0.分类模型评价指标在数据挖掘中的位置:

一、混淆矩阵(Confusion Matrix):
1.混淆矩阵其实就是一张表格,可以用来评判分类模型的精度,形式如下:
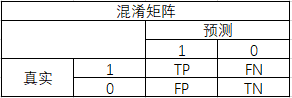
2.混淆矩阵延伸出的指标有二级指标有
i)准确率(accuracy):
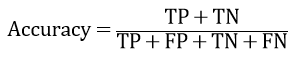
ii)精确率 (precision):
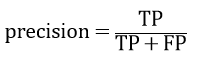
iii)召回率 (recall)(也叫灵敏度 sensitivity):
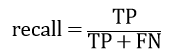
iv)特异度 (specificity)
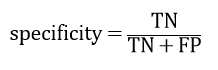
3.混淆矩阵延伸出的指标有三级指标有
F1指标(F1_score):
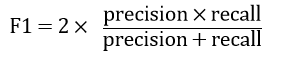
4.其余指标:

二、ROC曲线

横轴FPR:False Positive Rate=FP/(FP+TN) ;【混淆矩阵第二行】
纵轴TPR:True Positive Rate=TP/(TP+FN) ;【混淆矩阵第一行】
ROC曲线理解:
1.曲线越贴近纵轴,TPR越高,分类效果越好;
曲线越贴近横轴,FPR越高,分类效果越差;
曲线越靠近左上方,分类效果越好;
图中分类效果:蓝色>红色>绿色
2.图中灰色线(45°)为基准线(benchmark),表示50%的预测准确率;
3.ROC曲线绘制:
曲线的每一个点代表取某个特定阈值p时,模型的分类表现;
阈值p含义:给定阈值p,若输入某样本,输出属于类别一的概率>p,则该样本属于类别一。
整条曲线代表取不同阈值p时的模型分类表现。
三、AUC面积(Area Under Curve)
AUC面积就是ROC的曲线下面积;
AUC越接近1,模型分类效果越好。
若AUC<0.5,则模型分类效果不如50%/50%的猜测。
参考资料:
1.分类评价指标:混淆矩阵:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839,作者:Orange_Spotty_Cat
2.分类评价指标:ROC曲线与AUC面积:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80499031?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase,作者:Orange_Spotty_Cat
3.机器学习:了解混淆矩阵:https://blog.csdn.net/qq_39521554/article/details/79995949,作者:图灵的猫