预备软件:
使用的是CentOS 6.0、hadoop-1.0.4
Jdk使用的是jdk-6u29-linux-i586-rpm.bin
文档帮助:
Hadoop-1.0.4 文档 http://hadoop.apache.org/docs/r1.0.4/
单机安装指南 http://hadoop.apache.org/docs/r1.0.4/single_node_setup.html
集群安装指南 http://hadoop.apache.org/docs/r1.0.4/cluster_setup.html
摘要
本文将介绍在CentOS中如何安装Hadoop,安装之前需要哪些预备环境。安装过程中需要配置哪些文件。Hadoop支持三种模式,分别为
- Local (Standalone) Mode
- Pseudo-Distributed Mode
- Fully-Distributed Mode
文中将使用hadoop自带的wordcount示例在Local (Standalone)模式和Pseudo-Distributed模式下进行测试。
安装及测试过程
1、安装jdk
[root@localhost ~]# cd /usr [root@localhost usr]# mkdir java [root@localhost usr]# cd java [root@localhost java]# pwd /usr/java [root@localhost java]# /mnt/hgfs/share/jdk-6u29-linux-i586-rpm.bin
2、解压Hadoop
[root@localhost java]# tar -zxvf hadoop-1.0.4.tar.gz
3、设置hadoop的JAVA_HOME环境变量
在usr/java/hadoop-xxx/conf/目录下找到hadoop-env.sh文件,打开后,编辑
[root@localhost java]# cd /usr/java/hadoop-1.0.4/conf/
如果该文件属于只读性质,那么需要更改文件的读写权限:
[root@localhost ~]# ll /usr/java/hadoop-1.0.4/conf/hadoop-env.sh -rw-r--r--. 1 1002 1002 2430 Dec 3 2011 /usr/java/hadoop-1.0.4/conf/hadoop-env.sh [root@localhost ~]# chmod 777 /usr/java/hadoop-1.0.4/conf/hadoop-env.sh [root@localhost ~]# ll /usr/java/hadoop-1.0.4/conf/hadoop-env.sh -rwxrwxrwx. 1 1002 1002 2430 Dec 3 2011 /usr/java/hadoop-1.0.4/conf/hadoop-env.sh
更改好权限以后将文件打开,并添加JAVA_HOME路径为/usr/java/jdk-xxx
[root@localhost ~]# gedit /usr/java/hadoop-1.0.4/conf/hadoop-env.sh
在文件中添加如下环境变量
export JAVA_HOME="/usr/java/jdk1.6.0_29"
保存,退出gedit。
现在改好hadoop-env.sh配置文件后,需要把它之前的权限给恢复。
可以看到文件权限有10位,第一位指得是文件的类型,“-”标示的是普通文件,“d”指的是目录文件。剩下的9位分别代表三种角色,即“文件主 组用户 其他用户”对此文件的权限,r指读,w指写,x指执行。
原始的文件权限为“-rw-r--r--”,即它只对文件主才开放读写功能,对其他用户均是只读。而改变后的文件权限为“-rwxrwxrwx”,即它对所有用户角色都开放了读写及执行功能。
为了安全,在设置完JAVA_HOME环境变量后,应该恢复文件的权限。
可以使用chmod指令(change mode的缩写)+数字的方式来改变文件的权限。各个数字代表的含义是:0表示没有权限,1表示可执行权限,2表示可写权限,4表示可读权限,然后将其相加。所以数字属性的格式应为3个从0到7的八进制数,其顺序是(u)(g)(o)。u、g、o分别代表文件主 组用户 其他用户。所以,我们用指令644就可以将文件恢复到之前的权限了。
命令为:
[root@localhost ~]# chmod 644 /usr/java/hadoop-1.0.4/conf/hadoop-env.sh
使用ll指令查看文件当前的权限:
[root@localhost ~]# ll /usr/java/hadoop-1.0.4/conf/hadoop-env.sh
-rw-r--r--. 1 1002 1002 2470 Jan 4 18:33 /usr/java/hadoop-1.0.4/conf/hadoop-env.sh
可以看到文件的访问权限已经恢复到之前的状态了。
4、Hadoop单机模式(Local (Standalone) Mode)
在hadoop解压文件下,有一个“hadoop-mapred-examples-0.22.0.jar”包,使用以下指令可以查看该jar的内容。
[root@localhost hadoop-1.0.4]# jar tf hadoop-examples-1.0.4.jar
执行结果截取一部分显示:

可以看到里面有一个
org/apache/hadoop/examples/WordCount.class
这与刘鹏在《云计算》一书中用的例子相同,我们就用这个做实验好了。借用刘鹏在书中的例子,输入以下指令,新建一个input文件夹,在文件夹中新建两个文件,分别输入“hello word”和“hello hadoop”,然后使用示例的wordcount程序统计各个单词出现的概率。指令如下:
[root@localhost hadoop-1.0.4]# mkdir input [root@localhost hadoop-1.0.4]# cd input [root@localhost input]# echo "hello world">test1.txt [root@localhost input]# echo "hello hadoop">test2.txt [root@localhost input]# cd .. [root@localhost hadoop-1.0.4]# bin/hadoop jar hadoop-examples-1.0.4.jar wordcount input output
运行结束后,可以看到hadoop文件夹下多了一个output文件夹,打开文件夹可见两个文件

打开其中的part-r-00000文件,可见单词的统计结果
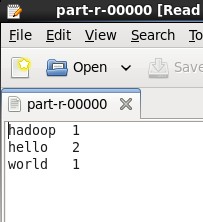
或者使用cat指令直接查看output文件夹下的输出也可以:
[root@localhost hadoop-1.0.4]# cat output/* hadoop 1 hello 2 world 1
关于workcount这个示例的更详细介绍可以查看这篇文章 -》地址 http://www.hadooper.cn/dct/page/65674
5、Hadoop的配置文件
打开hadoop目录下的conf目录可以看到有16个文件:

hadoop-env.sh
右上角的hadoop-env.sh之前我们已经用到过了,在里面配置了JAVA_HOME环境变量。并且由env这个缩写也可以大概猜到是environment,所以这个文件主要是做环境变量的配置的。
core-site.xml
hadoop core的配置项,该文件主要用来配置全局性的参数具体的配置模版可参考【官方core-site.xml模版】 。hadoop core提供了一套分布式文件系统以及支持Map-Reduce的计算框架。HBase、Pig等都是在hadoop core之上搭建的。
hdfs-site.xml
hadoop守护进程的配置项,包括namenode、辅助namenode和datanode等。里面设置了诸如namenode的地址、datanode的地址等参数。配置模版可参考【官方hdfs-site.xml模版】
mapred-site.xml
mapreduce守护进程的配置项,包括jobtracker和tasktracker。具体参数及释义可参看【官方mapred-site.xml模版】。
log4j.properties
用来记录系统日志。log4j是apache旗下的一个日志记录项目。【log4j项目地址】
fair-scheduler.xml
右上角第二个文件fair-scheduler.xml,用火狐打开来看看,如下图所示:

进入【fair_scheduler官方用法说明】 可以看到对这一配置文件的介绍。由Introduction中的“Fair scheduling is a method of assigning resources to jobs such that all jobs get, on average, an equal share of resources over time.Fair scheduling is a method of assigning resources to jobs such that all jobs get, on average, an equal share of resources over time.”可知该文件用来实现一种资源配置,以保证所有的jobs都可以公平的获得资源。
在这些配置文件中,最基本的就是hadoop-env.sh、core-site.xml、hdfs-site.xml和 mapred-site.xml。其中,第一个是用来设定hadoop运行所需的环境变量。
众所周知,hadoop由最基本的HDFS+MapReduce构成。HDFS由NameNode和DataNode组成。MapReduce计算模型又由job和track来完成。core-site.xml、hdfs-site.xml和 mapred-site.xml这三个文件就是用来对NameNode、DataNode、job、track进行基本配置的。
其他配置文件的大致功能可以参见ggjucheng的日志【hadoop配置文件说明】。
6、Hadoop伪分布模式(Pseudo-Distributed Mode)
伪分布模式在官网中的描述是“Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process.”大意为使用java进程来模拟Hadoop的各个守护进程。
6.1设置参数
进行伪分布模式的测试前,要对刚才提到的core-site.xml、hdfs-site.xml和mapred-site.xml三个文件进行配置(建议在vi中进行),分别为:
core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
mapred-site.xml
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
6.2 设置无密码登录SSH
Hadoop的分布式计算需要各个计算节点(server)的协作,人工输入密码这一方式显然是行不通的,因此节点与节点间进行通信时,需要用到SSH自动登录机制。那么,先尝试使用指令ssh localhost, 看能否进行无密码的SSH连接。
[root@localhost ~]# ssh localhost
root@localhost's password:
提示输入密码,失败。转入以下步骤,输入指令来产生一对密钥:
[root@localhost ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
提示:

这个操作主要就是产生一对密钥,相当于client和server之间产生某种暗号,只要暗号对上了就当做它有权限接入,而不用再手工输入密码了。ssh-keygen的用法可以参考石头儿转载的这篇日志【ssh-keyken 中文手册】
现在/root/.ssh/目录下有一个私钥id_dsa和一个公钥id_dsa.pub文件。将公钥导入到本机的授权密钥文件中authorized_keys 。
作者注:如果是真正的分布式集群,还需要将该公钥传送到其他服务器节点,并导入到它们的authorized_keys文件中,因为现在是伪分布式,也就是只有一个节点,因此只要导入到本机即可。真正的分布式SSH的无密码登录可以参见-free_coder-的日志【CentOS 下SSH无密码登录的配置】
进入.ssh目录
[root@localhost ~]# cd /root/.ssh
导入公钥
[root@localhost .ssh]# cat id_dsa.pub >> authorized_keys
6.3 运行Hadoop
在正式运行之前,要先对NameNode节点进行格式化,为什么要进行格式化参见—读程序的手艺人—的日志【NameNode的format操作做了什么】。
具体的指令是:
[root@localhost hadoop-1.0.4]# bin/hadoop namenode -format
NameNode格式化完成后,就可以运行hadoop了。指令为:
[root@localhost hadoop-1.0.4]# bin/start-all.sh
输出如下:
starting namenode, logging to /usr/hadoop-1.0.4/libexec/../logs/hadoop-root-namenode-localhost.localdomain.out localhost: starting datanode, logging to /usr/hadoop-1.0.4/libexec/../logs/hadoop-root-datanode-localhost.localdomain.out localhost: starting secondarynamenode, logging to /usr/hadoop-1.0.4/libexec/../logs/hadoop-root-secondarynamenode-localhost.localdomain.out starting jobtracker, logging to /usr/hadoop-1.0.4/libexec/../logs/hadoop-root-jobtracker-localhost.localdomain.out localhost: starting tasktracker, logging to /usr/hadoop-1.0.4/libexec/../logs/hadoop-root-tasktracker-localhost.localdomain.out
在浏览器中输入地址http://localhost:50030/可观察jobtracker的情况。如下图:

在浏览器中输入地址http://localhost:50070可以查看当前hadoop的文件系统的的状态

还可以使用web接口查看file system

或者查看文件系统日志

http://localhost:50060 地址可以查看task的运行情况。
6.4 实例测试
6.4.1 数据准备
之前我们在单机模式中使用过workcount这个功能,现在在伪分布情况下再进行测试。
先将之前input文件夹拷贝到HDFS目录中做准备,重命名为inputTest。
[root@localhost hadoop-1.0.4]# bin/hadoop dfs -copyFromLocal input inputTest
我们再到刚才的http://localhost:50070地址中查看是否出现了一个新的目录。

果然,在user/root目录下多了一个inputTest目录。点击去可以看到之前我们测试时新建的两个文件:test1.txt和test2.txt。

回忆一下,test1.txt中的字符串是"hello world";test2.txt中的字符串是"hello hadoop"。所以,每个文件本身的大小是很小的。
但是,看看它们的block size,都是64MB。将block定义得很大的原因Tom White在《Hadoop: The Definitive Guide》page 43中有阐述:
“HDFS blocks are large compared to disk blocks, and the reason is to minimize the cost of seeks. By making a block large enough, the time to transfer the data from the disk can be made to be significantly larger than the time to seek to the start of the block.”
简单来说,就是希望传输一个block数据的时间能大于找到这个block的时间,让更多的时间花在数据传输上而不是数据定位上。
6.4.2 运行测试程序
运行程序的指令跟之前是一样的,只要替换掉输入/输出的目录即可。
[root@localhost hadoop-1.0.4]# bin/hadoop jar hadoop-examples-1.0.4.jar wordcount inputTest outputTest
运行过程中查看tasktrace可以看到job和task的状态:

运行结束后,可以看到文件系统中多了一个目录outputTest

使用指令查看运行结果:
[root@localhost hadoop-1.0.4]# bin/hadoop dfs -cat outputTest/* hadoop 1 hello 2 word 1
6.5 停止Hadoop
指令为
alhost hadoop-1.0.4]# bin/stop-all.sh
输出信息显示:
stopping jobtracker
localhost: stopping tasktracker
stopping namenode
localhost: stopping datanode
localhost: stopping secondarynamenode
可以看出,在hadoop运行过程中,有5个守护进程。
(daemon翻译成“后台程序”或“后台进程”会不会好点呢?)
Reference
1、Tom White,《Hadoop: The Definitive Guide》
2、刘鹏,《云计算(第2版)》
3、Apache Hadoop,《Single Node Setup》
扩展阅读
1、中国科学院计算技术研究所 网络科学与技术重点实验室,《Hadoop编程入门》
介绍了Hadoop程序员需要完成的工作,hadoop程序在三种不同模式下的运行方式,以及hadoop的效率。