2019年10月4日记录
public int[] TwoSum(int[] nums, int target)
{
Dictionary<int, int> dic = new Dictionary<int, int>();
for (int i = 0; i < nums.Length; i++)
{
int temp = target - nums[i];
if (dic.ContainsKey(temp))
{
return new int[] { dic[temp], i };
}
if (!dic.ContainsKey(nums[i]))
{
dic.Add(nums[i], i);
}
}
return null;
}
def two_sum(nums, target):
dic = {}
for i, n in enumerate(nums):
if target - n in dic:
return [dic[target - n], i]
dic[n] = i
-
List是顺序线性表(非链表),用一组地址连续的存储单元依次存储数据元素的线性结构,在c#中,我们实例化list时,如果不指定容量,则内部会生成一个静态的空数组,有添加操作时,实例化为一个长度为4的数组,满了以后,自动扩充为两倍的容量 -
哈希表也叫散列表,是一种通过把关键码值映射到表中一个位置来访问记录的数据结构。c#中的哈希表有
Hashtable,Dictionary,Hashtable继承自Map,实现一个key-value映射的关系。Dictionary则是一种泛型哈希表,不同于Hashtable的key无序,Dictionary是按照顺序存储的。哈希表的特点是:1.查找速度快,2.不能有重复的key。 默认生成一个长度为11的哈希表,满后,自动添加,而添加规则是内部循环素数数组,稍大于当前的长度,比如15,则长度设定为17。在哈希表创建可分为确定哈希函数,解决哈希冲突两个步骤
- 哈希表比list需要花费更多的时间建立数据结构,这是因为哈希表花费时间去解决哈希冲突,而list不需要。但需要注意的是建立操作只需要执行一次。
- 哈希表的查找速度几乎不需要花费时间,这是因为哈希表在添加一对元素(key-value)时,就已经记录下value的位置,所以查找时就会非常的快。哈希的查找复杂度O(1),list 的查找复杂度是O(n)。
哈希表的高速查找是空间换时间的典型应用,前期的建立时间随着数量级的增加而增加,后期的查找则永远是O(1)。所以我们得出结论:如果面对海量数据,且需要大量搜索,那建议使用哈希表。而当面对小量数据(数量级由服务器决定)时,使用List更合适。
最后友情提醒:第一,虽然在查找上哈希占有优势,但不足的是1.占有空间大,2.不能有重复健。第二,如果需要使用哈希表,建议多使用Dictionary。Dictionary的运行时间比hashtable稍快,而且Dictionary是类型安全的,这有助于我们写出更健壮更具可读性的代码,省去我们强制转化的麻烦。Dictionary是泛型的,当K或V是值类型时,其速度远远超过Hashtable
-
HashTable
哈希表(HashTable)表示键/值对的集合。在.NET Framework中,Hashtable是System.Collections命名空间提供的一个容器,用于处理和表现类似key-value的键值对,其中key通常可用来快速查找,同时key是区分大小写;value用于存储对应于key的值。Hashtable中key-value键值对均为object类型,所以Hashtable可以支持任何类型的keyvalue键值对,任何非 null 对象都可以用作键或值。 -
HashSet
HashSet<T>类主要是设计用来做高性能集运算的,例如对两个集合求交集、并集、差集等。集合中包含一组不重复出现且无特性顺序的元素,HashSet拒绝接受重复的对象。
HashSet<T>的一些特性如下:HashSet<T>中的值不能重复且没有顺序。HashSet<T>的容量会按需自动添加。
-
Dictionary
Dictionary表示键和值的集合。
Dictionary<string, string>是一个泛型
他本身有集合的功能有时候可以把它看成数组
他的结构是这样的:Dictionary<[key], [value]>
他的特点是存入对象是需要与[key]值一一对应的存入该泛型
通过某一个一定的[key]去找到对应的值 -
HashTable和Dictionary的区别:HashTable不支持泛型,而Dictionary支持泛型。Hashtable的元素属于Object类型,所以在存储或检索值类型时通常发生装箱和拆箱的操作,所以你可能需要进行一些类型转换的操作,而且对于int,float这些值类型还需要进行装箱等操作,非常耗时。- 单线程程序中推荐使用
Dictionary, 有泛型优势, 且读取速度较快, 容量利用更充分。多线程程序中推荐使用Hashtable, 默认的Hashtable允许单线程写入, 多线程读取, 对Hashtable进一步调用Synchronized()方法可以获得完全线程安全的类型. 而Dictionary非线程安全, 必须人为使用lock语句进行保护, 效率大减。 - 在通过代码测试的时候发现
key是整数型Dictionary的效率比Hashtable快,如果key是字符串型,Dictionary的效率没有Hashtable快。
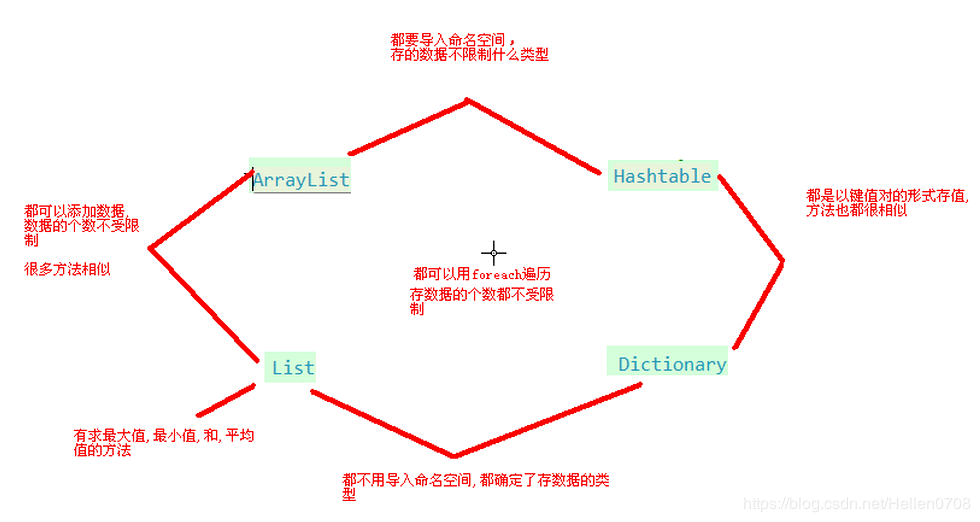
ArrayList,List,HashTable,Dictionary四者的区别与联系