为了改进性能,分析重编译的起因很重要。往往,重编译可能并不需要,可以避免它以改进性能。了解导致重编译发生的不同条件有助于评估重编译的起因,并决定在重编译不必要时避免它的方法。
存储过程重编译在以下情况下发生:
- 存储过程语句中引用的常规表、临时表或视图的架构变化。架构变化包括表的元数据或表上索引的变化;
- 常规或临时表的列上的绑定(如默认/规则)变化。
- 表索引或列上的统计的变化超过一定的阈值。
- 存储过程编译时一个对象不存在,但是在执行期间创建(延迟对象解析);
- SET选项变化;
- 执行计划老化并释放;
- 对sp_recompile系统存储过程的显式调用。
- 显式使用RECOMPILE子句;
可以在Profiler中看到这些变化。原因由SP:Recompile事件的EventSubClass数据列值指出:
| EventSubClass | 描述 |
| 1 | 常规表或试图的结构或绑定变化 |
| 2 | 统计变化 |
| 3 | 在执行期间创建存储过程计划中不存在的对象 |
| 4 | SET选项变化 |
| 5 | 临时表架构或绑定变化 |
| 6 | 远程行集的架构或绑定变化 |
| 7 | FOR BROWSE许可变化 |
| 8 | 查询通知环境变化 |
| 9 | MPI视图变化 |
| 10 | 游标选项变化 |
| 11 | 调用WITH RECOMPILE选项 |
一、架构或绑定变化
当一个视图、常规表或临时表的架构或绑定变化时,现有的存储过程执行计划将作废。执行任何引用这些对象的语句之前该存储过程必须重编译。SQL Server自动侦测这种情况并且重编译存储过程。
因此,要避免架构变化,尽量不要在存储过程中涉及到临时表,索引,字段的操作,即不要交替使用DML、DDL语句。
在存储过程中,DDL语句通常用于创建局部临时表以及修改他们的架构(包括添加索引)。这样做可能影响现有计划的有效性,并且可能在引用该表的存储过程语句被执行时导致重编译。
如:
CREATE PROC sp_Test
AS
CREATE TABLE #TB1(ID INT,DSC NVARCHAR(50))
INSERT INTO #TB1(ID,DSC)
SELECT TOP 100 ID,NAME FROM PersonTenThousand; --第1次重编译
SELECT * FROM #TB1 AS TT --第2次重编译
CREATE CLUSTERED INDEX IXID ON #TB1(ID);
SELECT TOP 10 * FROM #TB1; --第3次重编译
CREATE TABLE #TB2(c1 INT);
SELECT * FROM #TB2; --第4次重编译
GO
EXEC sp_Test
GO
EXEC sp_Test
SQL Server Profiler跟踪输出:
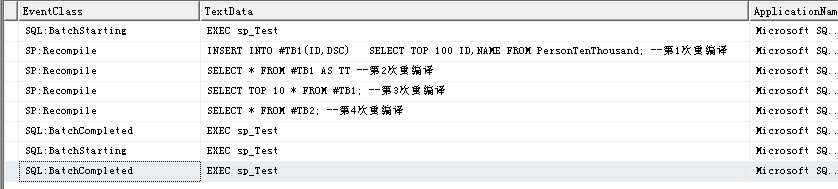
可以看到存储过程被重编译4次。
- 第一次重编译来自于多了个表#TB1,现有自行计划不包含表#TB1的任何信息。
- 第二次重编译来自于临时表数据的变化;
- 第三次重编译来自于临时表架构变化,多了个索引;
- 第四次冲编译多了表#TB2,因为是新建的表,现有执行计划没有关于#TB2的任何信息;
二、统计变化
SQL Server记录表的变化数量。如果变化数量超过重编译阈值(RT),SQL Server自动在存储过程中引用该表时更新统计。当侦测到自动更新统计的条件时,SQL Server自动重新编译存储过程并更新统计。
RT由一组取决于表是永久表或临时表(不是表变量)以及表中的行数的公式来确定。表10-3显示了基本的公式,可以确定由于数据变化引起的语句重编译预期时间。
| 表类型 | 公式 |
| 永久表 |
如果n(行数)<=500,则RT=500; 如果n>500,则RT=500+.2*n |
| 临时表 |
如果n<6,则RT=6; 如果6<=n<=500,则RT=500; 如果n>500,则RT=500+.2*n |
统计变化引起的重编译可能生成一个和前一个计划相同的计划,在这种情况下,重编译是没有必要的,如果开销较大则应避免。
避免统计的变化而引起的重编译有两个方法:
- 使用KEEPFIXED PLAN选项;
- 禁用该表上的自动更新统计特性;
1、使用KEEPFIXED PLAN选项
SQL Server提供KEEPFIXED PLAN选项来避免因为统计变化引起的重编译。
CREATE PROC GetPerson
AS
SELECT * FROM Person
WHERE Id = 1
OPTION(KEEPFIXED PLAN);
如,像上面这种写法,执行存储过程就不会再因为表Person上的统计变化而引起重编译。
2、禁用表上的自动更新统计
也可以通过禁用相关表上的自动更新统计来避免统计更新引起的重编译。(不过这种方法就好比,脚疼就把整个脚砍掉,不可取)。
例如,可以关闭表Person上的自动更新统计
EXEC sp_autostats 'Person','OFF'
虽然这种方式可以避免重编译,但是使用这种技术应该非常小心,因为过时的统计可能对基于开销的优化器有负面的影响,如果禁用统计的自动更新,应该有一个定期更新统计的SQL任务。
三、延迟对象解析
存储过程通常动态创建然后访问数据库对象。当这样的存储过程第一次执行时,第一个执行计划不包含关于运行时创建的对象的信息。因此,在第一个执行计划中,对这些对象的处理策略被延迟到存储过程的运行时。
当执行一个引用这些对象的DML语句时,存储过程被重新编译以生成一个包含该对象处理策略的新计划。
在存储过程中可以创建常规表和局部临时表来保存中间结果。由于延迟对象解析引起的存储过程重编译对于常规表和局部临时表来说有所不同。
1、由于常规表引起的重编译
为了理解在存储过程中创建常规表所致的存储过程重编译问题,考虑以下实例:
CREATE PROC dbo.p1
AS
CREATE TABLE dbo.p1_t1(c1 INT); --存储过程开始时表不存在
SELECT * FROM dbo.p1_t1; --导致重编译
DROP TABLE dbo.p1_t1 --结束后删除该表
GO
EXEC dbo.p1 --第一次执行
EXEC dbo.p1 --第二次执行
SQL Server Profiler输出:
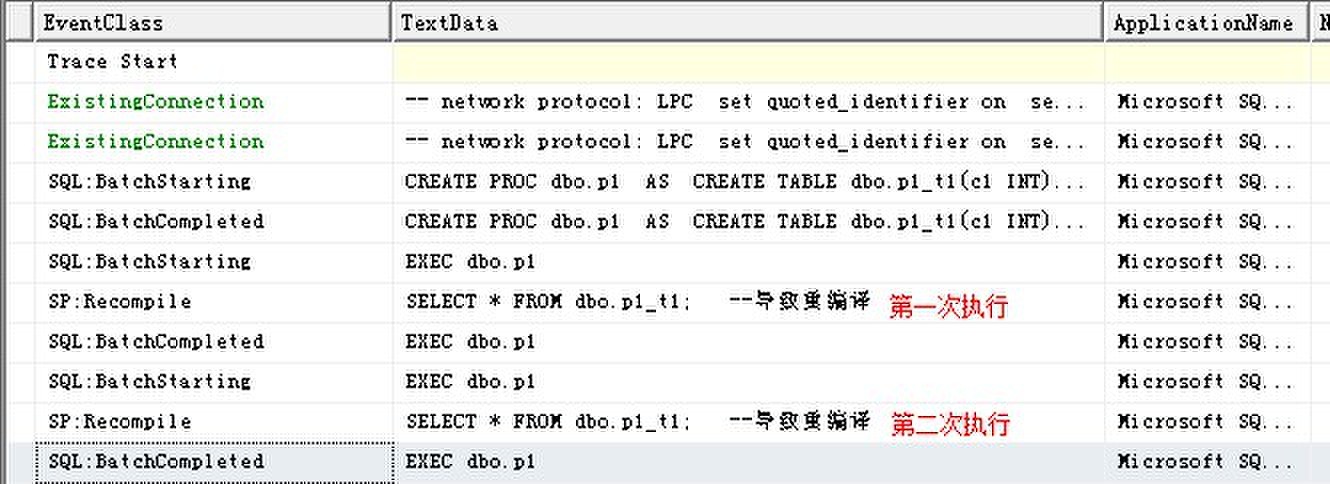
第一次执行该存储过程时,执行计划在存储过程实际执行之前生成。
但是如果在存储过程创建之前存储过程中创建的表不存在,引用该表的SELECT语句尚不会有执行计划。因此为了执行SELECT语句,存储过程必须重编译。可以看到,在第二次执行时SELECT语句被重编译,在第一次执行期间卸载存储过程中的表并没有卸载保存在过程缓冲中的存储过程计划。SQL Server考虑为其表架构的一次变化,因此SQL Server在存储过程后执行SELECT语句之前重新编译存储过程。因此,看到第一次的重编译依然发生在BatchStarting之后。
2、由于局部临时表引起的重编译
大部分时候,在存储过程中创建局部临时表而不是常规表。为了礼节局部临时表对存储过程重编译的不同影响,修改前面的实例,只用一个临时表替换常规表。
CREATE TABLE dbo.p1
AS
CREATE TAVLE #p1_t1(c1 INT) --指定本地临时表
SELECT * FROM #p1_t1 --在第一次执行时导致重编译
DROP TABLE #p1_t1
GO
EXEC dbo.p1 --第一次执行
EXEC dbo.p1 --第二次执行
因为局部临时表在存储过程执行结束时自动卸载,所有没有必要明确地卸载临时表。但是,在局部临时表工作完成之后马上卸载它是一个好的编程习惯。
最好分开点击,这样SQL Server Profiler生成的监控比较清晰:
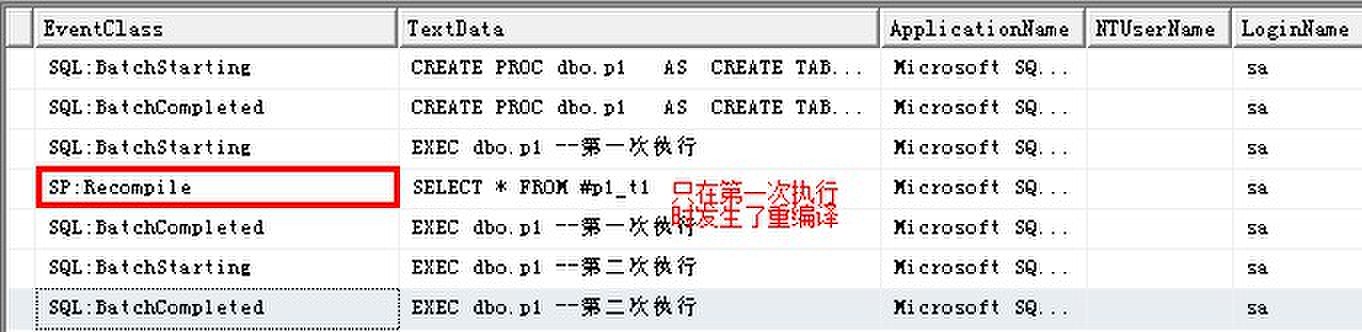
从监控输出可以看到,第一次执行时存储过程被重编译。对应的EventSubClass值支出的重编译起因和常规表上的一样,但是,存储过程在重新执行时不被重编译,这和常规表不同。
存储过程后续执行期间的局部临时表架构与前一次执行时保持一致。局部临时表不可用于存储过程的范围之外,所以其架构无论执行多少次都是一致的,因此,SQL Server在存储过程后续执行期间确定能安全地重用现有计划,避免了重编译。
临时表会引起存储过程重编译,想要避免可以使用表变量代替。
四、SET选项变化
在存储过程的执行计划取决于环境设置。如果环境设置在存储过程中变化,则SQL Server在每次执行时重编译存储过程。
CREATE PROC dbo.p1
AS
SELECT 'a' + null + 'b'; --第一次拼接
SET CONCAT_NULL_YIELDS_NULL OFF;
SELECT 'a' + null + 'b'; --第二次拼接
SET ANSI_NULLS OFF;
SELECT 'a' + null + 'b'; --第三次拼接
GO
EXEC dbo.p1 --第一次执行
EXEC dbo.p1 --第二次执行
SQL Server Profiler输出如下:

因为SET NOCOUNT没有修改环境设置,不像前面看到的用于修改ANSI设置的SET语句,SET NOCOUNT不会导致存储过程重编译。
在存储过程中修改SET选项导致SQL Server在执行SET语句后面的语句之前重编译该存储过程。因此,这个存储过程分别在SET语句后被重编译两次。
但如果在这之后,在执行存储过程:
EXEC dbo.p1 --第三次执行
EXEC dbo.p1 --第四次执行
EXEC dbo.p1 --第五次执行
都不会再重编译,因为那些内容现在已经成为了执行计划的一部分。
因此,如果想要避免由于SET选项变化引起的存储过程重编译时,尽量不要在存储过程中设置SET选项。
另外,SET NOCOUNT选项是一个例外,它没有修改环境设置,不像前面示例中的那样会导致重编译。
五、执行计划老化
SQL Server通过维护缓冲中执行计划的寿命来管理过程缓冲的大小,如果一个存储过程长时间未被重新执行,执行计划的寿命字段将下降为0,内存短缺时将把该计划从缓冲中删除。当这种情况发生并且存储过程被重新执行时,将生成一个新计划并将其缓冲到过程缓冲中。但是,如果系统中有足够的内存,未使用的计划在内存压力增加之前不会被删除。
六、显式调用sp_recompile系统存储过程
SQL Server还提供了sp_recompile系统存储过程来手工标记需要重编译的存储过程。这个系统存储过程可以在表、视图、存储过程或触发器上调用。如果在存储过程或触发器上调用,则该存储过程或触发器在下次执行时被重编译。在表或视图上调用标记所有调用该表/视图的存储过程和触发器在下次执行时重新编译。
如在表Person上调用sp_recompile,则所有调用Person表的存储过程和触发器被标记为需要重编译,在下次执行时重新编译:
sp_recompile 'Person'
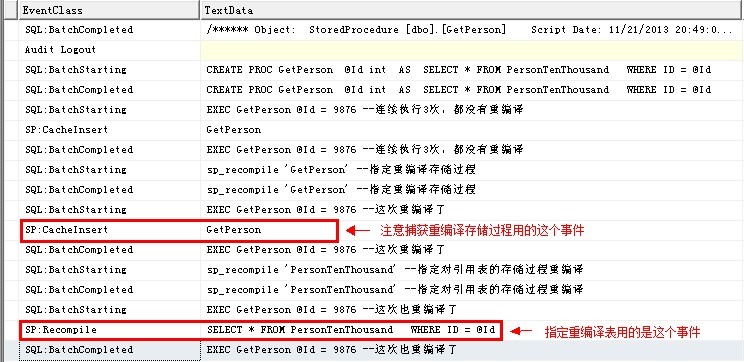
也可以使用sp_compile来使用sp_executesql执行时指定撤销重用现有计划。注意在 SQL Server Profiler集合中,指定重编译存储过程的记录事件 SP:CacheInsert 而不是事件 SP:Recompile。指定表才是SP:Recompile。
示例:
CREATE PROC GetPerson
@Id int
AS
SELECT * FROM PersonTenThousand
WHERE ID = @Id
GO
EXEC GetPerson @Id = 9876 --连续执行3次,都没有重编译
sp_recompile 'GetPerson' --指定重编译存储过程
EXEC GetPerson @Id = 9876 --这次重编译了
sp_recompile 'PersonTenThousand' --指定对引用表的存储过程重编译
EXEC GetPerson @Id = 9876 --这次也重编译了
捕获如下:
七、显示使用WITH RECOMPILE子句
SQL Server允许使用CREATE PROCRDURE或EXECUTE的RECOMPILE子句显式地重编译一个存储过程。这些方法降低了计划可重用性的效率,所以只应该在一些特殊的场合使用它们。
1、CREATE PROCEDURE语句的RECOMPILE子句
有时候,存储过程的计划需求可能随着调用存储过程的参数值变化而变化。在这种情况下,重用使用不同参数值的该计划可能降低存储过程的性能,可以使用CREATE PROCEDURE语句的RECOMPILE子句来强制每次执行存储过程都生成一个新计划(仅仅新生成执行计划,并非重编译整个存储过程)。
示例:
CREATE PROC GetPerson
@Id int
WITH RECOMPILE
AS
SELECT * FROM PersonTenThousand
WHERE ID = @Id
GO
EXEC GetPerson @Id = 9876 --每次都重新生成执行计划
SQL Server Profiler监控输出如下:
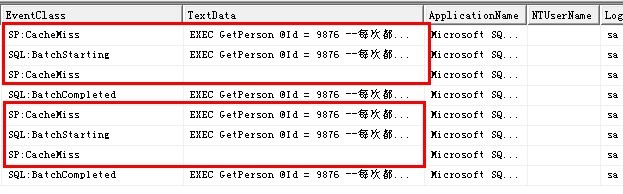
2、Execute语句的RECOMPILE子句
存储过程中的特定参数值可能需要不同的执行计划,可以在执行存储过程时动态采用WITH RECOMPILE,对特定一次执行重新生成新计划。
CREATE PROC GetPerson
@Id int
AS
SELECT * FROM PersonTenThousand
WHERE ID = @Id
GO
EXEC GetPerson @Id = 9876 --不重新生成计划
EXEC GetPerson @Id = 9876 WITH RECOMPILE --新生成计划
SQL Server Profiler输出:

当存储过程使用WITH RECOMPILE子句执行时,将临时生成一个新计划。这个新的计划不会被缓冲,并且不会影响现有计划。当存储过程不使用RECOMPILE子句执行时,该计划和往常一样被缓冲。仅仅影响一次执行,这与CREATE PROCDURE不同。因为可以考虑创建不同的存储过程来代替使用CREATE PROCDURE时RECOMPILE。
八、使用OPTIMIZE FOR查询提示
尽管不总是能减少或消除重编译,但是使用OPTIMIZE FOR查询提示可以帮助你使用指定的参数值来编译计划,而不管调用的应用程序传入的参数值。
如:
CREATE PROC dbo.getPerson
@Id INT
AS
SELECT * FROM Person
INNER JOIN Province
WHERE Person.Id = @Id
OPTION (OPTIMIZE FOR(@Id = 1)) --指定使用Id为1的参数来生成执行计划
执行:
EXEC dbo.getPerson @Id = 1234 WITH RECOMPILE --强制重编译
EXEC dbo.getPerson @Id = 5678 WITH RECOMPILE --强制重编译
现在,执行存储过程都重编译了,但是每次都是根据Id为1来生成执行计划。不会因为传入的参数不同而改变。