Aggregation简单来说,就是提供数据统计、分析、分类的方法,这与mapreduce有异曲同工之处,只不过mongodb做了更多的封装与优化,让数据操作更加便捷和易用。Aggregation操作,接收指定collection的数据集,通过计算后返回result数据;一个aggregation操作,从input源数据到output结果数据,中间会依次经过多个stages,整体而言就是一个pipeline;目前有10种stages,我们稍后介绍;它还提供了丰富的Expression(表达式)来辅助计算。
聚合管道是一个基于数据处理管道概念的框架。通过使用一个多阶段的管道,将一组文档转换为最终的聚合结果。
管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
语法:
pipeline Array
语法示例:
db.school.aggregate( [ {$match:{time:{$gt:1513612800}}}, {$group:{_id:{insituteName:"$institute",class:"$name"},count:{$sum:1}}}, {$sort:{count:-1}}, {$limit:10}] )
这里我们介绍一下聚合框架中常用的几个操作:
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作,放在group前相当于where使用,放在group后面相当于having使用
$sort: 排序,1升、-1降。sort一般放在group后,也就是说得到结果后再排序,如果先排序再分组没什么意义;
$limit:用来限制MongoDB聚合管道返回的文档数。相当于limit m,不能设置偏移量
$skip:聚合管道中跳过指定数量的文档,并返回余下的文档。跳过第几个文档
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$group:将集合中的文档分组,可用于统计结果。其中_id固定写法:
{ _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ...
按什么字段分组,注意所有字段名前面都要加$,否则mongodb就为以为不加$的是普通常量,其中accumulator又包括以下几个操作符:
$sum,$avg,$first,$last,$max,$min,$push,$addToSet
如果按照多个字段分组,则字段必须都在_id对象中,可以取别名,例如上面示例,输出结果为:
{ "_id" : { "insituteName" : "数学系",class: "一班"}, "count" : 200 }
{ "_id" : { "insituteName" : "英语系",class: "二班" }, "count" : 201 }
如果按照一个字段分组,则可以写为{$group:{_id:"$institute",count:{$sum:1}}},此时,查询结果为:
{ "_id" : "数学系", "count" : 1000 }
{ "_id" : "英语系", "count" : 800 }
若没有分组字段,则{$group:{_id:null,count:{$sum:1}}}。即:如果group by null就是 count(*)的效果
$geoNear:取某一点的最近或最远,在LBS地理位置中有用
$out:把结果写进新的集合中。注意1,不能写进一个分片集合中。注意2,不能写进
count:{$sum:1},1表示统计查询结果数量,如果想统计time字段和则使用 count:{$sum:"$time"}。
聚合函数有:min,max,sum,avg
下表展示了一些聚合的表达式:
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
使用MongoTemplate操作Aggregation
Aggregation agg = Aggregation.newAggregation( Aggregation.match(criteria),//条件 Aggregation.group("a","b","c","d","e").count().as("f"),//分组字段 Aggregation.sort(sort),//排序 Aggregation.skip(page.getFirstResult()),//过滤 Aggregation.limit(pageSize)//页数 ); AggregationResults<Test> outputType=mongoTemplate.aggregate(agg,"test",Test.class); List<Test> list=outputType.getMappedResults();
示例:
上面是mysql的,下面是mongoTemplate的代码:
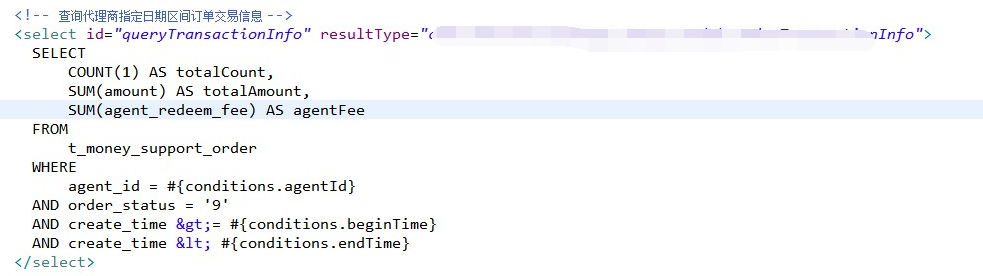
mongoTemplate的代码:
Aggregation aggregation = Aggregation.newAggregation( Aggregation.match(Criteria.where("agent_id").is(conditions.getAgentId()).and("order_status").is(9)), Aggregation.group("agentId", "orderStatus"). count().as("totalCount").sum("amount").as("totalAmount").sum("agent_redeem_fee").as("agentFee") ).withOptions(Aggregation.newAggregationOptions().allowDiskUse(true).build()); AggregationResults<BasicDBObject> outputTypeCount = moneySupportOrderDao.aggregate(aggregation, BasicDBObject.class);
参考:《学习MongoDB,在java中使用MongoTemplate聚合操作MongoDB》
附带官方文档:https://docs.spring.io/spring-data/mongodb/docs/current/reference/html/#mongo.aggregation
参考网站:
https://blog.csdn.net/ruoguan_jishou/article/details/79289369(聚合操作示例)
https://blog.csdn.net/qq_33556185/article/details/53099085(聚合操作分页)
http://huangyongxing310.iteye.com/blog/2342307(超多示例)
https://www.cnblogs.com/nixi8/p/4856746.html(高级查询:聚合操作之基础)
http://shift-alt-ctrl.iteye.com/blog/2259216( Aggregation超级详细介绍)