二、实验内容
1.虚拟机集群搭建部署hadoop
安装VM

在VM中安装Linux
在linux中安装hadoop
2.HDFS文件操作
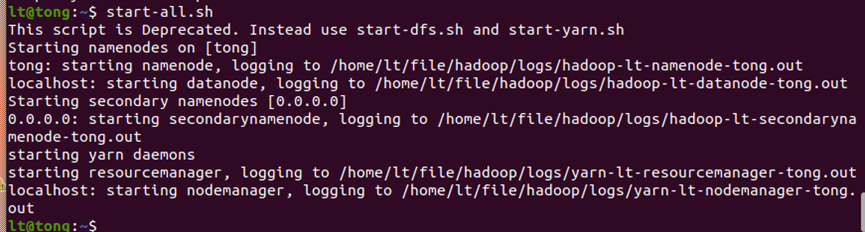
启动hadoop
上传文件

3.MAPREDUCE并行程序开发
3.1 求每年最高气温
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Temperature { /** * 四个泛型类型分别代表: * KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...) * ValueIn Mapper的输入数据的Value,这里是每行文字 * KeyOut Mapper的输出数据的Key,这里是每行文字中的“年份” * ValueOut Mapper的输出数据的Value,这里是每行文字中的“气温” */ static class TempMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 打印样本: Before Mapper: 0, 2000010115 System.out.print("Before Mapper: " + key + ", " + value); String line = value.toString(); String year = line.substring(0, 4); int temperature = Integer.parseInt(line.substring(8)); context.write(new Text(year), new IntWritable(temperature)); // 打印样本: After Mapper:2000, 15 System.out.println( "======" + "After Mapper:" + new Text(year) + ", " + new IntWritable(temperature)); } } /** * 四个泛型类型分别代表: * KeyIn Reducer的输入数据的Key,这里是每行文字中的“年份” * ValueIn Reducer的输入数据的Value,这里是每行文字中的“气温” * KeyOut Reducer的输出数据的Key,这里是不重复的“年份” * ValueOut Reducer的输出数据的Value,这里是这一年中的“最高气温” static class TempReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxValue = Integer.MIN_VALUE; StringBuffer sb = new StringBuffer(); //取values的最大值 for (IntWritable value : values) { maxValue = Math.max(maxValue, value.get()); sb.append(value).append(", "); } // 打印样本: Before Reduce: 2000, 15, 23, 99, 12, 22, System.out.print("Before Reduce: " + key + ", " + sb.toString()); context.write(key, new IntWritable(maxValue)); // 打印样本: After Reduce: 2000, 99 System.out.println( "======" + "After Reduce: " + key + ", " + maxValue); } } public static void main(String[] args) throws Exception { //输入路径 String dst = "hdfs://localhost:9000/intput.txt"; //输出路径,必须是不存在的,空文件加也不行。 String dstOut = "hdfs://localhost:9000/output"; Configuration hadoopConfig = new Configuration(); hadoopConfig.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName() ); hadoopConfig.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName() ); Job job = new Job(hadoopConfig); //如果需要打成jar运行,需要下面这句 //job.setJarByClass(NewMaxTemperature.class); //job执行作业时输入和输出文件的路径 FileInputFormat.addInputPath(job, new Path(dst)); FileOutputFormat.setOutputPath(job, new Path(dstOut)); //指定自定义的Mapper和Reducer作为两个阶段的任务处理类 job.setMapperClass(TempMapper.class); job.setReducerClass(TempReducer.class); //设置最后输出结果的Key和Value的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //执行job,直到完成 job.waitForCompletion(true); System.out.println("Finished"); }
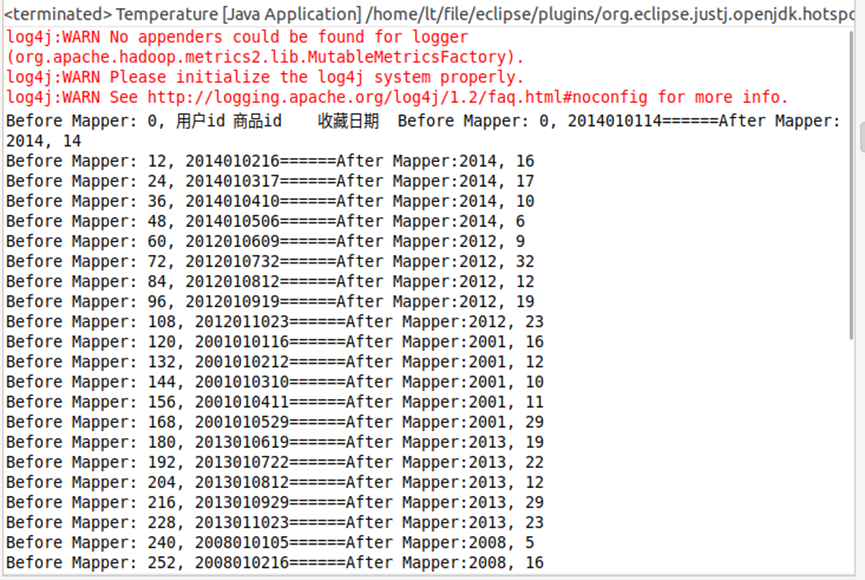
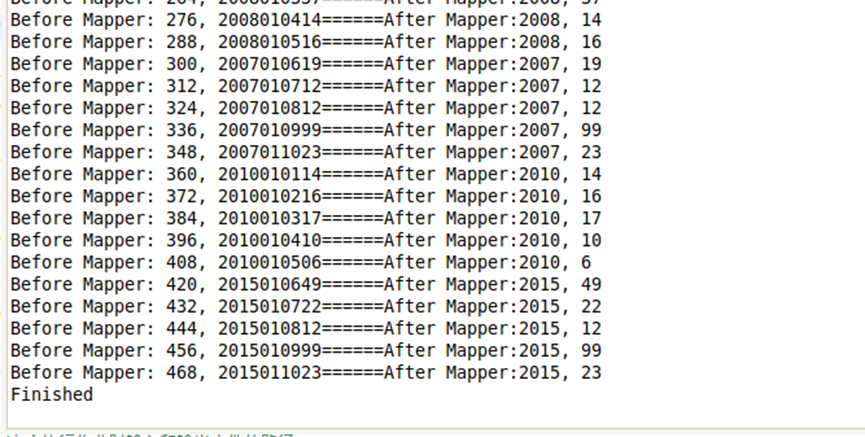
运行

3.2 词频统计
import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub //super.map(key, value, context); //String[] words = StringUtils.split(value.toString()); String[] words = StringUtils.split(value.toString(), " "); for(String word:words) { context.write(new Text(word), new LongWritable(1)); } } }
import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text arg0, Iterable<LongWritable> arg1, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub //super.reduce(arg0, arg1, arg2); int sum=0; for(LongWritable num:arg1) { sum += num.get(); } context.write(arg0,new LongWritable(sum)); } }
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountRunner { public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = new Job(conf); job.setJarByClass(WordCountRunner.class); job.setJobName("wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[1])); FileOutputFormat.setOutputPath(job, new Path(args[2])); job.waitForCompletion(true); } }
上传单词文件

修改路径
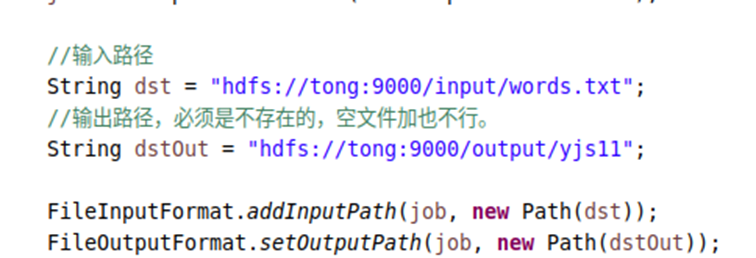
运行后

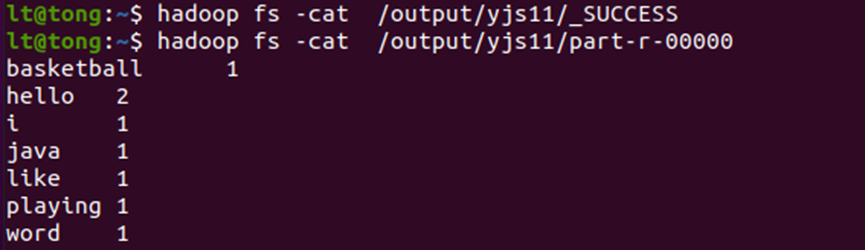
Cat一下结果