一. pandas----csv
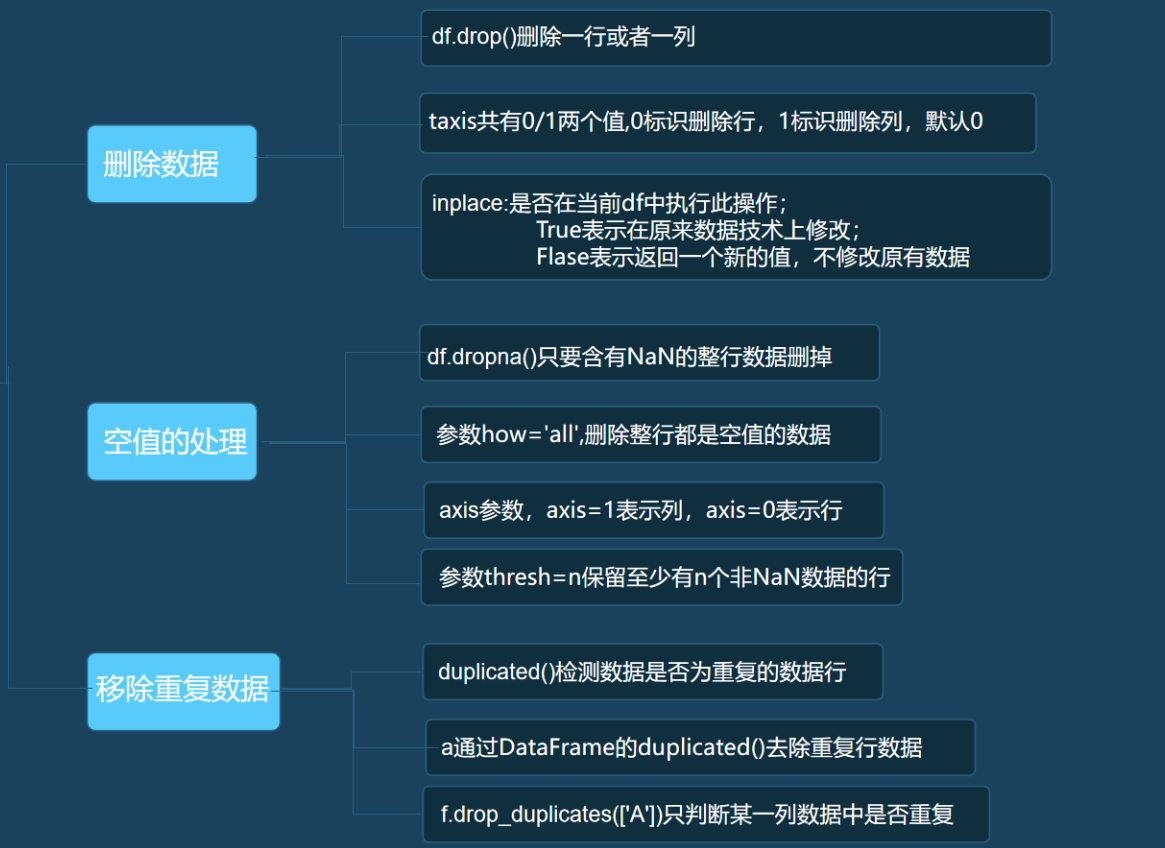
1. pandas将数据写入csv文件中
df.to_csv(path_or_buf='./xxx.csv', encoding='utf_8_sig')
2.如果不想把索引写道csv中, 增加index= False
df.to_csv(path_or_buf='./hero.csv', encoding='utf_8_sig', index=False)
3.从csv中读取数据
import pandas as pd
data = pd.read_csv('./hero.csv')
4.利用read_excel()中的header参数进行选择哪一行作为列索引, 默认为0, header设置为None,列索引值会使用默认的1、2、3、4
pd.read_csv('/data/course_data/data_analysis/People1.csv',header = 1)
二. pandas-----excel
1. pandas将数据写入excel文件中
df.to_excel(excel_writer='./hero.xlsx', encoding='utf-8')
2.从excel中读取数据
import pandas as pd
sheet1 = pd.read_excel('/data/course_data/data_analysis/sheet.xlsx',sheet_name='sheet1')
三. 总结
四. 删除行或者列数据
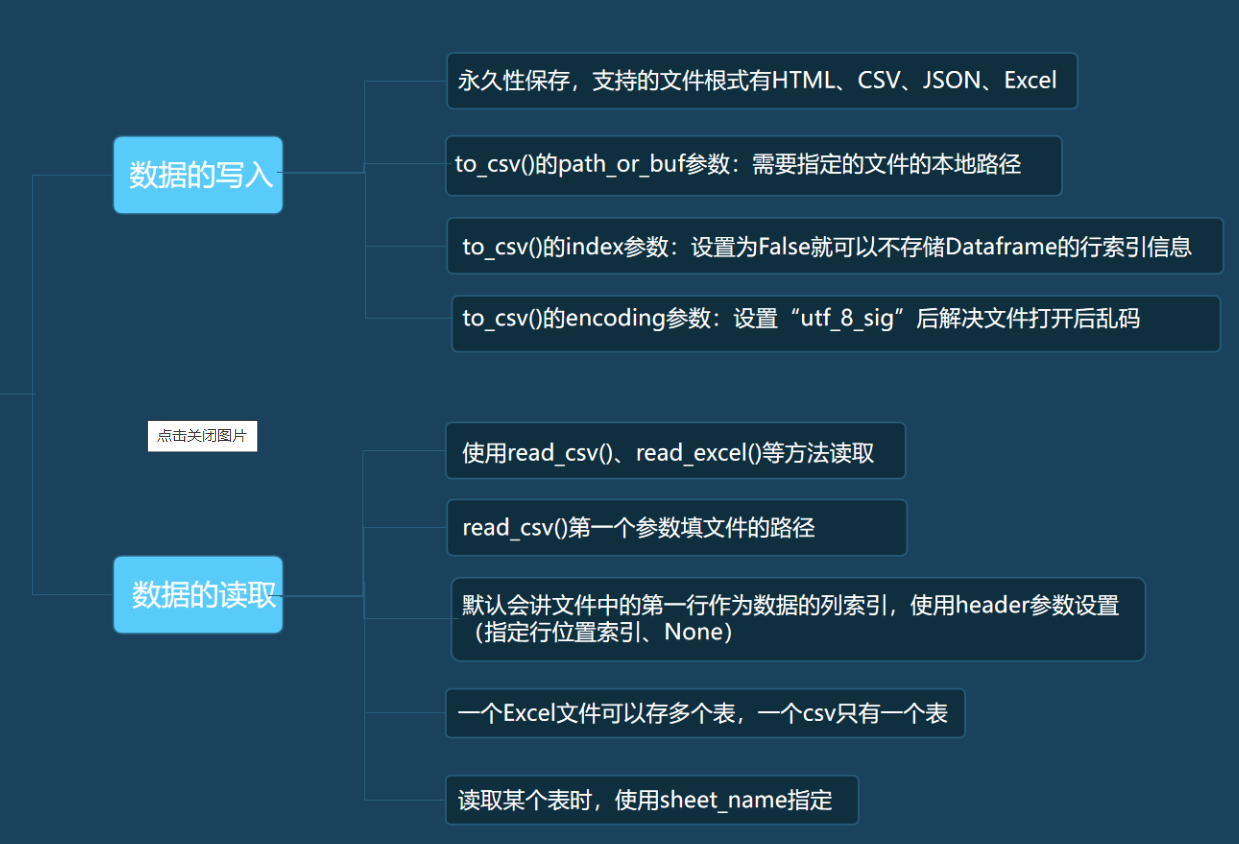
1.DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
代码解释
-
- axis :0表示行,1表示列
- labels :就是要删除的行列的名字,用列表给定。
- index: 直接指定要删除的行。
- columns: 直接指定要删除的列。
- inplace=False:默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe。
- inplace=True:则会直接在原数据上进行删除操作,删除后无法返回。
2.例如:
import pandas as pd
df = pd.read_excel('/data/aa.xlsx')
# 删除第0行和第1行
df.drop(labels=[0,1],axis=0)
# 删除列名为1990的列
df.drop(axis=1,columns=1990)
五.删除空值Nan
df1 = df.dropna()
- import pandas as pd
- df = pd.read_excel('/data/course_data/data_analysis/rate.xlsx')
- # 用常数填充fillna
- # print(df.fillna(0))
- # 用一列的平均值填充
- # print(df.fillna(df.mean())
- # 用前面的值来填充ffill
- # print(df.fillna(method='ffill',axis=0))