一、I/O库函数
1.I/O库函数与系统调用
系统调用函数:open()、read()、write()、lseek()、close()
I/O库函数:fopen()、fread()、fwrite()、flseek()、fclose()
每个I/O库函数的根都在对应的系统调用函数中
2.fread算法
(1)在第一次调用fread(时,FILE结构体的缓冲区是空的,fread()使用保存的文件描述符fd发出一个
n=read(fd,fbuffer,BLKSIZE);
系统调用,用数据块填充内部的fbuf[]。然后,它会初始化fbuf[]的指针、计数器和状态变量以表明内部缓冲区中有一个数据块。接着,通过将数据复制到程序的缓冲区,尝试满足来自内部缓冲区的fread()调用。如果内部缓冲区没有足够的数据,则会再发出一个read()系统调用来填充内部缓冲区,将数据从内部缓冲区传输到程序缓冲区,直到满足所需的字节数(或者文件无更多数据)。将数据复制到程序的缓冲区之后,它会更新内部缓冲区的指针、计数器等,为下一个fread()请求做好准备。然后,它会返回实际读取的数据对象数量。
(2)在随后的每次fread()调用中,它都尝试满足来自FILE结构体内部缓冲区的调用。当缓冲区变为空时,它就会发出read()系统调用来重新填充内部缓冲区。因此,fread()一方面接受来自用户程序的调用,另一方面向操作系统内核发出read()系统调用。除了read()系统调用之外,所有fread()处理都在用户模式映像中执行。它只在需要时才会进入操作系统内核,并且以一种最高效匹配文件的方式进人。它会提供自动缓冲机制,因此用户程序不必担心这些具体操作。
3.fwrite算法
与fread()算法类似,只是数据的传输方向不同
4.fclose算法
若文件以写的方式被打开,fclose()会先关闭文件流的局部缓冲区。然后,它会发出一个close(fd)系统调用来关闭FILE结构体中的文件描述符。最后,它会释放FILE结构体并将FILE指针重置为NULL.
5.I/O库模式
fopen()中的模式参数可以指定为:"r"、" w"、"a”,分别代表读、写、追加。每个模式字符串可包含一个+号,表示同司时读写,或者在写入、追加情况下,如果文件不存在则创建文件。
"r+":表示读/写,不会截断文件。
"w+":表示读/写,但是会先截断文件; 如果文件不存在,会创建文件。
"a+":表示通过追加进行读/写;如果文件不存在,会创建文件。
(1)字符模式I/O
int fgetc(FILE *fp);//返回的是整数
int ungetc(int c,FILE *fp);
int fputc(int c,FILE *fp);
(2)行模式I/O
char *fgets(char *buf,int size,FILE *fp):从fp中读取最多为一行(以
结尾)的字符。
int fputs(char *buf,FILE *fp):将buf中的一行写入fp中。
(3)格式化1/O
格式化输入:(FMT=格式字符串)
scanf(char *FMT,&items);
fscanf(fp,char *FMT,&items);
格式化输出:
printf(char *FMT,items);
fprintf(fp,char *FMT,items);
(4)内存中的转换函数
sscanf(buf,FMT,&items);
sprintf(buf,FMT,items);
sscanf()和sprintf()并非I/0函数,而是内存中的数据转换函数。
(5)其他I/O库函数
fseek()、ftell()、rewind():更改文件流中的读/写字节位置。
feof()、ferr()、fileno():测试文件流状态。
fdopen():用文件描述符打开文件流。
freopen():以新名称重新打开现有的流。
setbuf()、setvbuf():设置缓冲方案。
popen():创建管道,复刻子进程来调用sh。
(6)限制混合fread-fwrite
当某文件流同时用于读/写时,就会限制使用合fread()和fwrite()调用。规范要求每对fread()和fwrite()之间至少有一个fseek()或ftell()
6.文件流缓冲
每个文件流都有一个FILE结构体,其中包含一个内部缓冲区。对文件流进行读写需要遍历FILE结构体的内部缓冲区。文件流可以使用三种缓冲方案中的一种。
无缓冲:从非缓冲流中写入或读取的字符将尽快单独传输到文件或从文件中传输。
行缓冲:遇到换行符时,写入行缓冲流的字符以块的形式传输。
全缓冲:写入全缓冲流或从中读取的字符以块大小传输到文件或从文件传输。这是文件流的正常缓冲方案。
7.myprintf()的算法
假设格式字符串fmt=“char=%c string=%s integer=%d u32=%x
”。这意味着分别有 char、char*、int、unsigned int和type的4个附加参数。myprint()的算法如下:
(1)扫描格式字符串fmt。打印任何不是%的字符。对于每个‘n’字符,打印一个额外的'
字符。
(2)当遇到‘%’时,得到的下一个字符必须是‘c’、‘s’、‘u’、‘d’或‘x’中的一个。使用va_arg(ap,type)来提取相应的参数。然后后通过参数类型调用打印函数。
(3)当fmt字符串扫描结束时,算法结束。
二、问题与解决思路
1.关于Linux中文件的相关知识
不太明白Linux中的文件到底怎么一个存在,每个文件夹都储存什么,于是查了资料,找到了一张形象的图说明Linux中的文件系统
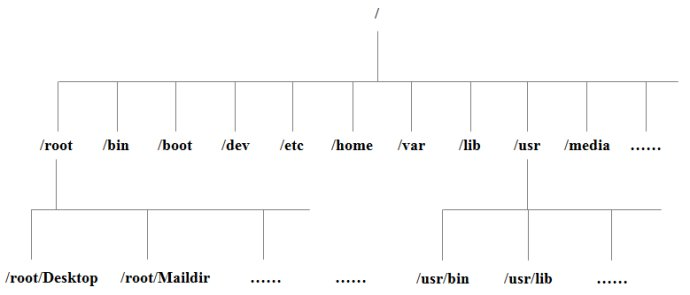
主要文件夹的说明如下:
/bin:bin是Binary的缩写, 这个目录存放着最经常使用的命令。包括用户管理员命令,如:cat,chmod,cp,date,ls
/boot:这里存放的是启动Linux时使用的一些核心文件,包括一些连接文件以及镜像文件。
/dev:dev是Device(设备)的缩写, 该目录下存放的是Linux的外部设备,在Linux中访问设备的方式和访问文件的方式是相同的。
/etc:这个目录用来存放所有的系统管理所需要的配置文件和子目录。
/home:用户的主目录,在Linux中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的。
/lib:这个目录里存放着系统最基本的动态连接共享库,其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。如:c/c++等库文件 其他大部分文件存放在/usr/lib下
/root:该目录为系统管理员,也称作超级权限者的用户主目录。
/sbin:s就是Super User的意思,这里存放的是系统管理员使用的系统管理程序。
/srv:该目录存放一些服务启动之后需要提取的数据。
/tmp:这个目录是用来存放一些临时文件的。
/usr:这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于windows下的program files目录。
/usr/bin:系统用户使用的应用程序。
/usr/sbin:超级用户使用的比较高级的管理程序和系统守护程序。
/usr/src:内核源代码默认的放置目录。
其中,/etc,/bin,/sbin,/usr/bin,/usr/sbin比较重要
2.文本文件与二进制文件
不知道为什么以前只关注文本文件的操作,以后更多的是操作二进制文件。于是我上网查了文本文件和二进制文件的主要区别:
(1)能存储的数据类型不同
文本文件只能存储char型字符变量。二进制文件可以存储char/int/short/long/float/……各种变量值。
(2)每条数据的长度
文本文件每条数据通常是固定长度的。以ASCII为例,每条数据(每个字符)都是1个字节。进制文件每条数据不固定。如short占两个字节,int占四个字节,float占8个字节……
(3)读取的软件不同
文本文件编辑器就可以读写。比如记事本、NotePad++、Vim等。二进制文件需要特别的解码器。比如bmp文件需要图像查看器,rmvb需要播放器……
(4)操作系统对换行符(‘ ’)的处理不同
文本文件,操作系统会对’ ’进行一些隐式变换,因此文本文件直接跨平台使用会出问题。在Windows下,写入’ ’时,操作系统会隐式的将’ ’转换为“ ”,再写入到文件中;读的时候,会把“ ”隐式转化为“ ”,再读到变量中。在Linux下,写入“ ”时,操作系统不做隐式变换。二进制文件,操作系统不会对“ ”进行隐式变换,很多二进制文件(如电影、图片等)可以跨平台使用。
由上面四条可知,二进制文件的约束性更小,能储存的变量更多,而且可以跨平台使用,这可能就是我们以后要更多的关注二进制文件操作的原因。
三、知识点归纳以及自己最有收获的内容
这一章主要复习了C语言的I/O库函数,之前学C语言的时候基础没打太好,所以现在学起来会有些吃力,自学完这一章最有收获的是大概看懂了I/O库函数的操作,虽然还是有点抽象,但是比起原来好了很多。另外还上网搜了资料,弄清楚了文本文件和二进制文件的区别。以前对电脑进行操作的时候总是涉及到好多文件夹,一直没懂哪个文件夹管什么东西,这次查资料也弄清了。但是我感觉自学还是有一定的漏洞,希望上课的时候能学到更多。