上一篇你真的会用String吗(3)-关于字符串拼接中我们提到了String.intern()方法,本篇我们就来详细的看下这个方法是干嘛的。首先来看下jdk8中这个方法的注释:
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
It follows that for any two strings s and t, s.intern() == t.intern() is true if and only if s.equals(t) is true.
All literal strings and string-valued constant expressions are interned. String literals are defined in section 3.10.5 of theThe Java™ Language Specification.
当调用intern()这个方法的时候,如果String常量池中没有这个String对象就把它放到常量池中,然后再返回它的引用,如果池中已经有这个String对象了,就直接把它返回。当且仅当两个String是equals的时候,他们的intern才会返回同一个引用。所有的String字面常量和String constant variable都是interned,也就是说都是在String常量池中的。
关于intern有个非常有意思的现象,对于同一段代码,在jdk6和jdk7以后输出结果却完全不一样,这个打破了java高版本兼容低版本的传统,看代码:
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这段代码在jdk6下运行结果如下: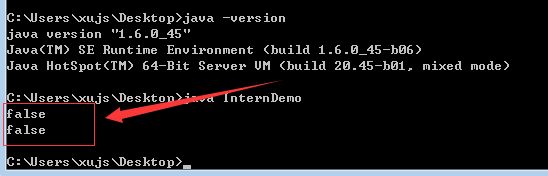
在jdk8下: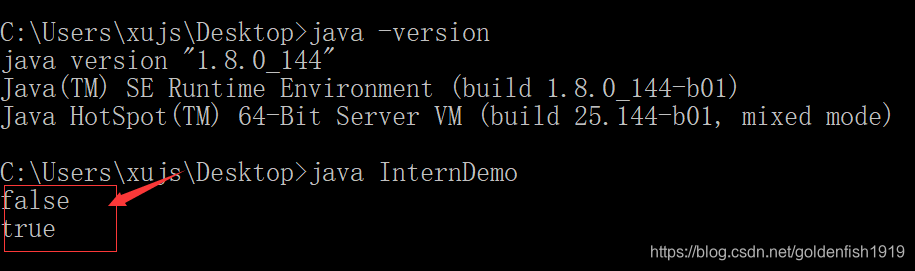
这个是由于jdk内存结构变化导致的,具体地说:
jdk6中,字符串常量池是存在于Perm区的,但是从jdk7开始,字符串常量池从Perm区移到了堆区,jdk8中则完全移除了Perm区 。对于String.intern来说,无论是jdk6还是jdk7,都是先去查看字符串常量池是否有该字符串,如果有,则返回字符串常量池中的引用。不同点在于如果是 jdk7,当字符串常量池中找不到对应的字符串时,不会将字符串拷贝到字符串常量池,而只是生成一个对该字符串的引用在字符串常量池,而 jdk6会拷贝字符串至字符串常量池。因此,从jdk7开始,常量池中的字符串分为两类,一类是本身就存在于池中的字符串,一类是本身存在于堆中但是引用存在于池中的字符串,而在jdk6和以前常量池和堆是完全分开的两个东西。
对于jdk6:
public static void main(String[] args) {
//s指向堆中的一个字符串,"1"是字面常量,是存在于Perm区的常量池中
String s = new String("1");
//s2指向的是常量池中的"1"
String s2 = "1";
//因为常量池中已经有"1",因此这个什么也不做
s.intern();
//s指向堆区,s2指向Perm区的常量池,所以是false
System.out.println(s == s2);
//"1"已经存在于常量池
//s3指向堆中的一个串,内容是“11”,但是,此时常量池中并没有“11”
String s3 = new String("1") + new String("1");
//此时把s3代表额字符串“11”加入到了Perm区的常量池中
s3.intern();
//s4指向Perm区常量池中的“11”
String s4 = "11";
//s3指向堆区的一个字符串,s4指向Perm区常量池中字符串,所以false
System.out.println(s3 == s4);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
对于jdk7来说:
public static void main(String[] args) {
//s指向堆区的一个串,“1”位于堆区的常量池中
String s = new String("1");
//s2引用常量池中的“1”
String s2 = "1";
//常量池重已经有“1”,什么也不做
s.intern();
//s指向堆,s2引用常量池,false
System.out.println(s == s2);
//s3指向堆中的一个字符串
String s3 = new String("1") + new String("1");
//把s3这个字符串的引用加入到了常量池,此时常量池中有了“11”这个串的引用
s3.intern();
//s4引用的常量池中的“11”,也就是s3
String s4 = "11";
//s3和s4都是引用常量池中字符串,true
System.out.println(s3 == s4);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
如果把代码稍微改一下,jdk7中:
public static void main(String[] args) {
//s3指向堆中的字符串
String s3 = new String("1") + new String("1");
//s4引用常量池中的字符串
String s4 = "11";
//池中已经有“11”,什么也不做
s3.intern();
//显然是false
System.out.println(s3 == s4);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
因为String.intern会引用常量池中已经存在的字符串,可以减少内存中相同字符串的数量,节省一些内存空间,为了提高效率,是不是我们应该把所有的字符串都调用intern()加入到池中呢?显然是不是的。
String常量池底层的数据结构类似于HashMap,jdk6中池的大小是固定的1009,如果池中的字符串太多就会造成hash冲突严重,会严重影响字符串查找的效率。从jdk7开始,池的大小可以手动设置StringTableSize这个参数来指定。jdk8中,池的大小默认是60013.
C:Usersxujs>java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
C:Usersxujs>java -XX:+PrintFlagsInitial | findstr StringTableSize
uintx StringTableSize = 60013
- 1
- 2
- 3
- 4
- 5
- 6
当然,如果能确定系统中对某些串的读取非常频繁,而且这些串的数量也不会很多,那也是可以把他们加入到池中的。参考:
https://tech.meituan.com/in_depth_understanding_string_intern.html
此外,jdk8的G1收集器还添加了一个很有用的选项 -XX:+UseStringDeduplication可以对String进行去重,也可以节省一部分内存空间,参考:
http://openjdk.java.net/jeps/192