简介
管道机制实现了对全部步骤的流式化封装和管理(streaming workflows with pipelines)。
管道机制(也有人翻译为流水线学习器?这样翻译可能更有利于后面内容的理解)在机器学习算法中得以应用的根源在于,参数集在新数据集(比如测试集)上的重复使用。使用管道机制可以大幅度减少代码量.总的来说这是一个非常实用而有趣的方法
注意:管道机制更像是编程技巧的创新,而非算法的创新。
通常流水线学习器的通常步骤
数据标准化学习器=>特征选取学习器=>执行预测的学习器
除了最后一个学习器之外,所有学习器必须提供transform算法,该方法用于数据转换
常用方法与属性
Parameters
steps : 步骤:列表(list)
被连接的(名称,变换)元组(实现拟合/变换)的列表,按照它们被连接的顺序,最后一个对象是估计器(estimator)。memory:内存参数,Instance of sklearn.external.joblib.Memory or string, optional (default=None)
- 属性,name_steps:bunch object,具有属性访问权限的字典
只读属性以用户给定的名称访问任何步骤参数。键是步骤名称,值是步骤参数。或者也可以直接通过”.步骤名称”获取
funcution
- Pipline的方法都是执行各个学习器中对应的方法,如果该学习器没有该方法,会报错
假设该Pipline共有n个学习器
transform,依次执行各个学习器的transform方法
inverse_transform,依次执行各个学习器的inverse_transform方法
fit,依次对前n-1个学习器执行fit和transform方法,第n个学习器(最后一个学习器)执行fit方法
- predict,执行第n个学习器的predict方法
score,执行第n个学习器的score方法
set_params,设置第n个学习器的参数
- get_param,获取第n个学习器的参数
例子
一般步骤
- 首先对数据进行预处理,比如缺失值的处理
- 数据的标准化
- 降维
- 特征选择算法
- 分类或者预测算法(估计器,estimator)
流程图
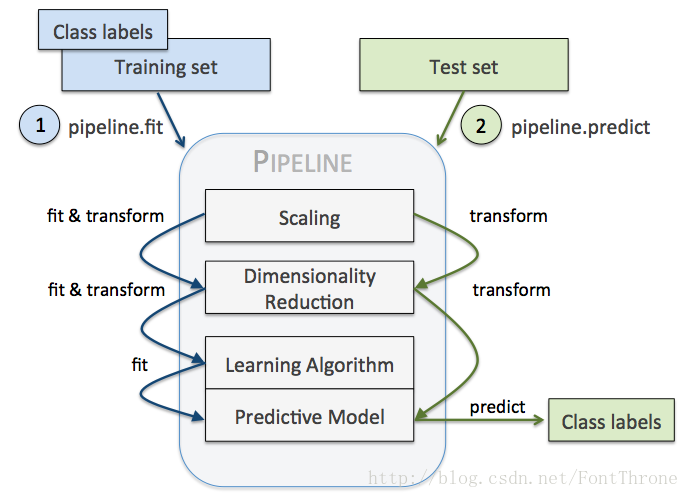
加载数据
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'
'breast-cancer-wisconsin/wdbc.data', header=None)
# Breast Cancer Wisconsin dataset
X, y = df.values[:, 2:], df.values[:, 1]
# y为字符型标签
# 使用LabelEncoder类将其转换为0开始的数值型
encoder = LabelEncoder()
y = encoder.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2, random_state=0)
利用Pipline合并算法流程
Pipline
def Examples_SklearnOrg_Pipline(X_train, X_test, y_train, y_test):
from sklearn import svm
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
anova_filter = SelectKBest(f_regression, k=5)
# clf = svm.LinearSVR(kernel='linear')
clf = svm.LinearSVC()
anova_svm = Pipeline([('sc', StandardScaler()),
('pca', PCA(n_components=2)),('anova', anova_filter), ('svc', clf)])
# You can set the parameters using the names issued
# For instance, fit using a k of all in the SelectKBest
# Because the PCA,we only have 2 features
# and a parameter 'C' of the svm
anova_svm.set_params(anova__k="all", svc__C=.1).fit(X_train, y_train)
# prediction_trian = anova_svm.predict(X_train)
# prediction_test = anova_svm.predict( X_test)
score_train = anova_svm.score(X_train, y_train)
score_test = anova_svm.score(X_test, y_test)
# print("prediction_train :", prediction_trian)
# print("prediction_test :", prediction_test)
print("score_train :", score_train)
print("score_test :", score_test)
# getting the selected features chosen by anova_filter
Pri_nameed_steps00 = anova_svm.named_steps['anova'].get_support()
print(Pri_nameed_steps00)
# Another way to get selected features chosen by anova_filter
Pri_nameed_steps01 = anova_svm.named_steps.anova.get_support()
print(Pri_nameed_steps01)
UCI_sc_pca_logisticRe(X_train, X_test, y_train, y_test)
Examples_SklearnOrg_Pipline(X_train, X_test, y_train, y_test)
输出:
score_train : 0.964835164835
score_test : 0.921052631579
[ True True]
[ True True]
参考
- sklearn 中的 Pipeline 机制 - Inside_Zhang
- << Python 大战机器学习 数据科学家的一个小目标 >> 华校专,王正林 2017.03
- sklearn:官方网站:http://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html#sklearn.pipeline.Pipeline