本文主要讨论这么几个问题:
(1)“缓存与数据库”需求缘起
(2)“淘汰缓存”还是“更新缓存”
(3)缓存和数据库的操作时序
(4)缓存和数据库架构简析
一、需求缘起
场景介绍
缓存是一种提高系统读性能的常见技术,对于读多写少的应用场景,我们经常使用缓存来进行优化。
例如对于用户的余额信息表account(uid, money),业务上的需求是:
(1)查询用户的余额,SELECT money FROM account WHERE uid=XXX,占99%的请求
(2)更改用户余额,UPDATE account SET money=XXX WHERE uid=XXX,占1%的请求
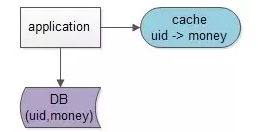
由于大部分的请求是查询,我们在缓存中建立uid到money的键值对,能够极大降低数据库的压力。
读操作流程
有了数据库和缓存两个地方存放数据之后(uid->money),每当需要读取相关数据时(money),操作流程一般是这样的:
(1)读取缓存中是否有相关数据,uid->money
(2)如果缓存中有相关数据money,则返回【这就是所谓的数据命中“hit”】
(3)如果缓存中没有相关数据money,则从数据库读取相关数据money【这就是所谓的数据未命中“miss”】,放入缓存中uid->money,再返回
缓存的命中率 = 命中缓存请求个数/总缓存访问请求个数 = hit/(hit+miss)
上面举例的余额场景,99%的读,1%的写,这个缓存的命中率是非常高的,会在95%以上。
那么问题来了
当数据money发生变化的时候:
(1)是更新缓存中的数据,还是淘汰缓存中的数据呢?
(2)是先操纵数据库中的数据再操纵缓存中的数据,还是先操纵缓存中的数据再操纵数据库中的数据呢?
(3)缓存与数据库的操作,在架构上是否有优化的空间呢?
这是本文关注的三个核心问题。
二、更新缓存 VS 淘汰缓存
什么是更新缓存:数据不但写入数据库,还会写入缓存
什么是淘汰缓存:数据只会写入数据库,不会写入缓存,只会把数据淘汰掉
更新缓存的优点:缓存不会增加一次miss,命中率高
淘汰缓存的优点:简单(我去,更新缓存我也觉得很简单呀,楼主你太敷衍了吧)
那到底是选择更新缓存还是淘汰缓存呢,主要取决于“更新缓存的复杂度”。
例如,上述场景,只是简单的把余额money设置成一个值,那么:
(1)淘汰缓存的操作为deleteCache(uid)
(2)更新缓存的操作为setCache(uid, money)
更新缓存的代价很小,此时我们应该更倾向于更新缓存,以保证更高的缓存命中率
如果余额是通过很复杂的数据计算得出来的,例如业务上除了账户表account,还有商品表product,折扣表discount
account(uid, money)
product(pid, type, price, pinfo)
discount(type, zhekou)
业务场景是用户买了一个商品product,这个商品的价格是price,这个商品从属于type类商品,type类商品在做促销活动要打折扣zhekou,购买了商品过后,这个余额的计算就复杂了,需要:
(1)先把商品的品类,价格取出来:SELECT type, price FROM product WHERE pid=XXX
(2)再把这个品类的折扣取出来:SELECT zhekou FROM discount WHERE type=XXX
(3)再把原有余额从缓存中查询出来money = getCache(uid)
(4)再把新的余额写入到缓存中去setCache(uid, money-price*zhekou)
更新缓存的代价很大,此时我们应该更倾向于淘汰缓存。
however,淘汰缓存操作简单,并且带来的副作用只是增加了一次cache miss,建议作为通用的处理方式。
三、先操作数据库 vs 先操作缓存
OK,当写操作发生时,假设淘汰缓存作为对缓存通用的处理方式,又面临两种抉择:
(1)先写数据库,再淘汰缓存
(2)先淘汰缓存,再写数据库
究竟采用哪种时序呢?
由于写数据库与淘汰缓存不能保证原子性,谁先谁后同样要遵循上述原则。
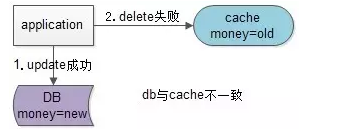
假设先写数据库,再淘汰缓存:第一步写数据库操作成功,第二步淘汰缓存失败,则会出现DB中是新数据,Cache中是旧数据,数据不一致。

假设先淘汰缓存,再写数据库:第一步淘汰缓存成功,第二步写数据库失败,则只会引发一次Cache miss。
结论:数据和缓存的操作时序,结论是清楚的:先淘汰缓存,再写数据库。
转自:58沈剑 架构师之路