标题:Bootstrapping Humanoid Robot Skills by Extracting Semantic Representations of Human-like Activities from Virtual Reality
通过从虚拟现实中提取类人活动的语义表示来引导类人机器人技能
作者:Karinne Ramirez-Amaro1, Tetsunari Inamura2, Emmanuel Dean-Le´on1, Michael Beetz3 and Gordon Cheng1
0. 摘要
虚拟现实技术的进步已经实现了定义明确且一致的虚拟环境,可以捕获复杂的场景,例如人类的日常活动。此外,虚拟模拟器(例如SIGVerse)被设计为虚拟机器人/代理与真实用户之间的用户友好机制,从而实现了更好的交互。我们设想,可以使用这种丰富的场景来训练机器人特别是在人类日常活动中学习新行为的过程中,可以发现各种各样的可变性。在本文中,我们提出了一个多层次的框架,该框架能够使用不同的输入源(例如相机和虚拟环境)来理解和执行所演示的活动。我们提出的框架首先从相机获取人类活动的语义模型,然后使用SIGVerse虚拟模拟器对其进行测试,以使用虚拟机器人显示新的复杂活动(例如清理桌子)。我们介绍的框架集成在真实的机器人(即iCub)上,该机器人能够处理来自虚拟环境的信号,然后了解观察到的机器人执行的活动。这是通过使用机器人从观察人类活动中学到的先前知识和经验来实现的。我们的结果表明,我们的框架能够通过语义表示获取当前上下文中的对象关系,从而提取出这些动作的高级理解,即使它们代表不同的行为,也能以80%的识别率提取观察到的动作的含义。
1. 介绍
使机器人学习新任务通常需要人类多次演示期望的任务[1]。 观察到的动作应捕捉人的姿势,以进一步创建识别所演示任务的模型。 但是,这意味着由于准备捕获新场景而导致的高昂成本,并且这些观察仅限于少数任务。 尽管如此,当可以比传统方法更大规模,更快速地测试新场景和不同条件时,可以使用虚拟环境来(部分)解决数据获取的问题(见图1)。

虚拟环境(VE)是人机界面,计算机在其中创建一个浸入感官的环境,该环境以交互方式响应用户的行为并受其行为控制。 例如,SIGVerse是一个模拟器环境,它结合了动力学,知觉和交流以综合方法研究社会智能的起源[2]。 使用这样的模拟器具有多个优点,例如快速,廉价地设置新环境,所分析场景的不同视角,多用户交互,虚拟化身与真实用户之间的具体交互等。换句话说,诸如VE 是重要的工具,特别是在研究几种人类行为时,例如烹饪,清洁等,因为它们提供了有关已执行任务和环境要素的更完整和同步的信息,这些信息将极大地帮助您了解人类行为,而无需进行进一步的操作 昂贵的额外传感器。
众所周知,从观察中分割和识别人类行为是一个困难而具有挑战性的问题[3]。 因此,已提出了多种选择来收集观察到的数据,例如使用[4]中所示的一个静态相机或例如[5]的多个外部相机,并且最近的研究一直在探索以自我为中心的相机来分析人的视线信息, 例如 [6],[7]增强了对机器人系统日常生活活动的认识。 但是,这些记录仅限于对获得的数据进行分析,而新任务的获取将需要全新的设置,招募参与者以演示新任务,场景周围的精确传感器等,从长远来看,这些代表 一个非常昂贵且有限的解决方案。 因此,一个更好的选择是使用虚拟模拟器,由于[8]中提出的大规模功能,该模拟器可以实现长期的人机交互。
在本文中,我们提出了一个框架,该框架能够基于先前学习的经验来细分和识别人类行为。人类活动识别不依赖于所学的任务,并且可以使用不同的输入传感器(例如摄像机和虚拟场景)在几种新场景中重复使用。图1描绘了我们提出的系统,该系统首先训练模型以正确识别人类行为,同时从真实摄像机准备三明治。在这种情况下,使用观察到的烹饪任务即可获得语义表示和推理引擎。最具挑战性的部分是将获得的模型转移到新场景中,而不是观察真实的人类,而是观察到虚拟的移动机器人,这表明清理桌子是一项全新的任务。最后,我们的系统已完全实现为机器人平台,该平台可收集VE的信息并提取所演示活动的语义,以了解虚拟机器人的行为,从而在其真实场景中执行类似任务。
总而言之,本文的主要贡献是:a)我们提出了一个多层次的框架,该框架使用我们提出的语义表示将来自不同输入源(例如2D摄像机和VE)的信息进行组合; b)由于学习到的语义的可重用性,所提出的框架是灵活的并且适应于新的情况; c)我们使用比训练阶段使用的任务更复杂的任务来评估我们的框架,从而证明我们获得的模型不依赖于训练后的任务; d)我们提出的框架完全在仿人机器人上实现,该仿人机器人模仿了来自不同输入源的观察到的行为。本文的其余部分安排如下,第二部分介绍了相关工作。然后,第三部分介绍了SIGVerse系统的技术细节。随后,第四节介绍了对虚拟数据执行的步骤。然后,第五节介绍了语义表示方法。最后,第六节简要介绍了所获得的结果以及结论。
3. SIGVERSE仿真器
SocioIntelliGenesis模拟器(SIGVerse2)主要是为RoboCup @ Home模拟挑战开发的[2]。 SIGVerse可以进行更好,更直接的HRI实验,因为所有真实或虚拟代理都可以进行社交和物理交互。 此外,用户可以通过Internet任意加入虚拟HRI实验,以增强交互性。
SIGVerse具有三个主要模块:a)动态用于模拟对象和代理的物理属性; b)提供视觉,声音,力量和触觉以增强HRI的感知; c)可用服务之间的通信。
SIGVerse是由Linux服务器和Windows客户端应用程序组成的客户端/服务器系统。 服务器负责运行动力学计算并控制机器人和人类化身的行为。 Windows客户端用于实时访问用户界面。 在这项工作中,服务器系统被实现为访问环境信息,特别是获取场景中对象的位置以及可以在执行任务期间记录的机器人编码器信息,如图2所示。
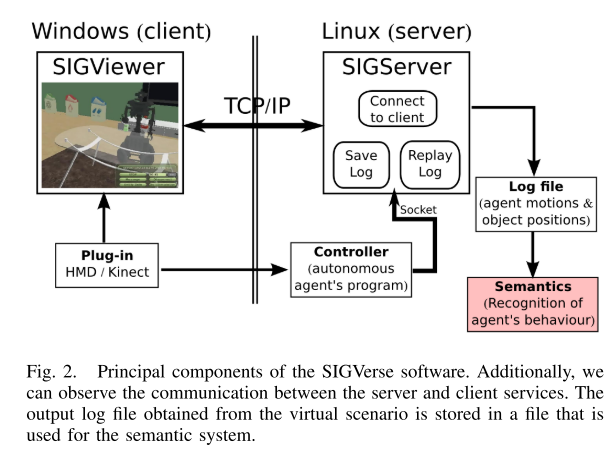
对于我们的实验,我们选择清理任务,这是RoboCup @ Home竞赛规则手册中的一项挑战性任务[8]。 在执行此任务期间,机器人必须抓住用户瞄准的一块垃圾并将其放入容器中。 在此任务中测试了几个问题,其中一个是通过语音识别或通过使用相机拍摄的图片的图像处理来理解指令的含义。 在本文中,我们将重点讨论第二个问题。
SIGVerse仿真器是一种先进的系统,由于其强大的功能性,最近在仿真联盟的RoboCup @ Home竞赛中受到关注。 在挑战期间,用户可以通过操纵杆设备或Kinect设备控制机器人。 换句话说,确定本文中使用的机器人行为的控制器是由随机用户直接编写的。 在这项工作中,SIGVerse使用的数据包含机器人的运动,该机器人由用户编写的自主控制器模块控制。
4. 从SIGVERSE中提取信息
在我们以前的工作中[4],我们提出了一种基于语义表示来识别人类活动的新方法。 这种抽象方法不是直接尝试对人类活动进行分类,而是基于观察到的人类运动以及感兴趣对象的信息来推断活动。 为了实现这一目标,我们将演示任务的视觉信息与人体运动的信息相结合。 首先,我们将人类的连续运动划分为有意义的类。 然后,第二部分处理使用我们的推理模块将感知到的信息解释为有意义的类的难题。 三种原始的人体运动主要分为三类:
A. 使用虚拟数据进行分割的结果
使用VE的主要优势之一是这样的事实:环境中的主体和对象的位置是已知的,无需任何其他感知系统即可获取,这可以节省分析数据时的时间。 但是,我们先前在[4]中提出的系统仅考虑了2D图像的信息。 这意味着我们需要调整我们的系统,使其也包括3D数据。 这些变化仅反映在执行任务清理过程中机器人手运动的分段上,即,在移动虚拟机器人的右末端执行器速度的计算上。
由于所获得的虚拟移动机器人末端执行器的速度会产生一些噪声,因此我们实施了第二种方法。 阶低通滤波器可以平滑获得的速度。 我们选择具有标准化截止频率Wn的数字Butterworth滤波器。
5. 了解人类活动
在这项工作中,我们提出了两个抽象层次:低层次,它描述了一般的动作,例如:移动,不移动或使用工具;以及高层次的抽象,它代表了人类的基本活动,例如:到达,采取 ,剪切,释放等。我们的技术使用来自低层抽象的信息来推断高层活动。 本节简要介绍了我们在[4]中介绍的方法,该方法使用语义表示将从外部摄像机获得的观察结果进行组合。 换句话说,该模块解释了从感知模块获得的视觉数据,并处理该信息以推断出人类的意图。 这意味着它接收到手部运动分割(m)和对象属性(oa或oh)作为输入信息。
为了识别和提取人体运动的含义,我们使用决策树自动生成语义规则,该语义规则以一般方式定义和解释了所演示的人体运动。 我们使用C4.5算法[23]和Weka软件来构建决策树。 我们将来自2D摄像机的信息用作三明治制作场景的训练数据(请参见图1中的训练框)。 请注意,由于此场景包含几个子活动以及不同的约束,因此它具有很高的复杂性。
我们提出的方法包括识别人类活动的两个步骤。 第一步,我们将第一个主题的真实数据的信息用于制作三明治的场景。 我们按以下方式拆分数据:前60%的路径用于训练,其余40%的路径用于测试。 然后,我们获得了图3所示的Tsandwich树,该树具有与先前在[4]中提出的结构相同的结构。 从这棵树中,可以推断出以下人类基本活动:闲置,获取,释放,到达,在某处放置东西和进行细化处理4。 该学习过程将捕获对象,动作和活动之间的一般信息。 重要的是要强调,如[6]所示,当使用煎饼数据集进行训练时,会获得相似的树。
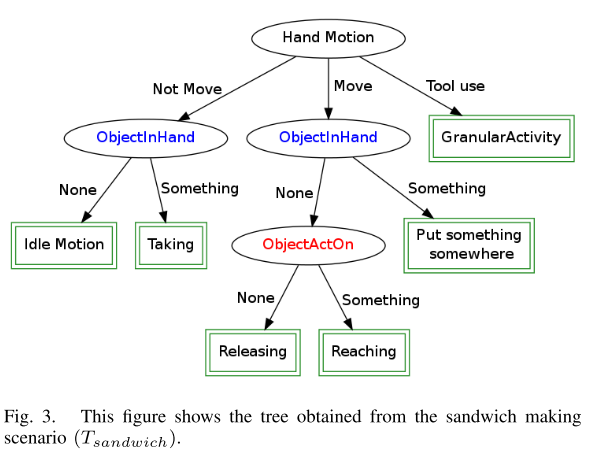
从图3中,我们可以观察到使用相同的规则推断出切割,洒水等活动:
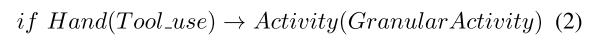
这意味着这些活动需要更多信息才能正确分类。 这些活动并不代表人类的基本活动,我们将其称为粒度活动,我们使用提出的方法的第二步,根据当前上下文扩展获得的树,以类似于[4]中所述的方式推断此类活动。
A. 人类活动识别的结果
重要的是要注意,用于训练语义表示的演示来自2D摄像机和烹饪活动。 这意味着在执行活动期间,人总是站在同一位置。 然后,是否有可能在演示者不断在厨房中移动的未知情况下重用图3所示的学习模型?
为了回答上述问题,我们使用虚拟环境的信息使用新的清理任务测试了从图3中获得的树,这意味着现在我们已经将3D信息作为输入。 此外,从附加视频中可以看到,演示行为的主体是一个虚拟机器人,它正在厨房中四处移动,这使得识别更加困难,尤其是在以前没有针对这种新情况进行培训的情况下。
从获得的结果中,我们可以发现,与真实情况相比,我们的系统错误地识别了闲置和释放活动。 但是,如果我们更详细地观察所获得的树(请参见图3),那么我们会注意到,为了识别空闲或释放活动,我们使用以下规则:

这表明在两种活动中,唯一的区别是手的运动,该运动是运动还是不运动。 这是一个非常有趣的现象,因为它表明这两个规则描述了相同的活动。 以前我们从未在不同的烹饪场景下测试过系统,因为人类大多站在桌子前的同一位置,因此这方面从未出现过。 但是,在这种新情况下,我们注意到演示器(在本例中为虚拟机器人)在厨房周围移动,这加剧了这种情况。
然后,我们考虑了这两个规则描述相同活动的情况,并使用此新假设再次测试了三明治制作方案,识别率从92.57%提高到95.43%。 此外,我们要求随机参与者为三明治方案标记真实数据,我们注意到他们经常将闲置和释放的活动分类错误。 因此,证明这两个规则是等效的。 按照类似的程序,我们将系统识别到新场景中的准确度进行计算,并且定量结果与地面真实情况相比准确度为80%,这是非常高的准确度,特别是因为在这种新情况下未进行任何训练,并且 培训和测试方案非常不同。
6. 将模型转移到人形机器人中
将获得的认知行为集成到人形机器人中的实验性整合和验证是非常重要,必不可少且具有挑战性的任务。 因此,作为最后一步,我们在人形机器人iCub上验证了我们的框架,iCub是一个53自由度的人形机器人[24]。 我们在机器人的控制环内提出的框架的实现遵循与我们先前的工作[4]中解释的过程相似的过程。 但是,我们需要包括新的过程,以使我们的代码适应可能检测到多个对象的新场景。 这意味着几个对象可以同时具有相同的属性。 然后,为避免这种情况,我们在识别ObjectActedOn和ObjectInHand属性的过程中特别改进了我们的系统。 该过程在算法1中有更好的解释。

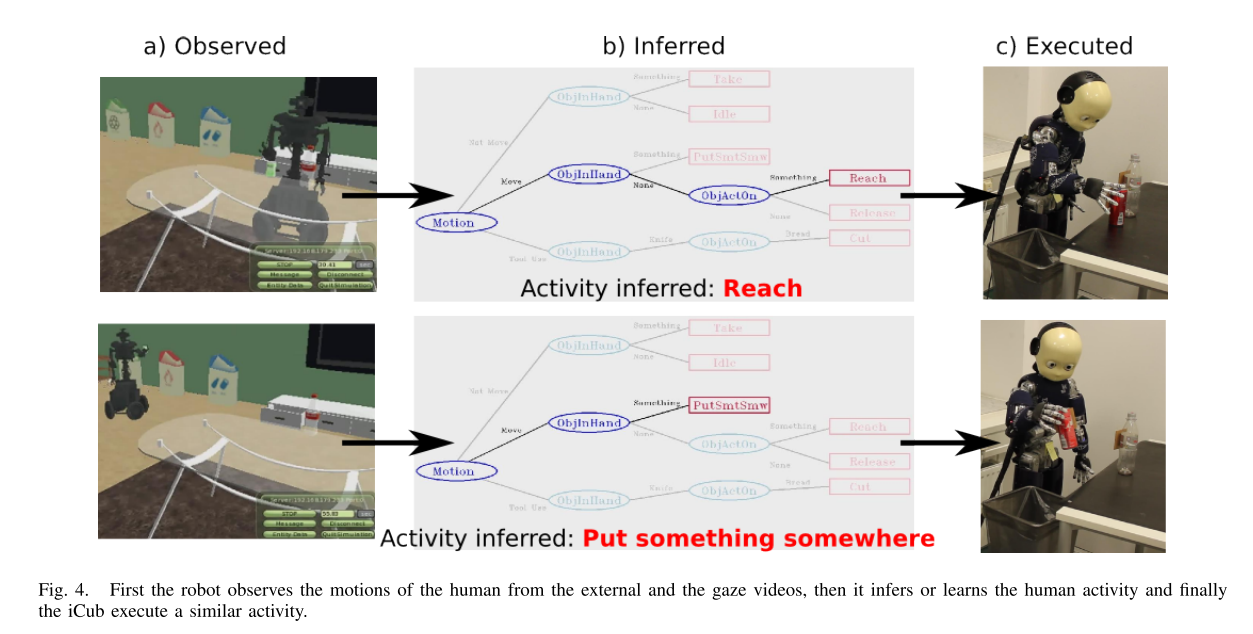
识别人类活动的结果如图4所示。我们的结果还表明,为了执行诸如清理桌子之类的复杂任务,可能仅识别简单和基本的人类活动,例如: ,拿,放,放/空。 另一个有趣的结果是无需使用粒度活动就可以理解和执行诸如清洁之类的复杂活动的可能性,这也证明了我们获得的语义表示的鲁棒性,这些语义表示在不同的场景和使用不同的输入来源,例如相机或VE下仍然有效(无需任何进一步的培训) 。
另外,图4描绘了我们的iCub机器人的在线感知和语义功能之间的集成,以成功地实时识别来自不同场景下不同信息源的人类活动。 换句话说,我们针对不同级别的复杂性集成和评估我们的系统,即,首先,我们使用视频输入测试了我们获得的模型,然后,在没有进一步培训的情况下,我们在新的虚拟环境中测试了相同的模型。 在获得的结果表明我们的框架能够从SIGVerse虚拟模拟器中提取观察到的运动的含义的情况下,其识别精度为80%。
这表明我们提出的系统的设计方式允许在不进行进一步修改的情况下提供不同的输入,而无需进行进一步的培训就可以尽可能正确地正确提取复杂的人类活动的语义。
7. 总结
在本文中,我们介绍了使用虚拟现实手段通过提取语义表示以识别人类活动来引导类人机器人技能的框架。 我们的语义表示是通过将低级人体运动(即移动或不移动)和两个对象属性(即ObjActedOn,ObjInHand)进行细分而获得的。 我们证明了我们的语义规则在一个全新的场景中捕获了人类日常活动的含义,即无需进一步培训即可清理桌子,其识别精度约为80%。