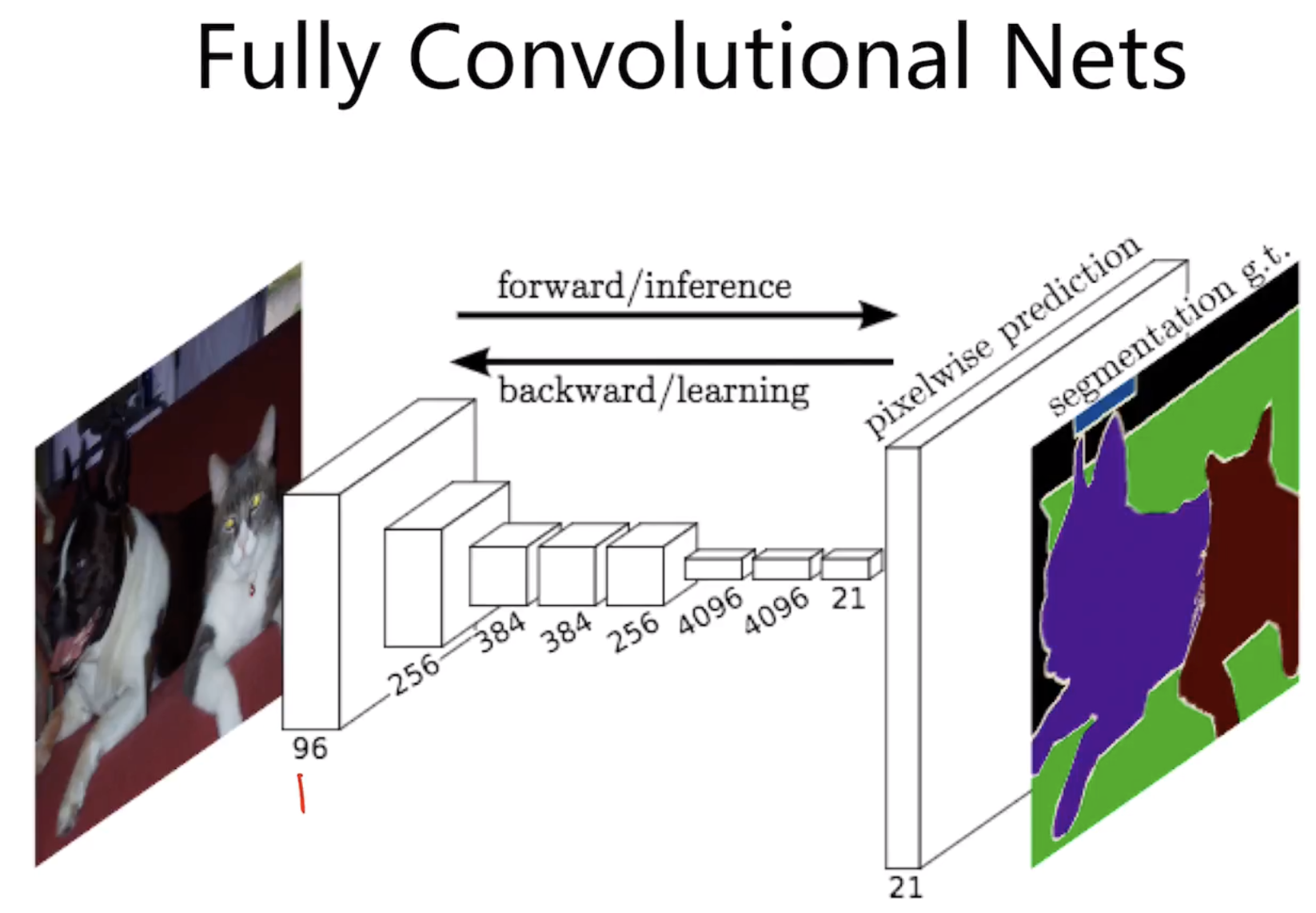
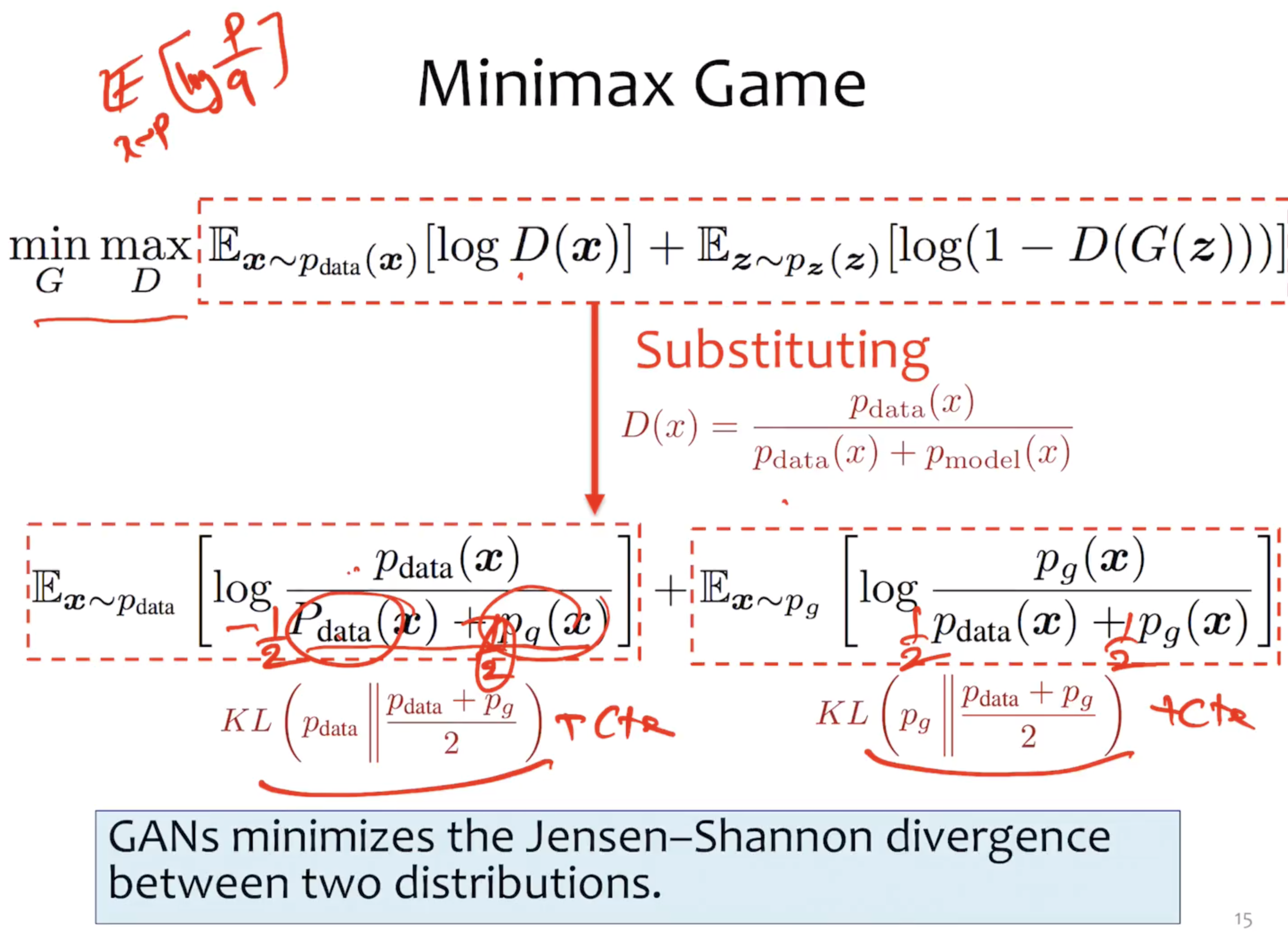
take log to Normal distribution, it's L2 loss, which might be the cause of the blurry results of VAE
interpreting the meaning of latent vars is difficult


like a stretching: stretch left ones to more left and right ones to more right





we cant really tell which animal is exactly. seems like they are combinations of different animals.

mode collaspe is a problem that hasn't been resolved yet.

three eyes... => counting issues




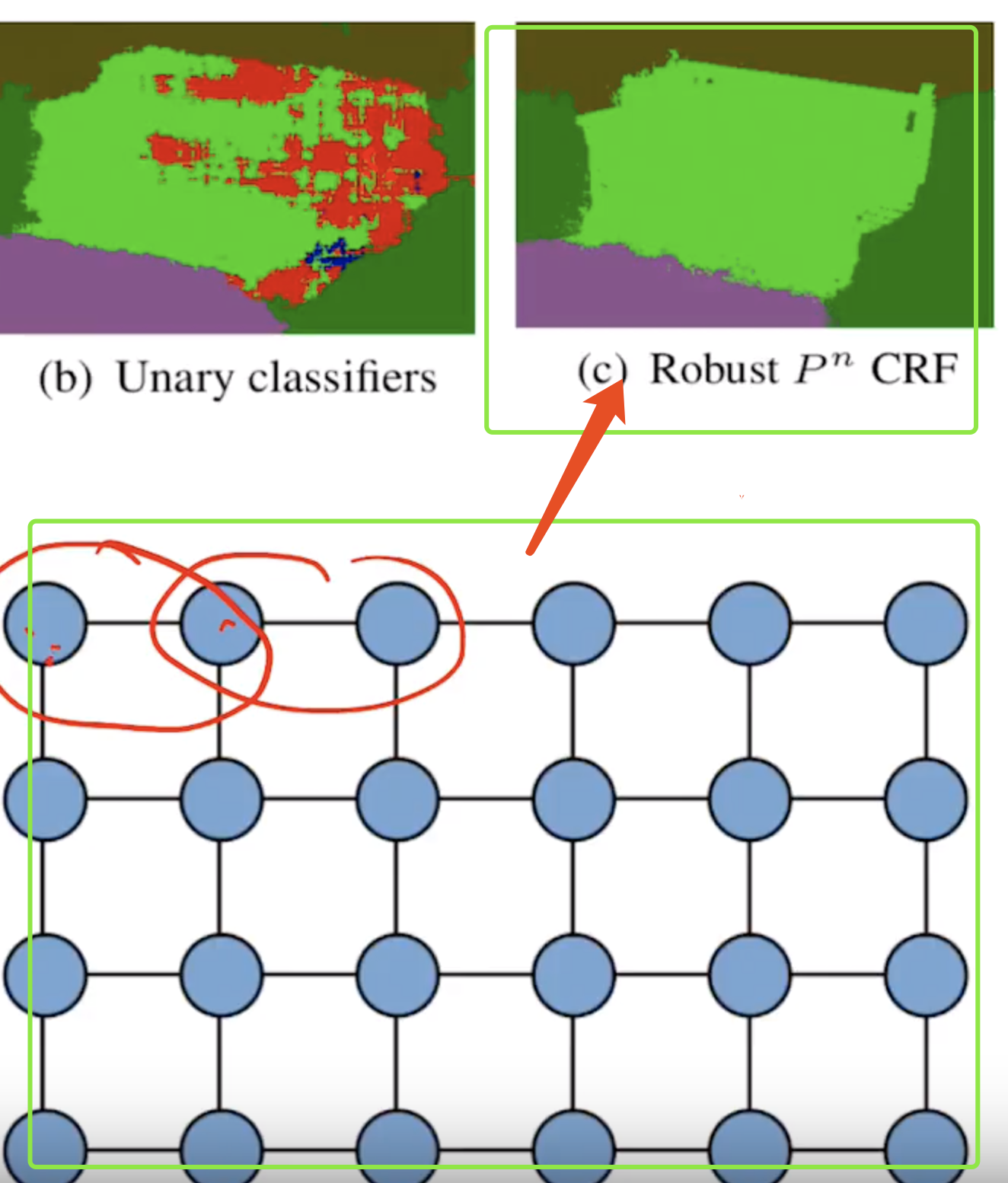
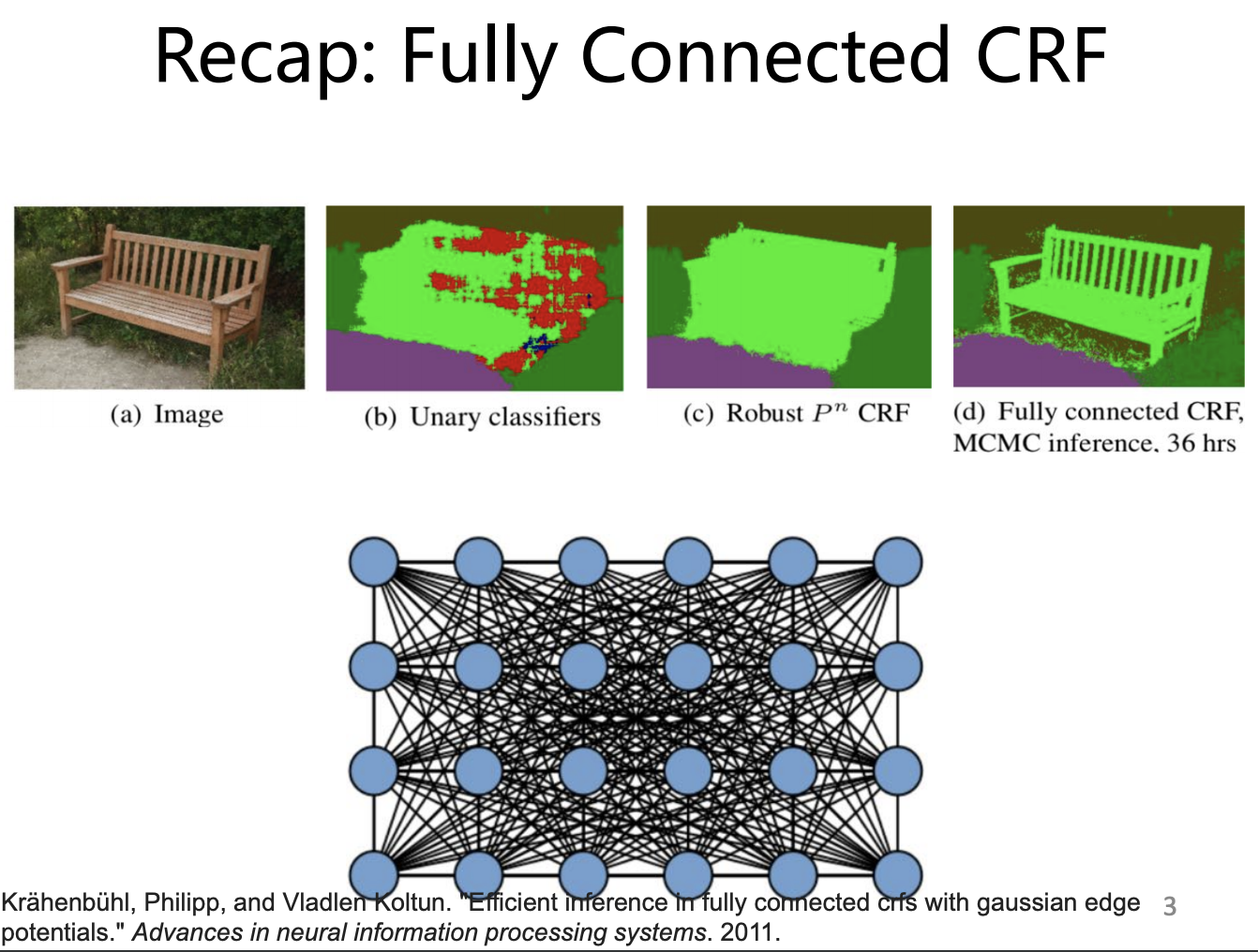
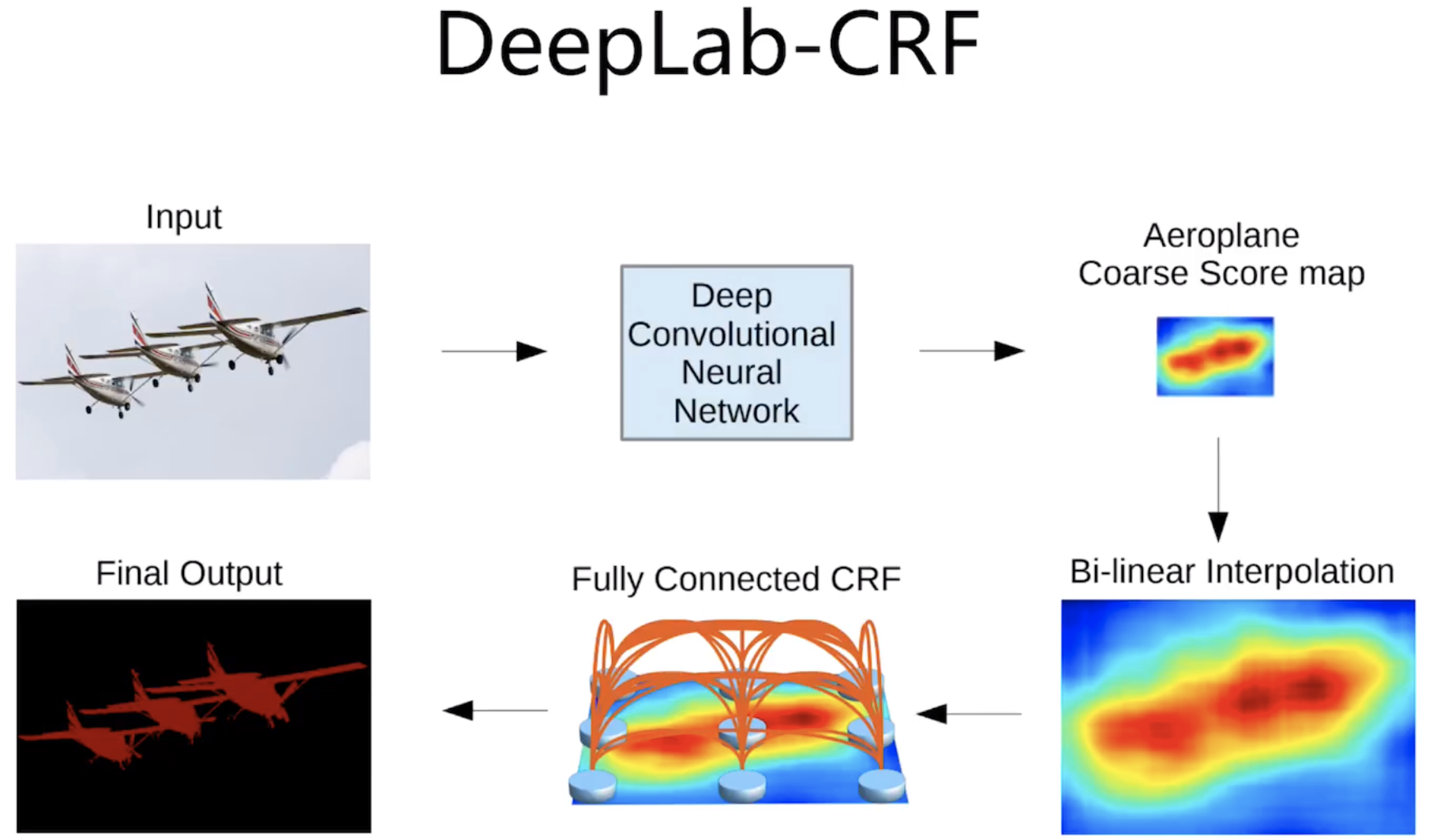
larger model (fully modelled CRF has much better results, but meanwhile lead to the much more computational cost)



smooth kernel: local similarity
apperaance kernel: location similarity and feature similarity
so ususlly w1 > w2

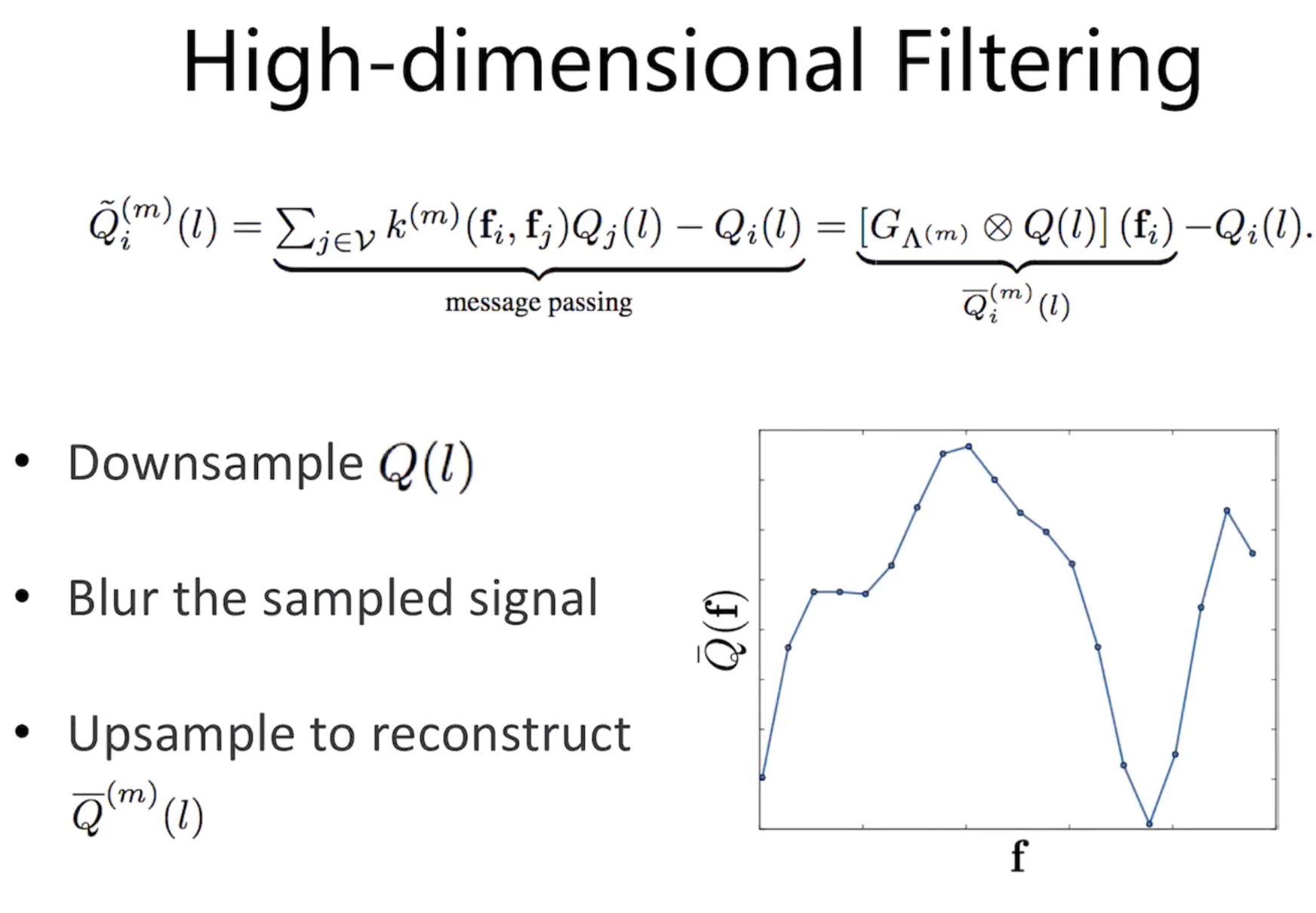
do the low-pass filtering and simplize it by convolution
a moving kernel

0 iteration: from an unary classifier
10 iteration: through CRF