概要
俗话说:“十年磨一剑”,Microsoft 通过5年时间的精心打造,于2005年浓重推出Sql Server 2005,这是自SQL Server 2000 以后的又一旷世之作。这套企业级的数据库解决方案,主要包含了以下几个方面:数据库引擎服务、数据挖掘、Analysis Services、Integration Services、Reporting Services 这几个方面,其中Integration Services (即SSIS),就是他们之间的中转站、纽带,将各种源头的数据,经ETL到数据仓库,建立多维数据集,然后进行分析、挖掘并将结果通过Reporting Services 送达给企业各级用户,为企业的规划决策、监督执行保驾护航。
SSIS 其全称是Sql Server Integration Services ,是Microsoft BI 解决方案的一大利器,是Sql Server 2000中DTS 一个升级之作。 无论是功能上,性能上,还是可操作方面都有很大的改进。且看下面的操作界面就可见一斑。
SQL Server 2000 DTS
Sql Server 2008 SSIS
现在很多人都把SSIS 说成是一个ETL (Extract-Transform-Load)工具,我个人觉得不太准确,或许是大家基本上都把他做为ETL 使用,其实SSIS已经超越了ETL的功能,ETL 仅是其中之一,它在其它方面也有非常突出的表现:
(1) 系统维护:
a) 在数据库维护方面:
i. 数据库备份;
ii. 统计信息更新;
iii. 数据库完整性检查;
iv. 索引重建
v. SSIS 包执行;
vi. SSAS 任务处理。
b) 业务处理:
i. 执行SQL 任务。
ii. Web Service 任务。
c) 操作系统维护:
i. WMI事件观察器任务
ii. 文件系统任务。
d) 其它:
i. 执行SQL 任务
ii. 执行进程任务
iii. ActiveX 脚本任务
iv. 脚本任务(VB/C#).
v. 执行Web Service 服务
尤其是上面的第四点,可以执行SQL 任务,可以执行Web Service 服务,可以执行系统进程,可以执行(VB/C#)脚本任务,这给了我们多大想象的空间,还有什么例外的?强啊。不得不佩服务一下。
SSIS 的体系结构主要由四部分组成:Integration Services 服务、Integration Services 对象模型、Integration Services 运行时和运行时可执行文件以及封装数据流引擎和数据流组件的数据流任务(如图):
这是我们初学者必须要了解的,只要明白了这个体系统结构,体会了各组成部分之间的关系,清楚了什么是控制流、什么是数据流,SSIS学起来就不难了。
总之,SSIS 并不简单的是DTS 的一个升级版,除了上面所说的几个方面的改进外,在开发环境方面,Microsoft 还一如继往地发挥着他的优势,与Visual Studio 紧密集成,让开发人员可以在一个更加熟悉,更加方便的平台上设计、开发,大大降低了入门的门槛,加速了学习、开发的进度。它的组成元素也更加对象化,每一个包、每一个任务、每个一控制流、每一个数据流,都是一个独立的对象,有其对应的属性、对应的事件。VB/C# 的脚本任务;变量、属性的参数化,更是让人震撼,几乎是无所不能,无所不可似的(有些夸张了,我不是托,只是感觉比以前强大太多了)。使用起来也并不复杂,只要你安装了SQL Server Integration Services 10.0 服务(SQL 2005 应该是Integration Services 9.0),New project ,选择Integration Services 项目,就可以一睹芳容,亲密感受他的博大与精深了。
数据流任务(上)
数据流任务是SSIS中的一个核心任务,估计大多数ETL包中,都离不开数据流任务。所以我们也从数据流任务学起。
数据流任务包括三种不同类型的数据流组件:源、转换、目标。其中:
源:它是指一组数据存储体,包括关系数据库的表、视图;文件(平面文件、Excel 文件、Xml 文件等);系统内存中的数据集等。
转换:这是数据流任务的核心组件,如果说数据流任务是ETL的核心,那么数据流任务中的转换,则是ETL核心中的核心了。它包含非常丰富的数据转换组件,比如数据更新、聚合、合并、分发、排序、查找等。可以说SQL语句中有的功能,它都基本上运用起来了。
目标:与“源”相对应,也是一组数据存储体。包含表、视图;文件;多维数据集、内存记录集等。
除以上三类组件外,还有一种组件,那就是”流(Flow)“,它形象地显示了数据从”源“,经过”转换“,最后到达”目的“地的一组路径。我们可以利用”流“,来查看数据,添加备注说明等。
下面一幅图,就充分展示了源、转换、目的、流的关系。

下面我们以将IIS Log 导入数据库为例,来介绍如何进行数据流任务开发。
在开发之前,我们先来看看IISlog 的结构,如图:

它基本上记录了网页浏览的所有信息,如日期、时间、客户IP、服务器IP、页面地址、页面参数等很多信息,我们再根据这些信息,在关系型数据库中,建立一张对应表,来记录这些信息。
代码
CREATE TABLE [dbo].[IisLog](
[c_Date] [datetime] NULL,
[c_Time] [varchar](10) NULL,
[c_Ip] [varchar](20) NULL,
[cs_Username] [varchar](20) NULL,
[s_Ip] [varchar](20) NULL,
s_ComputerName varchar(30) null,
[s_Port] [varchar](10) NULL,
[cs_Method] [varchar](10) NULL,
[cs_Uri_Stem] [varchar](500) NULL,
[cs_Uri_Query] [varchar](500) NULL,
[sc_Status] [varchar](20) NULL,
sc_SubStatus varchar(20) null,
sc_Win32_Status varchar(20) null,
sc_Bytes int null,
cs_Bytes int null,
time_Taken varchar(10) null,
cs_Version varchar(20) null,
cs_Host varchar(20) null,
[cs_User_Agent] [varchar](500) NULL,
[cs_Refere] [varchar](500) NULL
) ON [PRIMARY]
万事俱备,下面我们就可以开始ETL的开发之旅了,打开Visual Studio 2008 工具,[文件]-->[新建]-->[项目],选择“Integration Services 项目”,ETL 的开发界面就跃入眼帘,这是从事.Net 开发的朋友们非常熟悉的界面。打开左边“工具箱”,将“数据流任务”拖到主窗口“控制流面板”,如图所示:
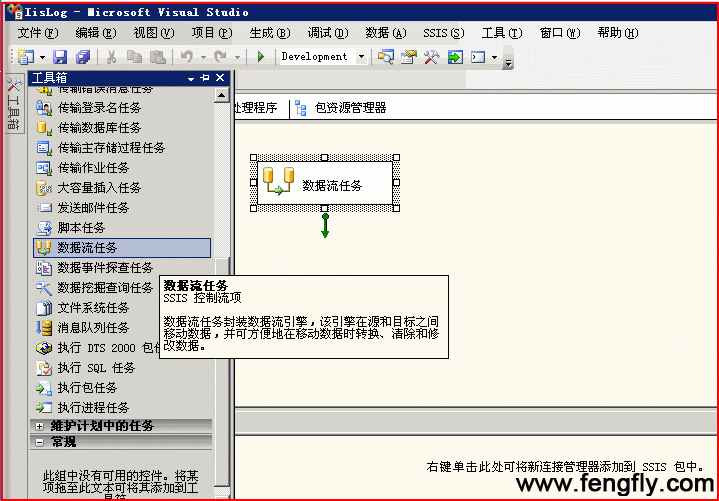
然后双击“控制流”面板上的“数据流任务”,进入“数据流”面板,这两部分UI没有什么差异,只是所实现的功能不同罢了。真正的数据流任务开发,从现在才算开始。
打开左边“工具箱”,可以看到有三大部分:数据流源、数据流转换、数据流目标。我们从“数据流源”中,将“平面文件源”拖到主窗口下,双击打开“平面文件源”编辑器,点击“新建”,打开平面文件连接管理编辑器,如图:

输入连接名称,选择IisLog 文件,选择行分隔符、列分隔符,就可以从预览窗口看到数据的真面目了。
这里有一点要注意,不同的平面文件,其行分隔符、列分隔符都是不一样的,如果选不正确,将达不到你想要的效果,所有的数据都可能挤到一列中去了。一般行分隔比较简单,基本上都是以回车换行({CR}{LF})来分隔;列分隔符却不一样了,它既可以以任意文本字符来分隔,比如逗号(,)、分号(;)、冒号(:)tab符、竖线(|),以及常用的文字字符、数字字符,也可以定义每一列的固定宽度来分隔。这就需要视文件源不一样,分别对待了。
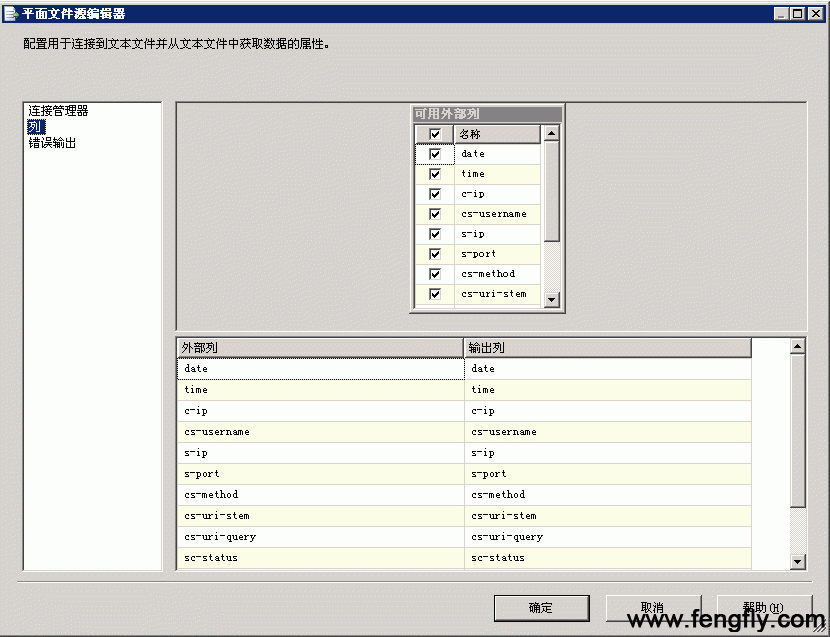
在平面文件连接管理器中,选择“高级”,还可以定义每一列的列名、数据类型、字符长度等信息。 等一切定义完成,点击确定,返回到平面文件编辑器界面,前面建立的连接将自动返回到“平面文件连接管理器”的下拉列表框中,下面就要以选择需要输出的列了,如图:
然后再选择“错误输出”,缺省选项如下图所示:
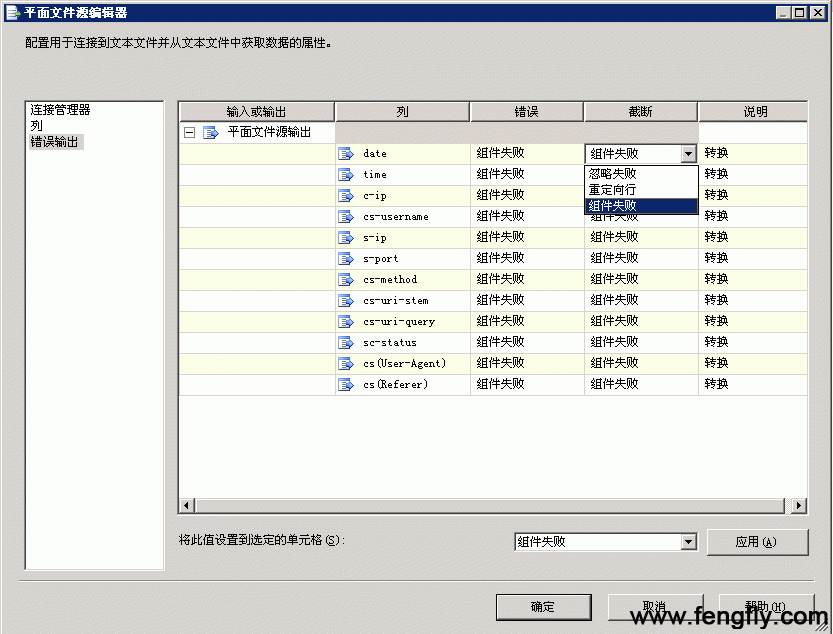
这一选项非常重要,是要求我们配置当源数据发生错误的时候该如何处理,一般源数据发生错误有两种情况:一是数据类型错误,比如日期格式错误、数字变字符了等;另一情况就是字符太长,超出列宽了。根据不同的情况,其处理方式也不一样,系统提供了三种解决办法:
忽略失败:是指如果某一行数据错误,忽略此行,不影响程序执行,继续导入其它数据。
重定向行:将错误的数据行,导入到另外一个数据流目标,供以后人工检查后,再重新处理。
组件失败:这是最严格的,只要遇到数据错误,组件立即失败,停止运行。
就IISLOg 这样的数据源文件来说,有错误数据行,那是是经常发生,但是这些少量数据错误,也不会影响最终的结果,我们就要以考虑容错性为主了,放宽对数据质量的要求,一般选择“忽略错误”,以方便程序继续运行。
一切都定义完后,我们看到“平面文件源”控件上,还有一个红色的叉(X),那是指没有为此数据源定义目标,那就是下一步要定义的。另外下面还有两个长线箭头,一个绿色,一外红色,其中绿色:表示正确数据流通路,红色表示错误数据流通路,如果前面定义错误“重定向行”,那么错误数据将沿着红色路径,流向错误数据存放地。
定义数据源目标,这可能要简单一些了,同理从左边"工具箱"中,看到有很多种类型的数据源目标,我们选择“OLE DB 目标”,将“平面文件源”控件下的绿色箭头连接到“OLE DB 目标”,然后双击,打开“OLE DB 目标编辑器”窗口,“新建”数据库连接,如图:
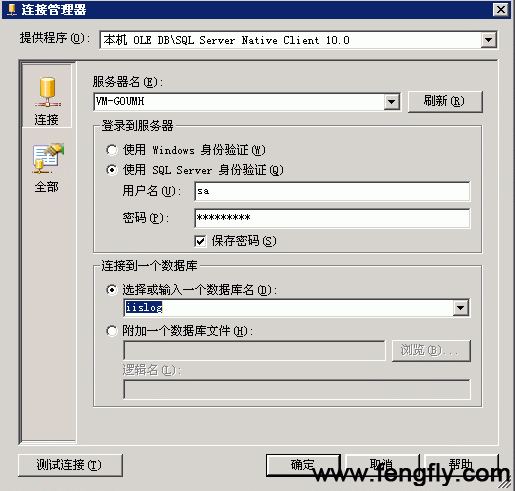
返回到“OLE DB 目标编辑器”窗口,在数据访问模式下,选择“表或者视图--快速加载”一项,然后再选择对应的表,如图:

下面配置列映射,如图:
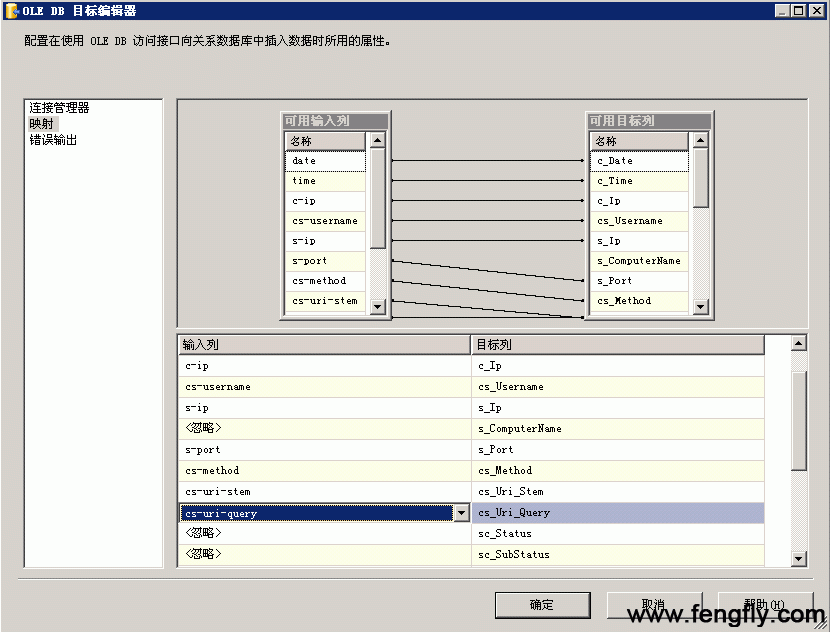
如果没有的列,直接忽略即可(前提是表中该列允许为空),后面仍然是配置错误处理方式,参照平面文件源错误处理方式即可。
到此为止,一个简单的数据流任务就基本上完成了,点击运行,我们期待已久的结果出现了。
当然,在实际开发过程中,可能并没有这么顺利,会遇到很多各种各样的问题,在这篇文章中我们很少提及,主要是因为这仅是个开始,没有涉及到这么深入,在以后的专题中,会逐渐讲解。
一个简单的数据源任务就算完成了,其实这只是一个Demo ,让大家了解了一个概况,可以说万里长城只是走出了第一步,真正的ETL不会这么简单。下后面我们将介绍ETL最精彩的部分“数据流转换”,敬请期待。
数据流任务(下)
数据流任务(上),介绍了如何创建一个简单的ETL包,如何通过一个简单的数据流任务,将一个文本文件的数据导入到数据库中去。这些数据都保持了它原有的本色,一个字符不多,一个字符地少导入,但是在实际应用过程中,可能很少有这种情况,就拿IisLog文件来说吧,其中包含有:请求成功的记录(sc-Status=200),也有请求失败的记录;有网页(比如:*.aspx、*.htm、*.asp、*.php等)、有图片、有样式表文件(*.CSS)、有脚本文件(*.js)等,可谓是鲜花与毒草并存,精华与糟铂同居啊,我们如何根据不同的需求,把其中的鲜花与精华提炼出来呢,这就是我们今天要讲的重点:数据流转换。
在进行数据流转换之前,我们先介绍一下使用场景:以IISLOG为依据,进行网站点击率分析(IP & PV 分析),具体需求如下:
(1)分析一段时间内,网站点击率的变化趋势。同时还需要知道各个周未、各个节假日网站的流量情况。
(2)分析一天内,各时段(以小时为单位)网站的压力情况。
(3)了解网站客户群分别来自哪些国家,哪些地区。
为了实现这些需求,我们建立了如下的数据模型,请看:

代码
USE [IisLog]
GO
--建立事实表
CREATE TABLE [dbo].[IISLog](
[lngID] [bigint] NOT NULL,
[lngShopID] [int] NULL,
[lngDateID] [int] NULL,
[lngTimeID] [int] NULL,
[csDateTime] [datetime] NULL,
[lngIpID] [int] NULL,
[cIP] [varchar](30) NULL,
[csUriStem] [varchar](1000) NULL,
[csUriQuery] [varchar](1000) NULL,
[scStatus] [varchar](30) NULL,
[UserAgent] [varchar](255) NULL,
[lngReferer] [int] NULL,
[csReferer] [varchar](1000) NULL,
[csRefererKPI] [varchar](1000) NULL,
[lngFlag] [int] NULL
) ON [PRIMARY]
--IP库
CREATE TABLE [dbo].[dimIP](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[ipSegment] [nvarchar](20) NULL,
[strCountry] [varchar](20) NULL,
[strProvince] [varchar](20) NULL,
[strCity] [varchar](50) NULL,
[strMemo] [varchar](100) NULL,
CONSTRAINT [PK_ID] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
--日期
CREATE TABLE [dbo].[dimDate](
[lngDateID] [int] NOT NULL,
[lngYear] [int] NULL,
[strMonth] [varchar](10) NULL,
[dtDateTime] [datetime] NULL,
[strQuarter] [varchar](10) NULL,
[strDateAttr] [varchar](10) NULL,
[strMemo] [varchar](50) NULL,
CONSTRAINT [PK_dimDate] PRIMARY KEY CLUSTERED
(
[lngDateID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
--时间
CREATE TABLE [dbo].[dimTime](
[lngTimeID] [int] NOT NULL,
[lngHour] [int] NULL,
[strHour] [varchar](10) NULL,
[strTimeAttr] [varchar](10) NULL,
[strMemo] [varchar](50) NULL,
CONSTRAINT [PK_dimTime] PRIMARY KEY CLUSTERED
(
[lngTimeID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
下面,我们就一步一步地介绍,如何进行数据流转换,以达到上面的需求。
(一)、"条件性拆分(Conditional Split )"。相当于Sql 语句的Where 条件。这或许是所有数据流转换任务的第一步,为了减少后续处理的数据量,为了提高系统性能,先过滤掉不需要的记录。前面讲过,IisLog 文件包括有各式各样的记录,而对本例需求来说,为了准确计算IP、PV数据,我们将如何过滤呢?
(1)、筛选出纯网页浏览记录。即*.aspx、*.htm(本网站只有这两种类型的网页文件)文件记录。
(2)、筛选出请求成功的记录(sc-Status=200)。
打开上一篇文件的SSIS Solution,切换到数据流Tab,从左边工具箱中,打开“数据流转换”,找到“条件性拆分(Conditional Split)”组件,拖到数据流面板上,然后将“平面文件源”组件下的绿色箭头拖到“条件性拆分”组件上,双击“条件性拆分”组件,打开“条件性拆分转换编辑器”,如图:
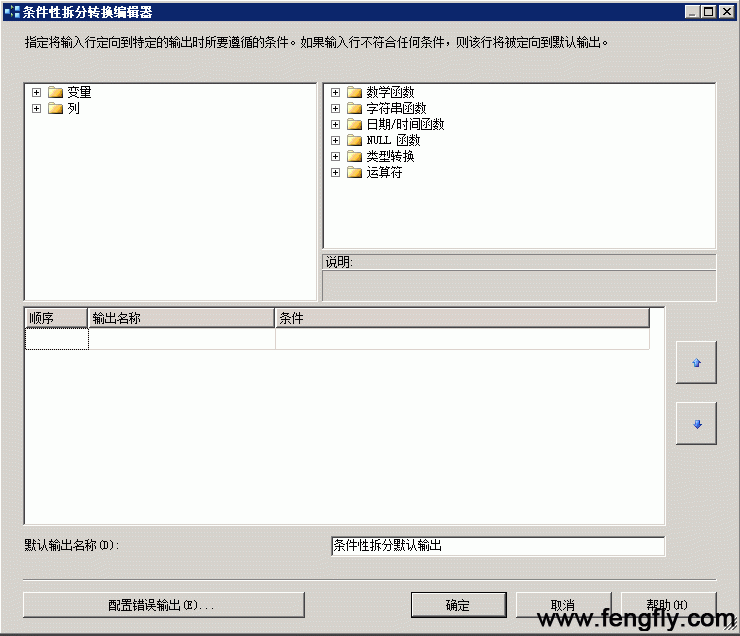
在这个窗口,有系统变量、数据源列、系统函数这些资源可供使用。我们为了筛选出纯网页浏览记录,需要从列cs_uri_stem中找到以.aspx、.htm、“/” 结尾的页面链接。请分别在上图列表的“输出名称”栏位,输入“Form Records”,在条件表达式栏位输入:
RIGHT(cs_uri_stem,5) == ".aspx" || RIGHT(cs_uri_stem,4) == ".htm" || RIGHT(cs_uri_stem,1) == "/"
然后筛选请求成功的记录,其表过式为:
sc_status == "200"
最后将两个表达式组合起来,即为:
(RIGHT(cs_uri_stem,5) == ".aspx" || RIGHT(cs_uri_stem,4) == ".htm" || RIGHT(cs_uri_stem,1) == "/") && sc_status == "200"
如图所示:

点击确定.数据过滤就算大功告成了。
(二)、派生列(Derived Column),相当于SQL语句中的计算列,即根据其它列,按照一定的计算公式,派生出一个新列。在此例中,有三种情况需要用到派生列:
(1)日期列,从log文件导入的日期、时间,为两个独立的字符串(varchar),而数据库中的对应字段为Datetime 型,如果要想建立一种映射,则需要根据log 文件的Date 、time 字段,派生出一个Datetime 型的字段。
(2)时间段,同理log 文件中的Time 为一字符串,需要取出其中的“小数(hour),才能与dimTime 中的lngHour 相匹配。
(3)IP,我们想根据客户IP,确定他所在国家、省市、地区。要达到这一需求,我想并不需要IP完全匹配,只要IP的前三段匹配,就可以确定了(没有考证过,个人感觉而已,如不妥,请指正),所以需要派生出一个ipSegment =IP的前三段,以此映射他所在的地区。
同理,从工具箱中,将“派生列”组件拖到“条件拆分”组件的下方,再将“条件拆分”组件下方的绿色箭头拖到“派生列”组件上,系统会弹出一窗口,要求选择条件拆分的的输出名称,如图:
从下拉列表框中选择“Form Records”,点击确定。
然后再双击“派生列”组件,打开“派生列转换编辑器”,如图:
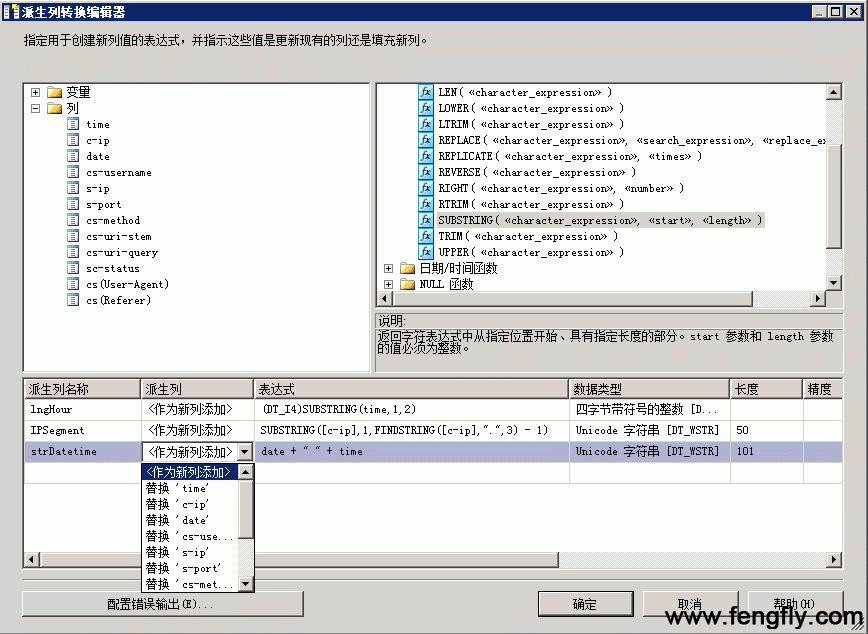
这个窗口太眼熟了吧,那不是前面讲的“条件性拆分编辑窗口”吗?是的,非常类似,我就不罗嗦了,按图上要求,输入派生列名称,选择派生类型,输入表达式,后面的数据类型、数据长度、精度等属性,将根据派生表达式自动生成,一般是不允许修改的。
(三)、数据类型转换。在Integration Services 中,数据类型匹配要求是相当严格的,尤其是后面要讲的查找(Lookup)组件,数据类型必须绝对匹配,才能Join ,否则将不成功。
Integration Services 中的数据类型,它为了兼容多种数据源(比如平面文件、MssQL、ORACLE、DB2、MYSQL等),在形式上它不同于前面说的任何一种数据源的数据类型,一旦数据进入Integration Services 包中的数据流中时,数据流引擎就会将这些列的数据转换为Integration Services 的数据类型,前面介绍的“条件性拆分”、“派生列”中的表达式,都是对这种Integration Services类型的数据进行操作。所以如果后面要应用到查找(Lookup)组件,就必须要对这种数据类型进行转换,才可以与查找源(关系型数据库中的表或视图)的列匹配。具体操作为:
从工具箱中,将“数据转换”组件拖到窗口上,将上一组件(派生列)组件下面的绿色箭头拖此组件上,双击打开“数据转换组件”,如图:
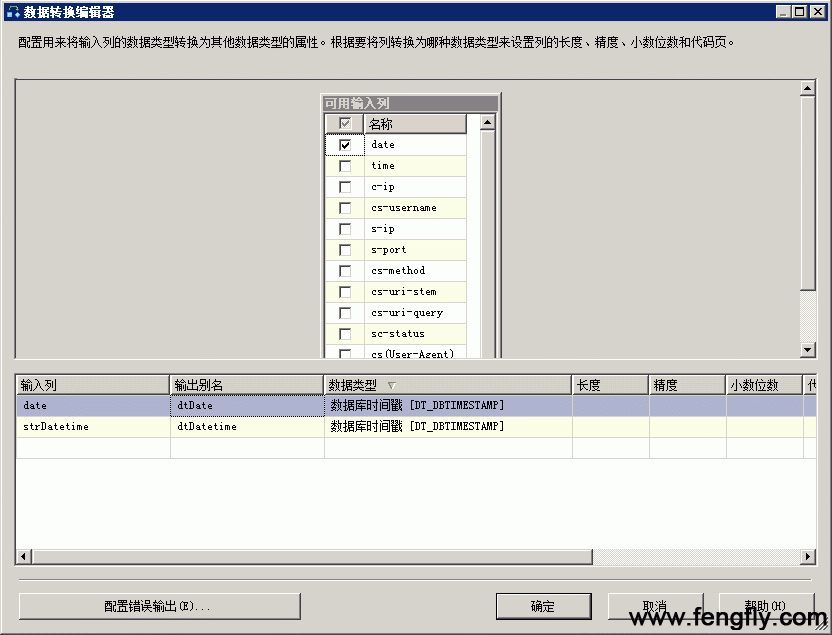
勾选要进行数据类型转换的列:Date,strDatetime,将它们转换MSSQL的Datetime 类型。
特别说明一下,Integration Services数据类型与其它关系型数据库的数据类型之间的关系是比较复杂,如果凭空猜想,很难找到它们之间的对应关系,请参考Microsoft 说明文档,那里面有非常详细的说明。Integration Services 数据类型
(四)、查找(Lookup),类似于Sql 中的Left Join 、Right Join ,一般可以实现两方面的功能:(1)输出匹配的项;(2)、输出无匹配项,这个功能在ETL中应用是相当频泛的,如果善加利用,可以实现很多功能。前面两种数据流转换(派生列、数据类型转换)都是为Lookup 铺路搭桥的。在这个例子,有三个列需要查找,IP、Date、Time。只要一切准备工作就绪,Lookup 就容易多了。
将“查找(Lookup)”组件拖到窗口中,连接上一组件的绿色箭头,双击打开“查找转换编辑器”,如图:

这可比以前的编辑器,复杂一些了吧,其实也并没有那么可怕,如果一般用用,很多地方都按Default 设置,那也是很容易的。但是ETL的性能,在这一步是蛮关键的。首先看缓存模式:
完全缓存:是指在查找转换前,先把引用数据集,完全缓存在内存中,供以后查找时用。
部分缓存:在执行“查找转换”时生成引用数据集,并将有匹配的数据行加载到缓存中,没有匹配的数据行则丢弃。
无缓存:在执行“查找转换”的过程中生成引用数据集,但不加载入缓存。
通过上面的解释,利弊已经很明显了,不同的情况,可能需要不同的处理策略,自已权衡吧。
连接类型,实际上也很清楚了,就不多说了。
指定如何处理无匹配的行:这一选项非常重要,共有四个选项:
忽略失败:就是说遇到无匹配的项,忽略,程序继续执行。
将行定位到错误输出:无匹配的记录,通过错误数据流路径(红色箭头)输出,供以后人手分析处理。
组件失败:如果遇到无匹配的项,组件立即失败,程序停止执行。
将行定位到无匹配输出:输出无匹配的记录集。此选项通常用于查找是否有新的记录产生,如果有新记录出现,则导入,已有匹配的记录集忽略。本例中,IP查找将会用这一选项,如果遇到一个新IP,则插入到数据仓库中,否则,就则忽略此记录,不再重复插入了。
选择“连接”,如图:

选择连接管理器IisLog,在表或者视图拉列框中选择“dimDate“。
切换到“列”,将[可用输入列]中的“dtDate”拖到[可用查找列]的“dtDatetime”,两个字段间w会连一条直线,表示相互建立连接关系,前面说过,如果这两列的数据类型不一致,这种关系将无法建立。最后在“可用查找列”中勾选“lngDateID”,作为输出。点击确定,lngDateID 的查找就完成了。
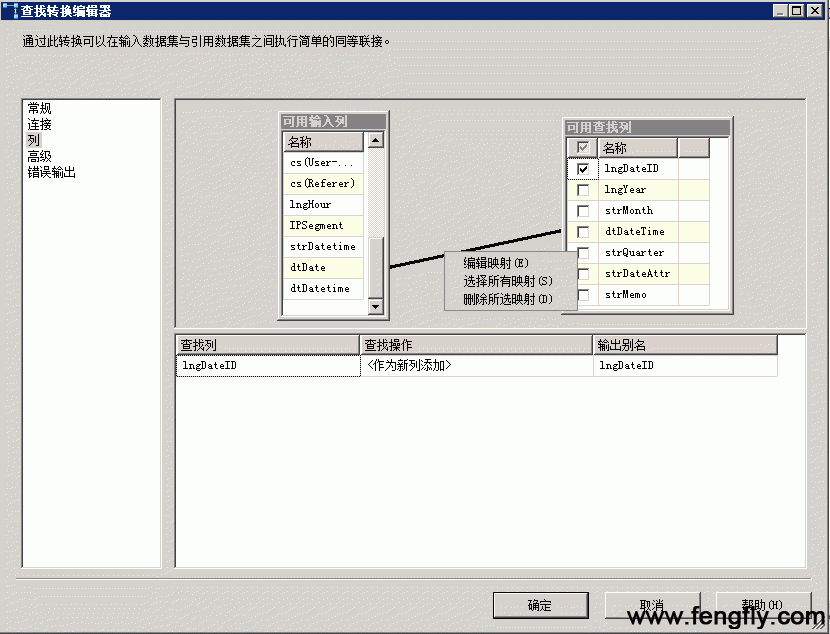
其它两个,有兴趣的朋友可以自动手试试,看能否成功。
这样,数据转换就算完成了,最后接着上课的数据流目标,将源列与目标映射起来,如图:
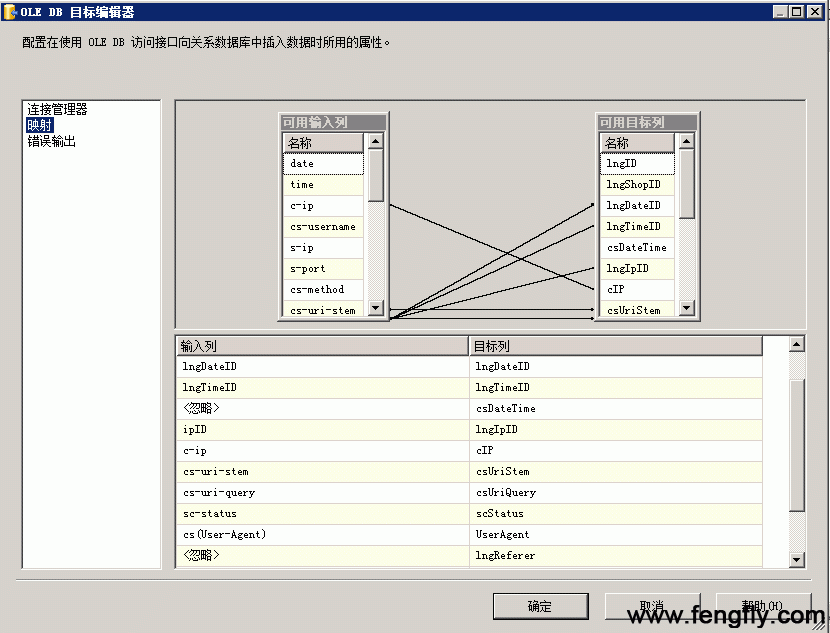
点击“运行”,梦想中的绿色境界,就出现了。

源码下载:IisLog 源码下载