在使用Exists时,如果能正确使用,有时会提高查询速度:
1,使用Exists代替inner join
2,使用Exists代替 in
1,使用Exists代替inner join例子:
在一般写sql语句时通常会遇到如下语句:
两个表连接时,取一个表的数据,一般的写法通过关联查询(inner join):
select a.id, a.workflowid,a.operator,a.stepid
from dbo.[[zping.com]]] a
inner join workflowbase b on a.workflowid=b.id
and operator='4028814111ad9dc10111afc134f10041'
from dbo.[[zping.com]]] a
inner join workflowbase b on a.workflowid=b.id
and operator='4028814111ad9dc10111afc134f10041'
查询结果:
(1327 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 293 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 293 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
还有一种写法使用exists来取数据
select a.id,a.workflowid,a.operator ,a.stepid
from dbo.[[zping.com]]] a where exists
(select 'X' from workflowbase b where a.workflowid=b.id)
and operator='4028814111ad9dc10111afc134f10041'
from dbo.[[zping.com]]] a where exists
(select 'X' from workflowbase b where a.workflowid=b.id)
and operator='4028814111ad9dc10111afc134f10041'
执行结果:
(1327 行受影响)
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 291 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 291 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里两着的IO次数,EXISTS比inner join少 2个IO, 对比执行计划成本不一样, 看看两着的差异:
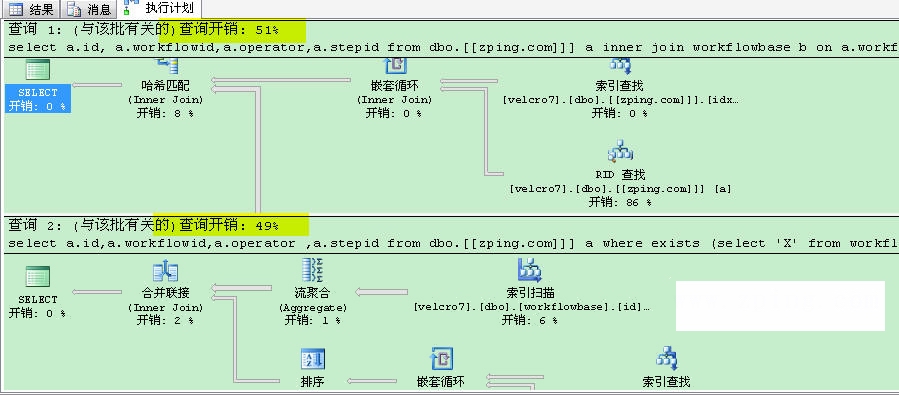
这时我们发现使用EXISTS要比inner join效率稍微高一下。
2,使用Exists代替 in
要求:编写workflowbase表中id不在表中dbo.[[zping.com]]]的行:
一般的写法:
select * from workflowbase
where id not in (
select a.workflowid
from dbo.[[zping.com]]] a )
where id not in (
select a.workflowid
from dbo.[[zping.com]]] a )
执行结果:

(1 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 5,逻辑读取 56952 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
使用Existsl来写:
select * from workflowbase b
where not exists(
select 'X'
from dbo.[[zping.com]]] a where a.workflowid=b.id )
where not exists(
select 'X'
from dbo.[[zping.com]]] a where a.workflowid=b.id )
看看执行结果
(1 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 3,逻辑读取 18984 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 3,逻辑读取 18984 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
两个io的差距:56952+1589=58541次 (使用IN)
18984+1589=20573次 (使用Exists)
使用exists是in的2.8倍,查询性能提高很大。
EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。