concurrenthashmap,这因为啊,缓存对象是可以支持多个线程同时访问的,如果出现同时put好的情况,就有可能出现异常,于是,使用concurrenthashmap就可以避免这种问题。
为了方便起见,后面对于concurrenthashmap简称chm。chm不仅可以保证对其访问是线程安全的,而且比直接用synchronized等关键字要更加高效灵活。
那么,chm实现缓存的原理是什么呢?首先,在应用中,缓存的本质就是把一些经常出现的数据存在内存中,而Java的内存又可以分为堆内存和栈内存,缓存对象自然是要放在堆内存中了。
所以它是一个类里的一个成员变量,比如这样。
private Map<String, CacheObj> CACHE_OBJECT_MAP = new ConcurrentHashMap<>();
但是这样使用缓存有一个问题,这个成员变量属于实例,如果实例没有初始化或者是被回收,那么这个缓存对象也就跟着消失了,那肯定是不行的,毕竟缓存的生命周期应该和应用本身一样长,另外,这个缓存对象还可能被修改,比如我可以在代码里随便操作一下,让它 = null,或者是重新初始化一下,那一样也是不被允许的。
所以,标准的chm本地缓存应该是这样被初始化的。
private static final Map<String, CacheObj> CACHE_OBJECT_MAP = new ConcurrentHashMap<>();
静态变量保证它一直存在于堆内存中,而final关键字修饰可以让它不会被重新初始化或者指向其他对象。
接下来的事情就简单了,你只要使用get和put方法就可以了。
当然,这只是最基础的本地缓存实现,还可以实现成LRU缓存,搞各种骚操作,这里我们不再具体讨论,网上有很多demo,可以自行去参考。
常用缓存组件实战
除了本地缓存之外,我们还应该去了解一些常用的缓存技术,比如Redis、memcache这类缓存组件,还有类似Ecache这类的Java缓存框架。
这类成熟的缓存技术,更加值得我们学习和使用,它们一般都能提供各个场景下的先进解决方案,比如如何处理热点数据,如何进行分布式部署,实现高可用,如何进行数据同步,主从复制,以及实现分布式锁、分布式ID生成器等各个场景的应用。
有一个面试题相信大家都遇到过,那就是问你redis和memcache的区别,我们不妨通过这个面试题来了解一下,到底它们都有些什么特点。
Redis不仅支持简单的k/v类型的数据,同时还支持list、set、zset(sorted set)、hash等数据结构的存储,使得它拥有更广阔的应用场景。
而Memcached唯一支持的数据类型是字符串string,非常适合缓存只读数据,因为字符串不需要额外的处理。
Redis最大的亮点是支持数据持久化,它在运行的时候可以将数据备份在磁盘中,断电或重启后,缓存数据可以再次加载到内存中,只要Redis配置的合理,基本上不会丢失数据。
这一点很要命,memcache不持久话数据,万一断电了就裂开。
Memcache在并发场景下,能用cas保证一致性,而Redis事务支持比较弱,只能保证事务中的每个操作连续执行。
虽然Redis支持事务而memcache不支持,但是memcache对并非的支持不亚于Redis。
性能方面,Redis在读操作和写操作上是略领先Memcached的。
Memcached的内存管理不像Redis那么复杂,元数据metadata更小,相对来说额外开销就很少。
对于制度数据来说,即使没有数据备份也没什么关系,但是如果存在读写,那么显然memcache是不合适的,整体来看,Redis还是略胜一筹。
Redis这类缓存组件其实是通过C/S方式部署服务的,而另一种缓存组件ecache,则是直接集成,缓存的数据就放在JVM里,有点类似于我们的本地缓存,其实ecache还应用在hibernate中,所以很多时候我们都是在不知情的情况下就已经使用了cache。
当然了,ecache这类缓存的数据放在JVM,要共享起来的话就比较麻烦了,特别是需要应用在分布式场景的时候,实现起来是比较复杂的。
缓存的实现原理
相信你在看了本地缓存那一部分的时候,会觉得缓存实现起来也没什么难度啊,一个hashmap就搞定了。
实际上,缓存的实现要考虑的问题还很多,就拿Redis来说,使用什么样的数据结构来存储数据就是很重要的一个问题,我们当然希望用尽量小的空间来存尽量多的数据,同时还要提升缓存CRUD的效率。
Redis中支持多种数据结构,比如字符串、数组、字典(map)以及列表、set、有序set等,别看这些数据结构很简单,但是作者实现起来都花了不少功夫。
往往一个结构有多种底层实现,目的就是为了压缩空间,提高效率。有兴趣的朋友可以看下这篇文章
Redis数据结构的底层实现https://blog.csdn.net/Future_LL/article/details/88525004
除了数据结构之外,Redis本身的实现也耐人寻味,比如,Redis的服务端和客户端是怎么设计的,另外,Redis是单线程工作的,为什么要这么设计,还有Redis的事务是如何实现的,这些内容都值得我们一一去学习了解。
另外还有一些进阶的内容,比如Redis的部署方案,通常包括主从部署、集群方案、HA方案等等,Redis官方也有Redis-cluster的高可用集群方案。Redis也常常用于分布式锁,分布式ID生成器,而这些技术的背后,其实都有很多值得我们深挖的点。
时间关系,我们今天就讲到这里,对于缓存和Redis的学习,就从这篇文章开始吧。
博客
Java技术仓库《Java程序员复习指南》
https://github.com/h2pl/Java-Tutorial
整合全网优质Java学习内容,帮助你从基础到进阶系统化复习Java
面试指南
全网最热的Java面试指南,共200多页,非常实用,不管是用于复习还是准备面试都是不错的。
在公众号【Java技术江湖】回复“PDF”即可免费领取。
写在最后
如果觉得本文对你有帮助的话,请你也不要吝啬你的“好看”哈,转发朋友圈就是对我最大的支持啦,你们的支持是对我最大的鼓励。
对本系列文章有什么建议和意见,也欢迎留言告诉我,期待你的回馈。