FW : http://xulingbo.net/?p=434 版权归许令波所有。此处只是一个转载。
后面介绍的不同方式都有测试数据,这些测试数据都是在同一的测试环境下得出的测试结果:
测试机器的配置如下:
64位5核CPU, E5620 @ 2.40GHz,内存8G
CDN端缓存
由 于计数器的价值并不在,具体的值是多少,尤其是对一些大访问量的商品来说个位或者十位的数据并没有什么意义,所以对这些热门商品的计数器访问可以采用定时 更新的办法,可以将计数器的值直接缓存在CDN上或者后端Nginx的缓存中,定时再到数据库服务器上获取最新的计数器的值,这样能够大量减少对后端服务器的访问请求,而且计数器的数据量很小对缓存服务器的空间需求也不大。
改进的结构图如下:
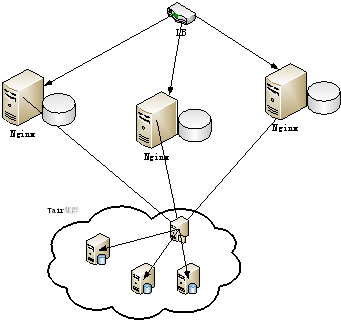
直接在Nginx中利用Cache策略缓存住热门计数器的值,利用http协议的cache+max age来失效缓存的方式更新计数器的值。
优点:
实现方式简单,改动小,能够挡住热门商品的计数器访问请求,采用这种方式对查询请求来说,能达到类似于静态服务器的性能,如Nginx能达到2w的QPS
缺点:没有解决同一商品的计数器合并请求的问题,数据量会增大一倍对更新请求没有办法缓存,只能减少查询请求的压力
基于Java的存储方式
由于目前采用Nginx模块的方法开发,每次修改要重新编译Nginx服务器,所以想采用基于Java的方式,使得维护要容易一些。
选用Ehcache作为数据存储服务器,Ehcache也是基于内存存储,支持定时持久化功能,非常适合存储像计数器这种小数据类型。处理Http请求使用Tomcat容器,结构图如下:
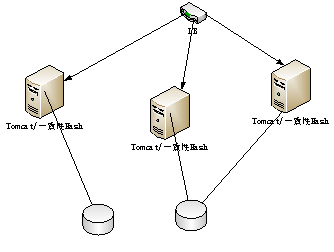
处理逻辑采用一个servlet实现,并且在这个servlet中通过一致性Hash从Ehcache中获取计数器值。
在实际的部署结构中,可以将Tomcat和Ehcache部署在同一台机器上。
基于这种模式的测试结果如下:
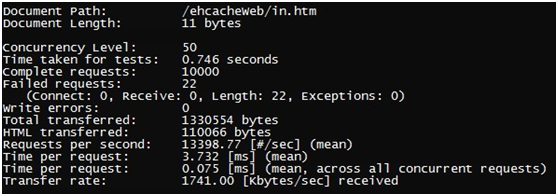
Qps能达到1.3w左右,性能瓶颈是在Tomcat处理Http连接的请求上,Tomcat较Apache和Nginx处理请求性能较差。
优点:业务逻辑和存储服务器都采用Java开发,利于维护,也能能解决数据合并的问题。
缺点:Java服务器在处理Http短连接请求时要比Nginx等服务器性能稍差,与目前的2W的qps有些差距
基于Nginx+Redis
上次参加Velocity大会了解到新浪、百度这些公司,内部的计数器都是采用Redis作为存储服务器,性能非常好,官方给出的测试结果是,回来后测试了Redis的性能,性能果然不错,单台redis机器能支持将近6w的QPS
测试结果如下:
写:

读:

读写性能基本能达到6w(8G,5核的虚拟机)左右,5核cpu只会把一个cpu用满。如下图所示:
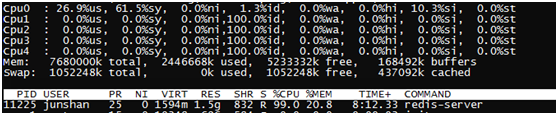
全内存操作情况下要好于tair的5w(24G,8核的实体机)。
Redis目前支持多种客户端连接,我分别测试了基于Apache的PHP客户端,和直接基于Nginx的c客户端
基于Nginx的C客户端测试
和叔度了解到一个ab压不倒Nginx的性能瓶颈,所以采用两个ab压Nginx,结果如下:
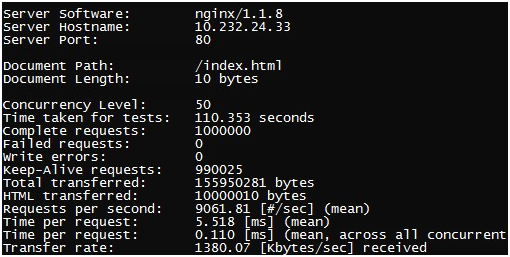
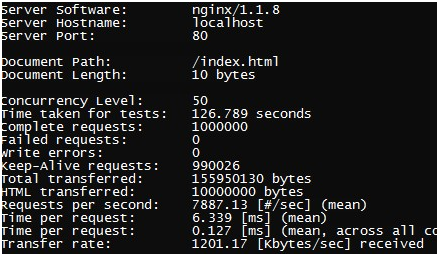
两个加起来能达到1.7w左右的QPS,如果采用线上的8核CPU的话,达到2W以上的QPS肯定是没有问题的。
基于Apache的PHP客户端测试结果如下:
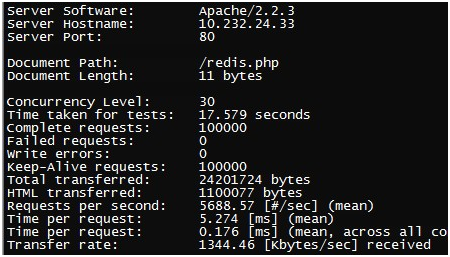
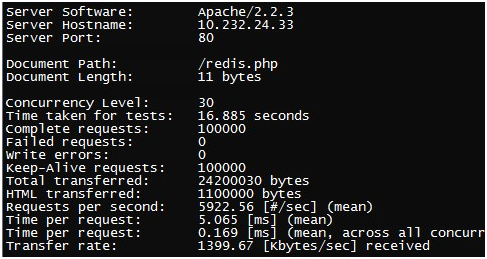
两个ab压测apache能达到1.1w左右的QPS,要比基于Nginx的c客户端差。
上面这两种情况,他们的结构图都是如下
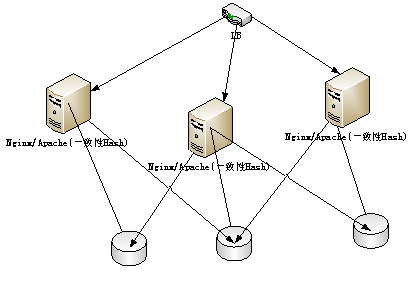
Nginx可以直接采用一致性Hash的方式将相同的商品ID或者用户ID映射到同一台Redis服务器上,在Nginx上开发一个C的模块来简单的出来对计数器的操作。
优点:性能非常好,前端处理请求采用Nginx服务器,处理短连接性能非常好,后端采用Redis存储,性能也要好于tair,而且支持将数据分组,可以做到基于商品ID和用户ID数据合并。
缺点:同样要开发基于一个c模块的Nginx模块,以后维护也要麻烦一点。
Tair ldb和redis的对别测试
- 做了下Tair的ldb版本和Redis的vm形式的持久化对比测试,感谢宗岱给配置了tair的ldb版本的配置了参数
- 测试机器是相同配置的64位5核CPU, E5620 @ 2.40GHz,内存8G的
虚拟机 - 测试数据:造了1亿(0~100000000整数)条不同key的数据
- 测试方式:分别测试tair和redis的两个方法:incr和get的写读接口
- 数据读写范围是:在0~1亿条数据中,随机读写。
- 测试结果如下:
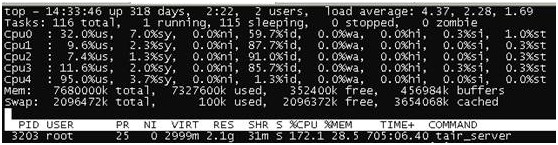
- CPU资源对比
Tair:
Redis:
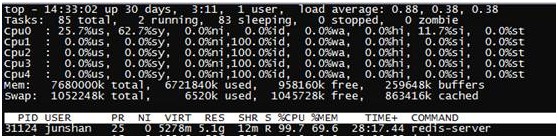
- Tair的5个核基本都使用了,load的得到4左右
- Redis只使用了一个核,其他4个核基本没有,而且load维持在1以下,所以在多核情况下可以部署多个Redis实例,性能会更好
- 写情况的TPS对比:
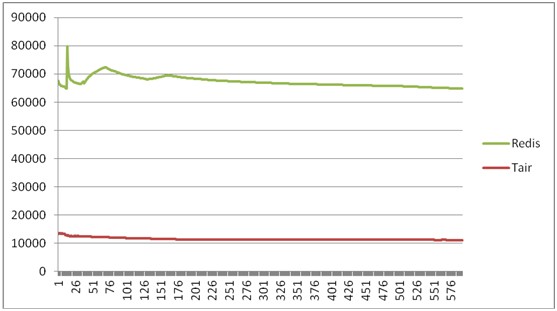
- Tair的写平均TPS在1.2w左右
- Redis的写平均TPS在5.4w左右
- 读情况对比:

- Tair的读平均TPS在2.5w左右
- Redis的写平均TPS在5.5w左右