总结《SparkStreaming实时流式大数据处理实战》
一、初始spark
1. 初始sparkstreaming
1.1 大数据处理模式
1. 一种是原生流处理(Native)的方式,即所有输入记录会一条接一条地被处理,storm 和 flink
2. 另一种是微批处理(Batch)的方式,将输入的数据以某一时间间隔,切分成多个微批量数据,然后对每个批量进行处理,sparkStreaming
1.2 消息传输保障
at most once 至多一次,可能会丢
at least once 至少一次,可能重复
exactly once 精确传递一次
1.3 容错机制
流式处理发生中断出错的现象是常有的情况,可能是发生在网络部分、某个节点宕机或程序异常等。,当发生错误导致任务中断后,应该能够恢复到之前成功的状态重新消费。
Storm是利用记录确认机制(Record ACKs)来提供容错功能。
Spark Streaming则采用了基于RDD Checkpoint的方式进行容错。
1.4 性能
延时时间:storm > spark
吞吐量 :spark > storm
1.5. Structed Streaming(结构化)简述
不同点:
Spark Streaming是以RDD构成的DStream为处理结构.
Structed Streaming是一种基于Spark SQL引擎的可扩展且容错的流处理引擎
Structed 提供了更加低延迟的处理模式
相同点:
都是微批的实时处理,内部并不是逐条处理数据记录,而是按照一个个小batch来处理,从而实现低延迟的端到端延迟和一次性容错保证。
二、共享变量
节点之间会给每个节点传递一个map、reduce等操作函数的独立副本,这些变量也会被复制到每台机器上,而节点之间的运算是相互独立的。
这些变量会被复制到每一台机器上,并且当变量发生改变时,并不会同步传播回Driver程序。
如果进行通用支持,任务间的读写共享变量需要大量的同步操作,这会导致低效。
Spark提供了两种受限类型的共享变量用于两种常见的使用模式:广播变量和累加器。
2.1 累加器(Accumulator)
累加器是一种只能通过关联操作进行“加”操作的变量,因此它能够高效地应用于并行操作中。累加器能够用来实现对数据的统计和求和操作。Spark原生支持数值类型的累加器,开发者可以自己添加支持的类型。
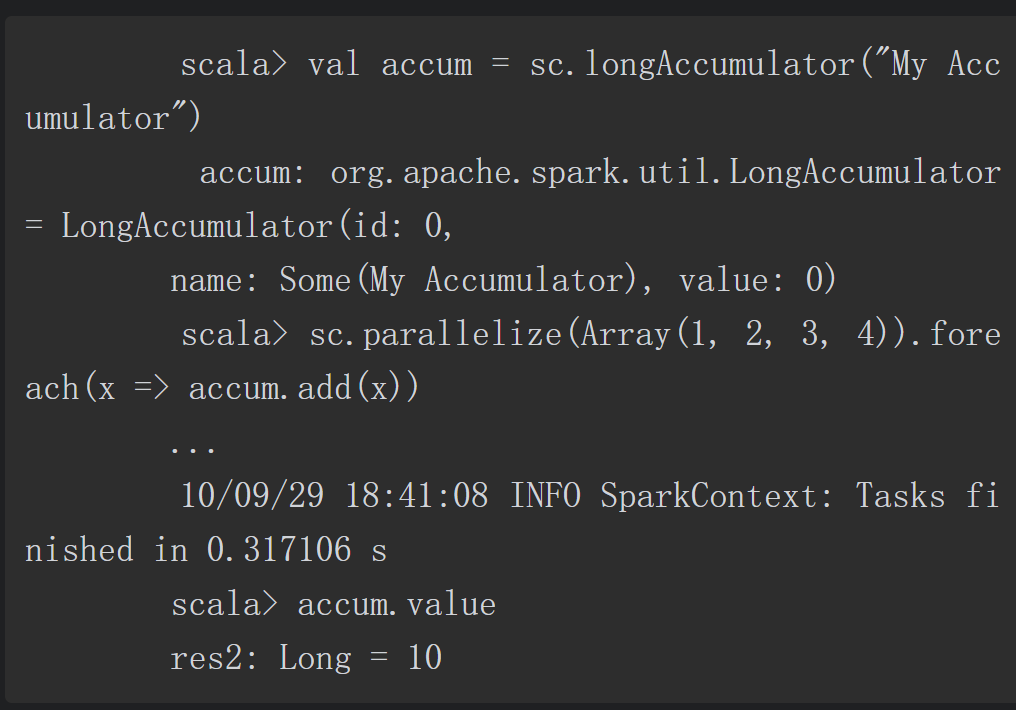
节点上的任务可以利用add方法进行累加操作,但是它们并不能读取累加器的值。只有Driver程序能够通过value方法读取累加器的值。
2.2 广播变量(Broadcast)
广播变量允许程序员在每台机器上缓存一个只读的变量,而不是每个任务保存一份拷贝。
利用广播变量,我们有效的将一个大数据量输入集合的副本分配给每个节点。Spark也有效的利用广播算法去分配广播变量,以减少通信的成本。

可以利用广播变量将一些经常访问的大变量进行广播,而不是每个任务保存一份,这样可以减少资源上的浪费。
三、DStream
Spark Streaming对微批处理方式做了一个更高层的抽象,将原始的连续的数据流抽象后得到的多个批处理数据(batches)抽象为离散数据流(discretized stream),DStream本质是RDD数据结构的序列
3.1 DStream的创建方式
一是从Kafka、Flume等输入数据流上直接创建。
二是对其他DStream采用高阶API操作之后得到(如map、flatMap等)。
3.2 DStream的Transform操作
与RDD的Transformation类似,DStream的转移操作也不会触发真正的计算,只会记录整个计算流程。
- map
- flatMap
- fliter
- repartition
- union
- reduce
- join
3.2.1 UpdateStateByKey操作
流式处理本身是无状态的,如何记录更新一种状态呢?
我们可以利用外部存储介质或者利用累加器来实现,而UpdateStateByKey就是专门用于这项工作,可以利用这个操作根据新的信息流持续地更新任意状态。
(1)定义状态(state):该状态可以是任意数据类型。
(2)定义状态更新函数(update function):我们需要制定一个函数,根据先前的状态和数据流中新的数据值来更新状态值。
特别注意:使用updateStateByKey需要配置checkpoint,这个将在后面详细介绍。
3.2.2 Transform操作
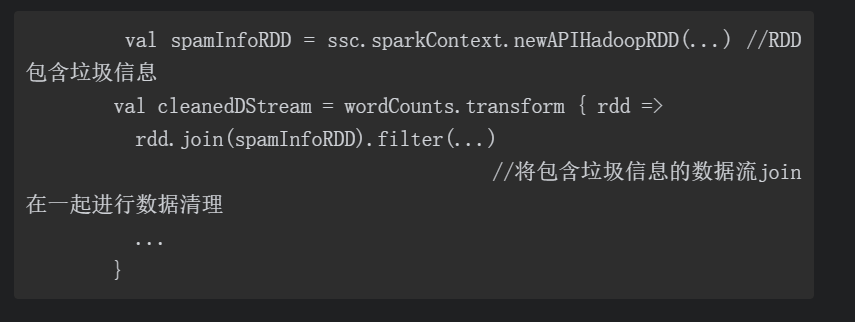
传入的函数会在每个时间间隔(interval)的batch中被执行,这允许我们做不同时间段的RDD操作,也就是说RDD操作、分支(partitions)数量及广播变量等都可在batch间进行改变。
3.2.3 windows操作
Spark Streaming还提供了基于窗口的计算,允许我们在滑动窗口数据上进行Transformation操作。
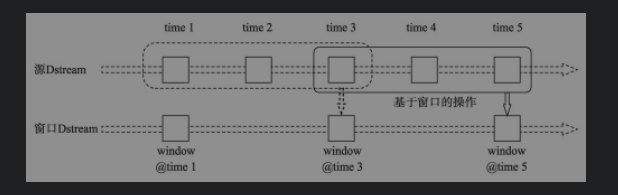
在原始DStream上,窗口每滑动一次,在窗口范围内的RDDs就会结合、操作,形成一个新的基于窗口的DStream(windowed DStream)。
- 窗口长度(window length):窗口的持续时长(图中为3)。
- 滑动间隔(sliding interval):执行窗口操作的时间间隔(图中为2)。

3.2.4. join操作
(1)Stream-Stream join操作
(2)Stream-dataset join操作
这里的dataset是RDD数据类型,在前面介绍Transform时我们提到DStream的Transform操作使我们能够直接操作DStream内部的RDD,所以可以利用上述操作将二者拼接起来。
3.3 DStream 的输出操作
将DStream中的数据保存到外部系统中,如数据库或者文件系统。与RDD中的Action操作类似,DStream中只有输出操作才会触发DStream的转移操作(Transformation)。
- print()
- saveAsObjectFiles(prefix,[suffix])
- saveAsTextFiles(prefix.[suffix])
- foreachRDD(func) 会将传入的func函数应用在DSteam中的每个RDD上,值得注意的是func函数通常会运行在Driver中,并且由于Spark是惰性的,func需要包含Action操作,以此推动整个RDDs的运算。
在实际生产环境中,foreach()这个操作是常用到的,我们可以利用该函数将DStream中的数据按照需要的方式,输出到指定外部系统中,如MySQL、Redis、HBase、文件等
3.4 SparkStreaming初始化及输入源
3.4.1初始化流式上下文(StreamingContext)
初始化sparkStreaming需要sparkContext
在创建了上下文对象之后,还需要进一步创建输入DStream来指定输入数据源,下面具体介绍。
3.4.2 输入源及接收器(Receivers)
创建输入源:
- 基本数据源,这类数据源可以直接由StreamingContext API使用,如文件系统或者套接字连接(socket connections)。
- 高级数据源:像Kafka、Flume、Kinesis等数据源,需要使用额外的接口类。
3.4.2.1 基本数据流
- Socket文本数据流:通过TCP套接字连接接收文本数据产生DStream。
- File数据流:从文件或者任何兼容的文件系统(HDFS、S3、NFS等)中读取数据产生DStream。
- RDDs队列(queue)作为数据流:在测试Spark Streaming应用时,可以将一系列RDD,使用streamingContext.queueStream(queueofRDDs)来产生DStream,每个进入队列的RDD,会被认为是DStream中的一批(batch)数据,会以流式的方式进行处理。
3.4.3持久化、Checkpointing和共享变量
3.4.3.1 DStream持久化(caching/presistence)
对于基于窗口的操作如reduceByWindow和reduceByKeyAndWindow,以及基于状态的操作如updateStateByKey,它们本身就暗含了对同一数据进行多重操作的特性。因此,由基于窗口操作产生的DStream,即使开发者不主动调用persist()方法,DStreams也会自动持久化在内存当中。默认是内存。
3.4.3.2 Checkpointing操作
一般来说,一个流式处理程序需要24小时不间断运作,所以其必须拥有一定的与程序逻辑本身相独立的容错机制(如系统错误、虚拟机宕机等)。Spark Streaming的容错恢复系统必须拥有检查点(checkpoint)的充足信息,从而能够从失败中恢复过来。其中主要有两种类型的数据被检查点记录下来。
第一种,元数据检查点(metadata checkpointing):保存流式计算中用于容错存储的信息,如HDFS。这些信息会被用来恢复driver节点的流式应用。
- 配置(Configuration):用于创建流式应用的配置信息。
- DStream操作:流式应用中定义的DStream操作集。
- 未完成的批处理(batches):工作(Job)已经入队但是还未完成的批处理。
第二种,数据检查点(data checkpointing):将已经生成的RDDs进行可靠的存储。这在一些依赖于多个batch数据的状态转移操作(stateful transformation)中是必须的。
transform 状态转移操作的中间RDD会通过定期检查点(checpoint)输出到可靠的存储介质当中(如HDFS),从而切断这种依赖链的影响。
下面的条件,则必须使用检查点(checpointing):
- 使用有状态转移操作(stateful transformation):如果在应用中使用了updateStateByKey或者类似reduceByKeyAndWindow的操作,则必须设置检查点目录(checkpoint directory),从而能够定期保存RDD。
- 将运行程序的Driver节点从失败中恢复:元数据检查点被用来恢复这个过程。
检查点的保存目录可以设置为(如HDFS、S3等),这样检查点的信息就会保存在我们所设置的目录下,我们可以使用streamingContext.checkpoint(checkpoint Directory)进行设置。
当程序第一次运行时,其必须创建新的StreamingContext,并且设定好所有的流(streams),之后调用start()函数。
当一个程序需要从失败中重启时,其会根据检查点目录中保存的检查点数据来重建StreamingContext。

RDD检查点保存到可靠存储空间中时,会有一定的消耗。这可能会使得那些被保存RDD检查点的batches的处理时间加长,因此检查点的间隔(interval)需要谨慎设置。在最小的batch尺度上(1s),每个batch的检查点设置可能会严重降低操作的生产量。而相反,如果检查点过于频繁,会导致任务尺寸的增长,造成不利的影响。
通常在DStream间隔(intervals)的基础上增加5~10s是一个比较好的检查点时间间隔。
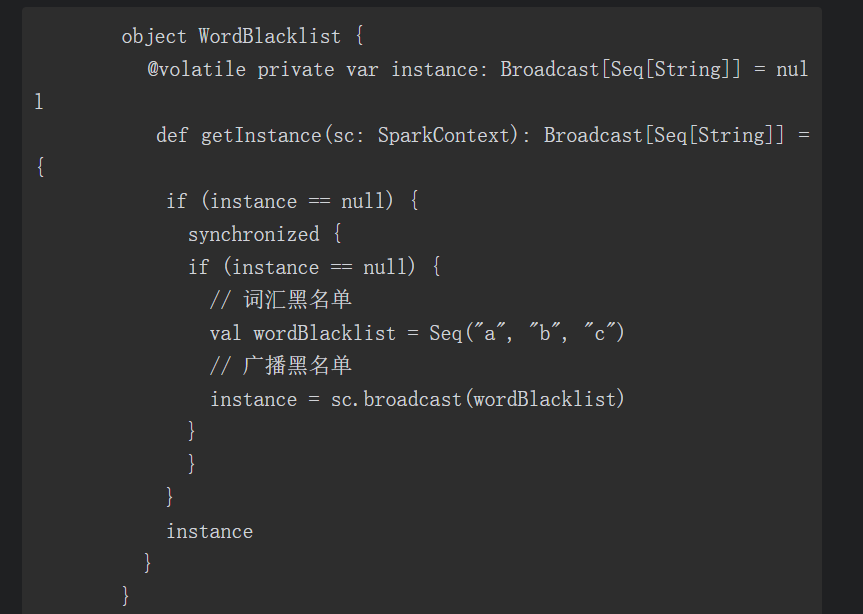
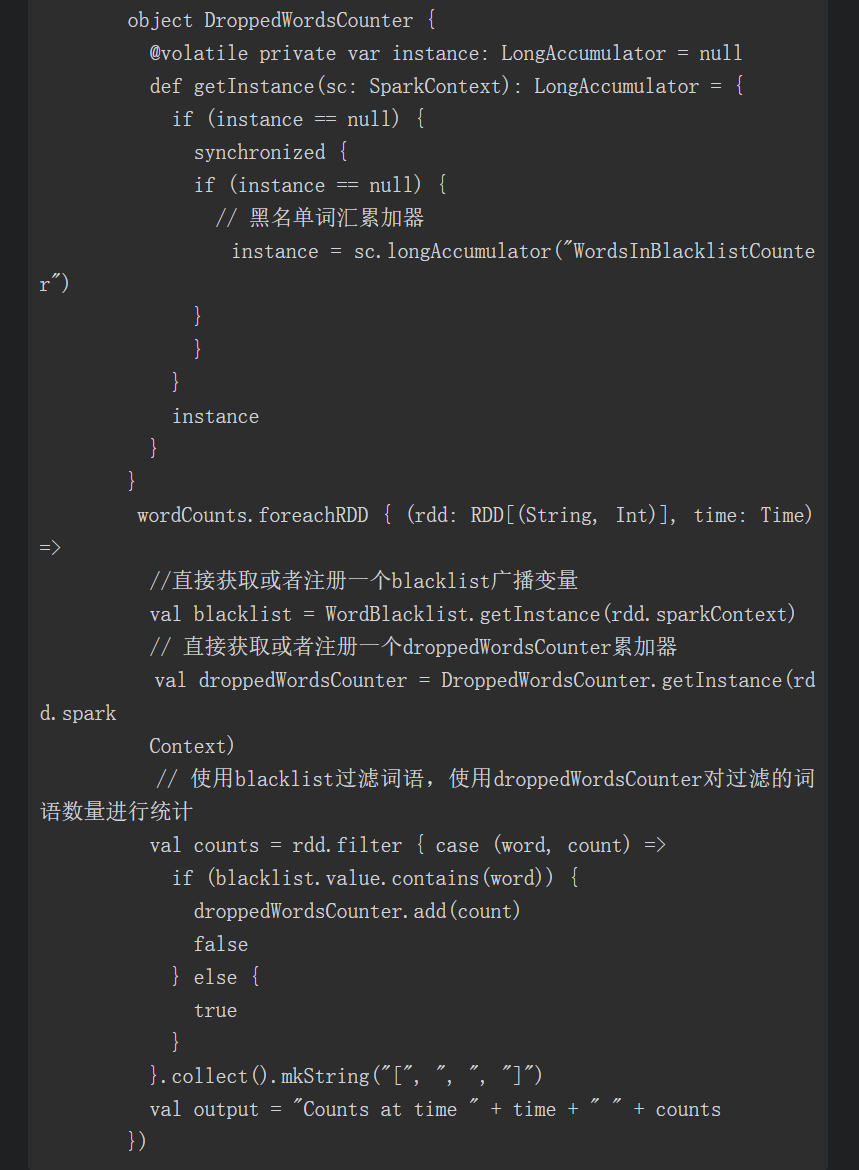
特别说明,关于累加器、广播变量的检查点会有所不同,累加器和广播变量无法从Spark Streaming的检查点恢复。
如果我们开启了检查点(checpointing),并且同时使用了累加器或者广播变量,那么必须为累加器和广播变量创建一个惰性实例化的单例(lazily instantiatedsingleton instances),从而使得它们能够在Driver重启时能够再次被实例化,代码如下: