1.哈希表
2.哈希函数
3.哈希冲突
哈希表是一种按key-value存储的数据结构,也称散列表。
之前的数组、树和图等等查找一个值时都要与结构中的值相比较,查找的效率取决于比较的次数。
而哈希表因为key与value对应,则可以在较少的比较次数中找到元素。
哈希表是对于给定的一个key,建立一个函数H(key),y =H(key)即为元素key在数组内的储存位置。
1.直接定址法
直接建立一个与key相关的线性函数形如:H(key)=k*key+b
2.数字分析法
就是找找规律,尽量让大多数H(key)落在不同区间,例如对于身份证号码,前面的数字重复率太高,可以考虑用出生年月日计算当key。
3.平方取中法
取关键字平方后的中间几位当做哈希地址。
4.折叠法
将关键字分成位数相同的几个部分(最后一部分位数可以不同),然后取这几部分的叠加和作为哈希地址。
关键字位数很多,并且数字分步均匀时可以考虑采用折叠法。
5.除留余数法
形如H(key) = key %m.
6.随机数法(还莫得理解)
当key过多时,就容易发生多个key对于H出现同样的结果,就是它们会占用数组同一个位置,这就是哈希冲突。
冲突是不可避免的,我们要做的就是要尽可能的使冲突达到最小。
常用的处理冲突的方法有:
1.开放定址法
这个时候H* = (H(key)+di)%m , di = 1、2、3........m-1
这里对于di 的值又有三种取法:
1)线性探测再散列:
顾名思义,di取值为1,2,3.....m-1,也就是当前位置已经有元素时,会像下一个位置走。
2)二次探测再散列
这里di 取值为 1^2 、 -1^2 、2^2、-2^2.......- (m/2)^2 , m为散列表长度,若是算出key+di为负数,则加上m再取余,也就是移到了后面,即-1就移到最后一位。
3)伪随机探测再散列(这个还没搞懂)
2.链地址法
链地址法,看图理解。
经过哈希函数后,对于处于同一位置的元素,用链表将它们储存。
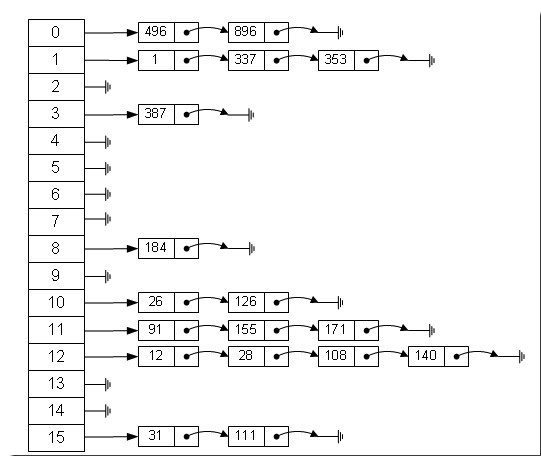
(图源自网络)
3.再哈希法
Hi = RHi(key), i = 1,2,3.....k
RHi 是不同的函数,在用一个哈希函数产生冲突时就调用另一个,直到不产生冲突为止。
4.建立公共溢出表
也就是建立另一个区间,产生冲突的都放进另一个区间。感觉不太好用,冲突多了比较次数又多了。
下面用除余法和链地址法(尾接法)写的代码如下:
#include<iostream> using namespace std; #define hashsize 11 struct Node{//链表节点 int data; Node *next; int flag; Node(){ flag=0; next=NULL; } Node (int num){ flag=1; data=num; next=NULL; } }; class Hash{ private: Node *hashtable; int len;//记录现在数据个数 public: Hash(){ len=0; hashtable = new Node[hashsize]; } ~Hash(){ } //获得key值 ,哈希函数 int getKey(int num){ return num%hashsize; } //往表中插入元素 ,链接法 void insertData(int num){ int key = getKey(num);//获得key值 if(hashtable[key].flag==0){//此时当前key位置无数据 hashtable[key].data=num; hashtable[key].flag=1; } else{//尾插入法 Node *tmp = &hashtable[key];//指针要获得地址才能赋值 while(tmp->next!=NULL) tmp=tmp->next; tmp->next = new Node(num); } len++; } //查找hash表中是否有这个元素,有则返回查找次数,无则返回-1 int find(int num){ int sum=1; int key = getKey(num);//获取该数键值 if(hashtable[key].flag==0){ insertData(num); return -1; } else{ Node *tmp = &hashtable[key]; while(tmp->data!=num){ sum++; if(tmp->next==NULL){ insertData(num); return -1; } tmp=tmp->next; } //能退出上面的while说明找到相等的了,return sum return sum; } } }; int main(){ int n; cin>>n; int num[100]; for(int i=0;i<n;i++) cin>>num[i]; Hash *hash = new Hash(); for(int i=0;i<n;i++) hash->insertData(num[i]); cin>>n; for(int i=0;i<n;i++){ cin>>num[i]; if(hash->find(num[i])!=-1) cout<<hash->getKey(num[i])<<" "<<hash->find(num[i])<<endl; else cout<<"error"<<endl; }
这里待测样例如下:


6 11 23 39 48 75 62 6 39 52 52 63 63 52
样例输出:
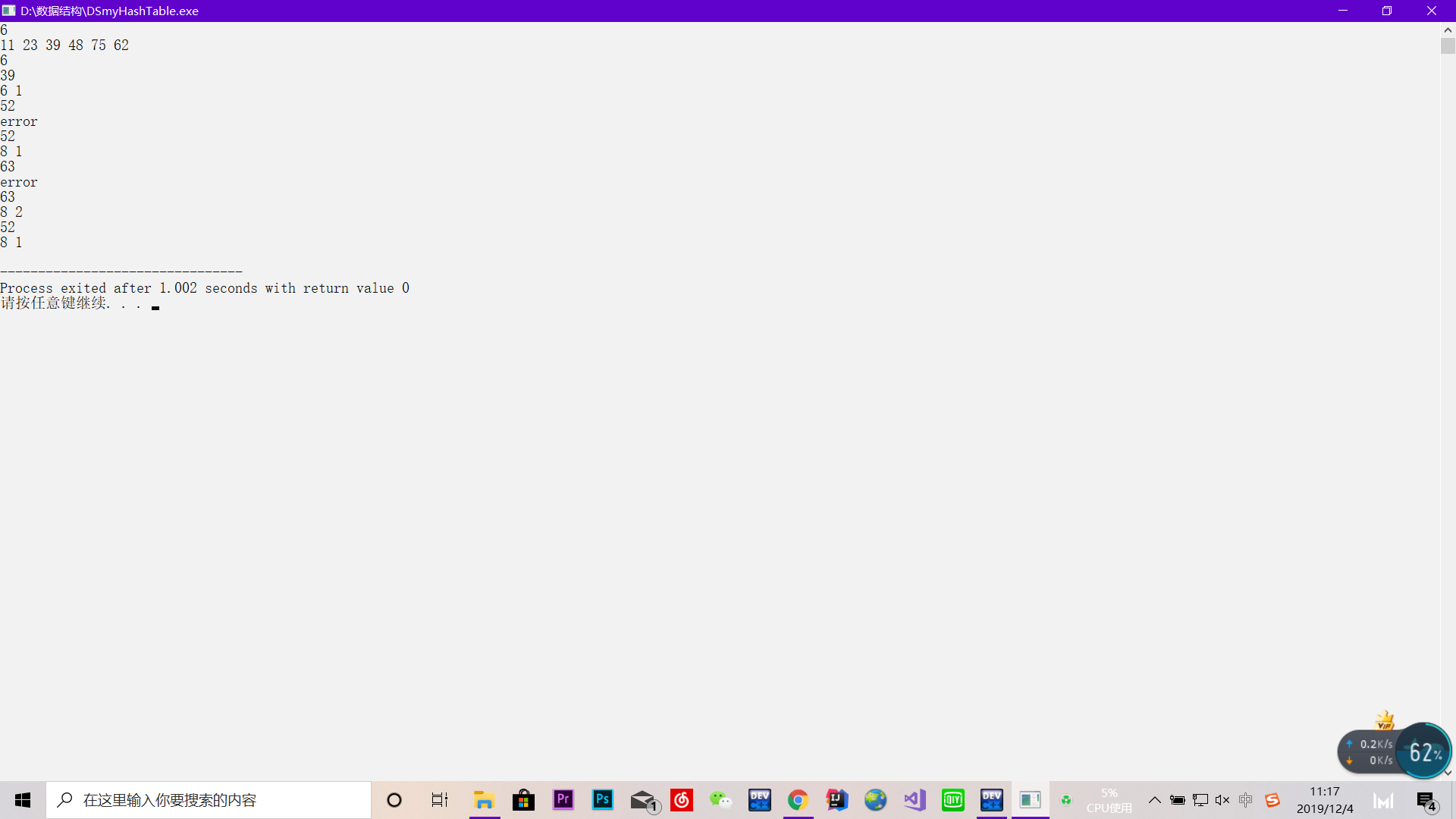
接下来是用除余法与二次散列再分配写的代码:
//该程序使用二次散列再查找的方式处理冲突构建哈希表 //哈希函数选择除于11的方法 #include<iostream> using namespace std; #define modnum 11 struct HashData{ int data; int flag; HashData(){ flag=0;//当查找次数 } }; class Hash{ private: HashData *hashtable;//哈希表 int len; int *value; public: Hash(int n){ hashtable = new HashData[n]; len=n; int flag = -1; int pos=0; value = new int [len]; for(int i=1;i<len/2;i++){ value[pos++]=i*i; value[pos++]=flag*i*i; } } ~Hash(){ } int getKey(int num){ return num%modnum; } void insert(int num){ int key = getKey(num); if(hashtable[key].flag==0){ hashtable[key].data = num; hashtable[key].flag = 1; } else{ int flag1=1; for(int i=0;i<len;i++){ //二次散列 ,找到空的位置 flag1++; //如果此时key+value[i] 是负数就去到H()+len的位置 if(hashtable[(key+value[i]+len)%len].flag==0){ hashtable[(key+value[i]+len)%len].data = num; hashtable[(key+value[i]+len)%len].flag = flag1; return ; } } } } int find(int num){ int key = getKey(num);//获得键值 if(hashtable[key].data==num){ return key+1; } else{ for(int i=0;i<len;i++){ if(hashtable[(key+value[i]+len)%len].data==num){ return (key+value[i]+len)%len+1; } } return -1; } } int getSum(int num){ int key = find(num);//获得键值 if(key != -1) return hashtable[key-1].flag; else{ int sum=1; for(int i=0;i<len;i++){ sum++; //说明找不到这个元素 if(hashtable[(key+value[i]+len)%len].flag==0) break; } return sum; } } void show(){ for(int i=0;i<len-1;i++){ if(hashtable[i].flag!=0){ cout<<hashtable[i].data<<" "; } else cout<<"NULL "; } if(hashtable[len-1].flag!=0){ cout<<hashtable[len-1].data<<endl; } else cout<<"NULL"<<endl; for(int i=0;i<len;i++) cout<<hashtable[i].flag<<" "; cout<<endl; } void deleteData(int num){ int key = find(num); if(key!=-1){ if(hashtable[key-1].flag!=0){ hashtable[key-1].flag=0; } } } }; int main(){ int n,m; cin>>m>>n; Hash *hash = new Hash(m); int a[100]; for(int i=0;i<n;i++){ cin>>a[i]; hash->insert(a[i]); } hash->show(); //查找 cin>>n; for(int i=0;i<n;i++){ cin>>a[i]; if(hash->find(a[i])!=-1){ cout<<1<<" "<<hash->getSum(a[i])<<" "<<hash->find(a[i])<<endl; } else cout<<0<<" "<<hash->getSum(a[i])<<endl; } //删除 cin>>n; for(int i=0;i<n;i++){ cin>>a[i]; hash->deleteData(a[i]); hash->show(); } }
样例输入(不包括新加的删除样例):
12 10 22 19 21 8 9 30 33 4 41 13 4 22 15 30 41
样例输出:
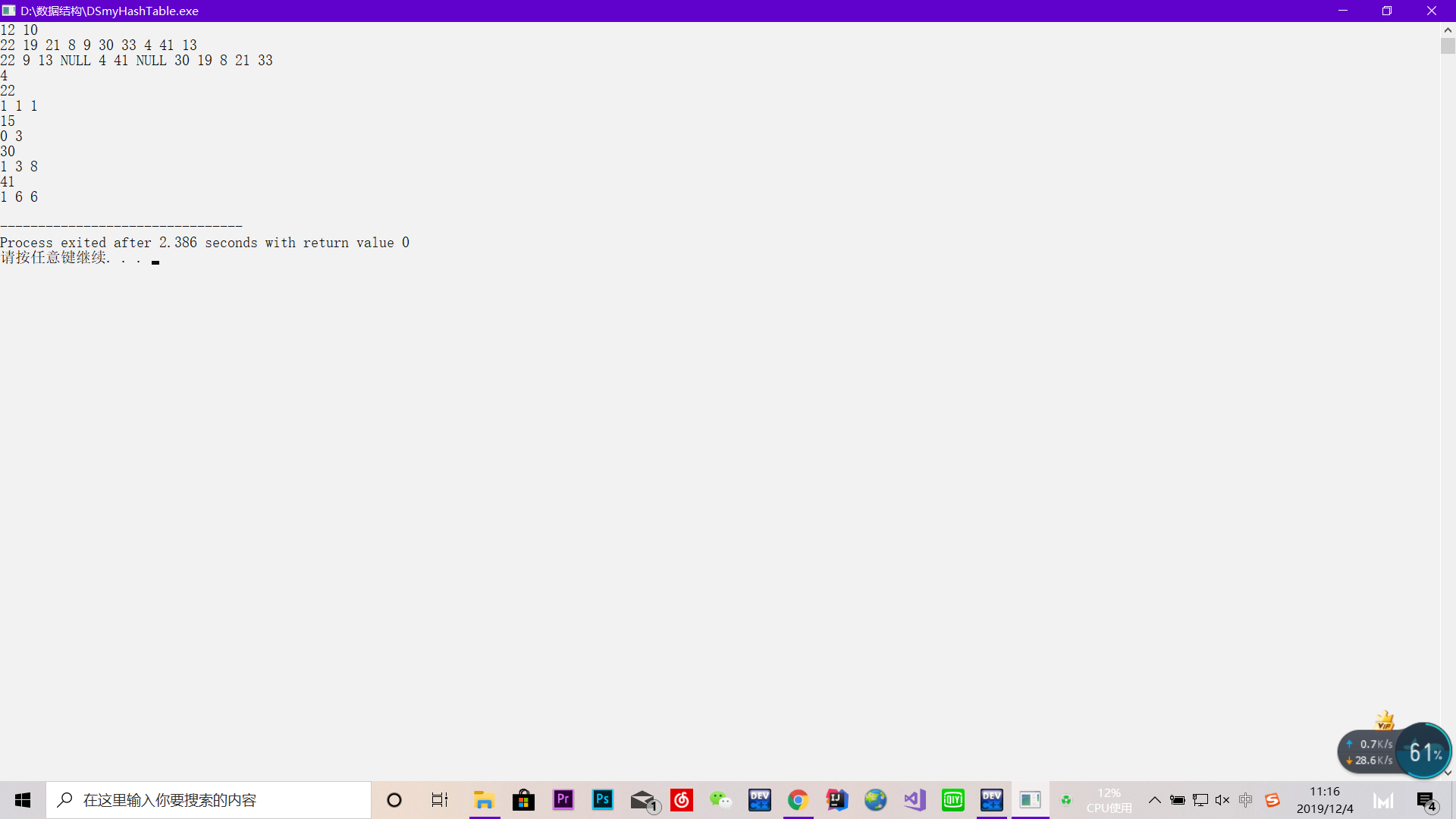
哈希的就先到这里,那些高端操作拜拜了您下次再看。