1.前言
总是聊并发的话题,聊到大家都免疫了,所以这次串讲下个话题——数据库(欢迎纠正补充)
看完问自己一个问题来自我检测:NoSQL我到底该怎么选?
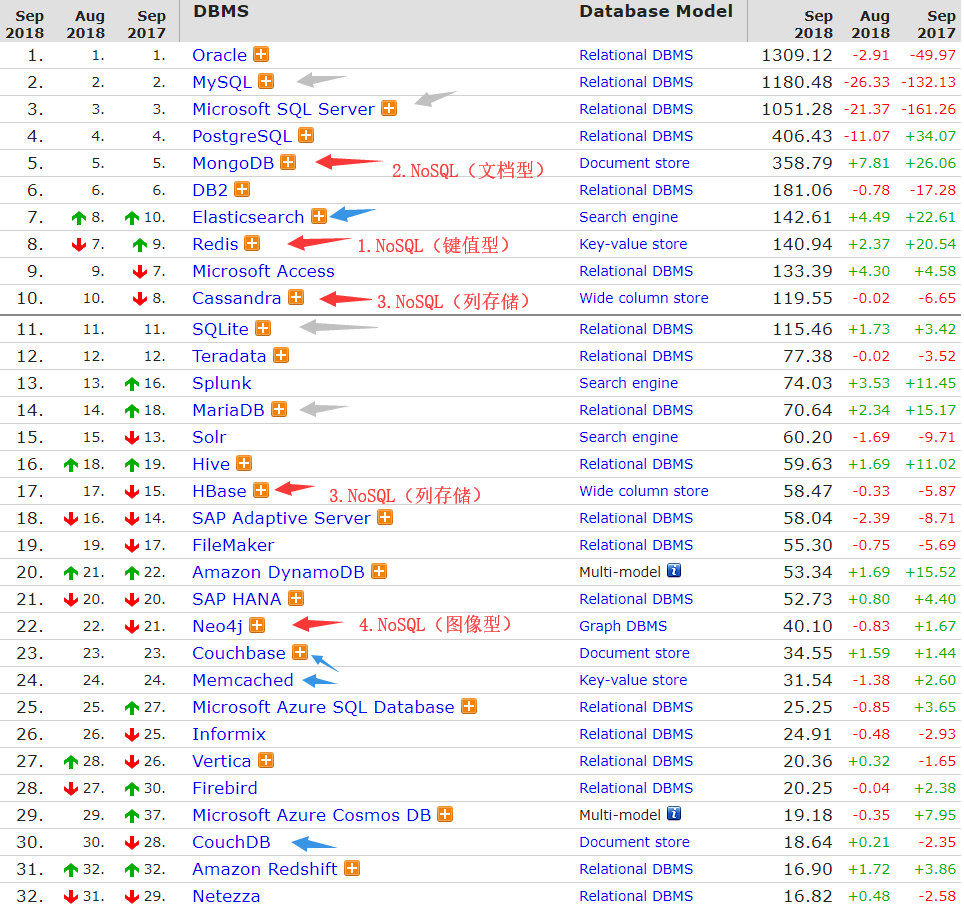
数据库排行:https://db-engines.com/en/ranking
1.1.分类
主要有这么三大类:(再老的数据库就不说了)
1.传统数据库(SQL):
- 关系数据库:SQLite、MySQL、SQLServer、PostgreSQL、Oracle...
2.高并发产物(NoSQL):
- 键值数据库:Redis、MemCached...
- PS:现在
LevelDB和RocksDB也是比较高效的解决方案 - PS:360开发的
pika(redis的补充)可以解决Redis容量过大的问题
- PS:现在
- 文档数据库:MongoDB、ArangoDB、CouchBase、CouchDB、RavenDB...
- PS:Python有一款基于json存储的轻量级数据库:
tinydb
- PS:Python有一款基于json存储的轻量级数据库:
- 列式数据库:Cassandra、HBase、BigTable...
- PS:小米的Pegasus计划取代HBase
- 搜索引擎系:Elasticsearch、Solr、Sphinx...
- PS:这几年用Rust编写的轻量级搜索引擎
sonic很火
- PS:这几年用Rust编写的轻量级搜索引擎
- 图形数据库:Neo4J、Flockdb、ArangoDB、OrientDB、Infinite Graph、InfoGrid...
- PS:基于Redis有一款图形数据库用的也挺多:
RedisGraph - PS:随着Go的兴起,这些图形数据库很火:Cayley、
Dgraph、Beam
- PS:基于Redis有一款图形数据库用的也挺多:
PS:项目中最常用的其实就是Redis、Elasticsearch、MongoDB
PS:
ArangoDB是一个原生的多模型数据库,具有文档,图形和键值的灵活数据库
3.新时代产物(TSDB):
- 时序数据库:InfluxDB、LogDevice、Graphite、、OpenTSDB...
来看个权威的图:(红色的是推荐NoSQL,灰色是传统SQL)
1.2.概念
先说下NoSQL不是不要使用传统SQL了,而是不仅仅是传统的SQL(not only sql)
1.关系型数据库优劣
先看看传统数据库的好处:
- 通过事务保持数据一致
- 可以Join等复杂查询
- 社区完善(遇到问题简单搜下就ok了)
当然了也有不足的地方:
- 数据量大了的时候修改表结构。eg:加个字段,如果再把这个字段设置成索引那是卡到爆,完全不敢在工作时间搞啊
- 列不固定就更蛋疼了,一般设计数据库不可能那么完善,都是后期越来越完善,就算自己预留了
保留字段也不人性化啊 - 大数据写入处理比较麻烦,eg:
- 数据量不大还好,批量写入即可。
- 可是本身数据量就挺大的,进行了
主从复制,读数据在Salver进行到没啥事,但是大量写数据库怼到Master上去就吃不消了,必须得加主数据库了。 - 加完又出问题了:虽然把主数据库一分为二,但是容易发生
数据不一致(同样数据在两个主数据库更新成不一样的值),这时候得结合分库分表,把表分散在不同的主数据库中。 - 完了吗?NoNoNo,想一想表之间的Join咋办?岂不是要跨数据库和跨服务器join了?简直就是拆东墙补西墙的节奏啊,所以各种中间件就孕育而生了【SQLServer这方面扩展的挺不错的,列存储也自带,也跨平台了(建议在Docker中运行)(点我查看几年前写的一篇文章)】
- 欢迎补充~(说句良心话,中小型公司
SQLServer绝对是最佳选择,能省去很多时间)
2.NoSQL
现在说说NoSQL了:(其实你可以理解为:NoSQL就是对原来SQL的扩展补充)
- 分表分库的时候一般把关联的表放在同一台服务器上,这样便于join操作。而NoSQL不支持join,反而不用这么局限了,数据更容易分散存储
- 大量数据处理这块,读方面传统SQL并没有太多劣势,NoSQL主要是进行缓存处理,批量写数据方面测试往往远高于传统SQL,而且NoSQL在扩展方面方便太多了
- 多场景类型的NoSQL(键值,文档、列、图形)
如果还是不清楚到底怎么选择NoSQL,那就再详细说说每个类型的特点:
- 键值数据库:这个大家很熟悉,主要就是
键值存储,代表=>Redis(支持持久化和数据恢复,后面我们会详谈) - 文档数据库:代表=>MongoDB(优酷的在线评论就是用基于MongoDB的)
- 一般都不具备事务(
MongoDB 4.0开始支持ACID事务了) - 不支持Join(Value是一个可变的
类JSON格式,表结构修改比较方便)
- 一般都不具备事务(
- 列式数据库:代表:Cassandra、
HBase- 对大量行少量列进行修改更新(新增一字段,批量做个啥操作的不要太方便啊~针对列为单位读写)
- 扩展性高,数据增加也不会降低对应的处理速度(尤其是写)
- 搜索引擎系:代表:Elasticsearch,太经典了不用说了(传统模糊搜索只能like太low,所以有了这个)
- 图形数据库:代表:Neo4J、Flockdb、ArangoDB(数据模型是图结构的,主要用于 关系比较复杂 的设计,比如绘制一个QQ群关系的可视化图、或者绘制一个微博粉丝关系图等)
回头还是要把并发剩余几个专题深入的,认真看的同志会发现不管什么语言底层实现都是差不多的。
比如说进程,其底层就是用到了我们第一讲说的OS.fork。再说进(线)程通信,讲的PIPE、FIFO、Lock、Semaphore等很少用吧?但是Queue底层就是这些实现的,不清楚的话怎么读源码?
还记得当时引入Queue篇提到Java里的CountDownLatch吗?要是不了解Condition怎么自己快速模拟一个Python里面没有的功能呢?
知其然不知其所以然是万万不可取的。等后面讲MQ的时候又得用到Queue的知识了,可谓一环套一环~
既然不是公司的萌妹子,所以呢~技术的提升还是得靠自己了^_^,先到这吧,最后贴个常用解决方案:
Python、NetCore常用解决方案(持续更新)
https://github.com/LessChina
2.概念
上篇提到了ACID这次准备说说,然后再说说CAP和数据一致性
2.1.ACID事务
以小明和小张转账的例子继续说说:
- A:原子性(Atomic)
- 小明转账1000给小张:小明-=1000 => 小张+=1000,这个 (事务)是一个不可分割的整体,如果小明-1000后出现问题,那么1000得退给小明
- C:一致性(Consistent)
- 小明转账1000给小张,必须保证小明+小张的总额不变(假设不受其他转账(事务)影响)
- I:隔离性(Isolated)
- 小明转账给小张的同时,小潘也转钱给了小张,需要保证他们相互不影响(主要是并发情况下的隔离)
- D:持久性(Durable)
- 小明转账给小张银行要有记录,即使以后扯皮也可以拉流水账【事务执行成功后进行的持久化(就算数据库之后挂了也能通过Log恢复)】
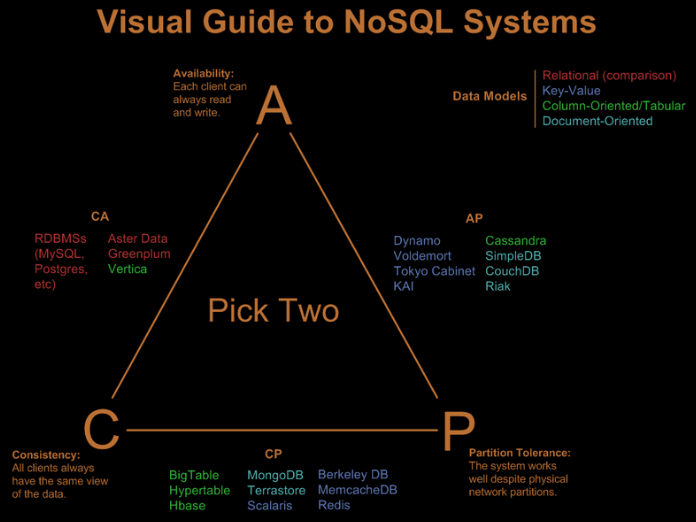
2.2.CAP概念
CAP是分布式系统需要考虑的三个指标,数据共享只能满足两个而不可兼得:
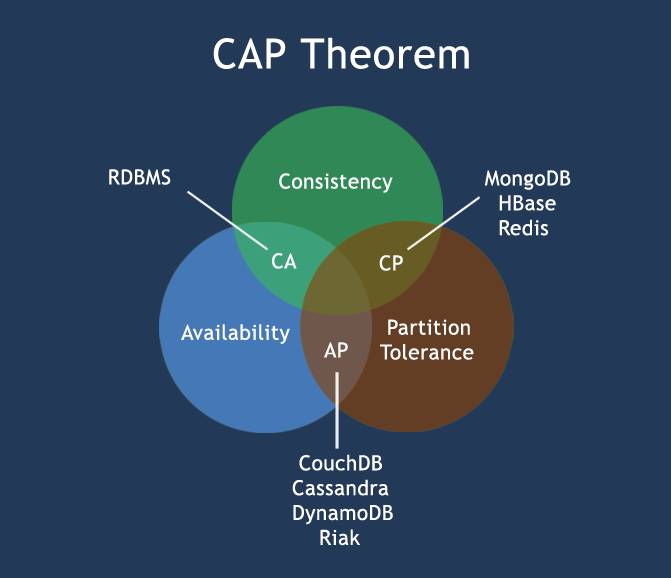
- C:一致性(Consistency)
- 所有节点访问同一份最新的数据副本(在分布式系统中的所有数据备份,在同一时刻是否同样的值)
- eg:分布式系统里更新后,某个用户都应该读取最新值
- A:可用性(Availability)
- 在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- eg:分布式系统里每个操作总能在一定时间内返回结果(超时不算【网购下单后一直等算啥?机房挂几个服务器也不影响】)
- P:分区容错性(Partition Toleranc)
- 以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
- eg:分布式系统里,存在网络延迟(分区)的情况下依旧可以接受满足一致性和可用性的请求
CA
代表:传统关系型数据库
如果想避免分区容错性问题的发生,一种做法是将所有的数据(与事务相关的)都放在一台机器上。虽然无法100%保证系统不会出错,但不会碰到由分区带来的负面效果(会严重的影响系统的扩展性)
作为一个分布式系统,放弃P,即相当于放弃了分布式,一旦并发性很高,单机服务根本不能承受压力。像很多银行服务,确确实实就是舍弃了P,只用高性能的单台小型机保证服务可用性。(所有NoSQL数据库都是假设P是存在的)
CP
代表:Zookeeper、Redis(分布式数据库、分布式锁)
相对于放弃“分区容错性“来说,其反面就是放弃可用性。一旦遇到分区容错故障,那么受到影响的服务需要等待数据一致(等待数据一致性期间系统无法对外提供服务)
AP
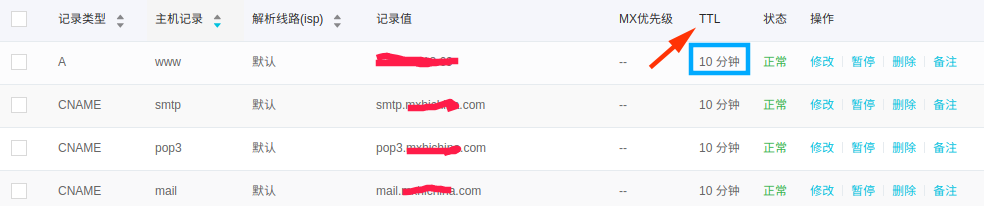
代表:DNS数据库(IP和域名相互映射的分布式数据库,联想修改IP后为什么TTL需要10分钟左右保证所有解析生效)
反DNS查询:https://www.cnblogs.com/dunitian/p/5074773.html
放弃强一致,保证最终一致性。所有的NoSQL数据库都是介于CP和AP之间,尽量往AP靠,(传统关系型数据库注重数据一致性,而对海量数据的分布式处理来说可用性和分区容错性优先级高于数据一致性)eg:
不同数据对一致性要求是不一样的,eg:
- 用户评论、弹幕这些对一致性是不敏感的,很长时间不一致性都不影响用户体验
- 像商品价格等等你敢来个看看?对一致性是很高要求的,容忍度铁定低于10s,就算使用了缓存在订单里面价格也是最新的(平时注意下JD商品下面的缓存说明,JD尚且如此,其他的就不用说了)
2.3.数据一致性
传统关系型数据库一般都是使用悲观锁的方式,但是例如秒杀这类的场景是hou不动,这时候往往就使用乐观锁了(CAS机制,之前讲并发和锁的时候提过),上面也稍微提到了不同业务需求对一致性有不同要求而CAP不能同时满足,这边说说主要就两种:
- 强一致性:无论更新在哪个副本上,之后对操作都要能够获取最新数据。多副本数据就需要
分布式事物来保证数据一致性了(这就是问什么项目里面经常提到的原因) - 最终一致性:在这种约束下保证用户最终能读取到最新数据。举几个例子:
- 因果一致性:A、B、C三个独立进程,A修改了数据并通知了B,这时候B得到的是最新数据。因为A没通知C,所以C不是最新数据
- 会话一致性:用户自己提交更新,他可以在会话结束前获取更新数据,会话结束后(其他用户)可能不是最新的数据(提交后JQ修改下本地值,不能保证数据最新)
- 读自写一致性:和上面差不多,只是不局限在会话中了。用户更新数据后他自己获取最新数据,其他用户可能不是最新数据(一定延迟)
- 单调读一致性:用户读取某个数值,后续操作不会读取到比这个数据还早的版本(新的程度>=读取的值)
- 单调写一致性(时间轴一致性):所有数据库的所有副本按照相同顺序执行所有更新操作(有点像
Redis的AOF)
2.4.一致性实现方法
Quorum系统NRW策略(常用)
Quorum是集合A,A是全集U的子集,A中任意取集合B、C,他们两者都存在交集。
NRW算法:
- N:表示数据所具有的副本数。
- R:表示完成读操作所需要读取的最小副本数(一次读操作所需参与的最小节点数)
- W:表示完成写操作所需要写入的最小副本数(一次写操作所需要参与的最小节点数)
- 只需要保证
R + W > N就可以保证强一致性(读取数据的节点和被同步写入的节点是有重叠的)比如:N=3,W=2,R=2(有一个节点是读+写)
扩展:
- 关系型数据库中,如果N=2,可以设置W=2,R=1(写耗性能一点),这时候系统需要两个节点上数据都完成更新才能确认结果并返回给用户
- 如果
R + W <= N,这时候读写不会在一个节点上同时出现,系统只能保证最终一致性。副本达到一致性的时间依赖于系统异步更新的方式,不一致性时间=从更新节点~所有节点都异步更新完毕的耗时 - R和W设置直接影响系统的性能、扩展和一致性:
- 如果W设置为1,那么一个副本更新完就返回给用户,然后通过异步机制更新剩余的N-W个节点
- 如果R设置为1,只要有一个副本被读取就可以完成读操作,R和W的值如果较小会影响一致性,较大会影响性能
- 当W=1,R=N==>系统对写要求高,但读操作会比较慢(N个节点里面有1个挂了,读就完成不了了)
- 当R=1,W=N==>系统对读操作有高要求,但写性能就低了(N个节点里面有1个挂了,写就完成不了了)
- 常用方法:一般设置
R = W = N/2 + 1,这样性价比高,eg:N=3,W=2,R=2(3个节点==>1写,1读,1读写)
参考文章:
http://book.51cto.com/art/201303/386868.htm
https://blog.csdn.net/jeffsmish/article/details/54171812
时间轴策略(常用)
- 主要是关系型数据库的日记==>记录事物操作,方便数据恢复
- 还有就是并行数据存储的时候,由于数据是分散存储在不同节点的,对于同一节点来说只要关心
数据更新+消息通信(数据同步):- 保证较晚发生的更新时间>较早发生的更新时间
- 消息接收时间 > 消息发送时刻的时间(要考虑服务器时间差的问题~时间同步服务器)
其他策略
其实还有很多策略来保证,这些概念的对象逆天不是很熟~比如:向量时钟策略
推荐几篇文章:
https://www.cnblogs.com/yanghuahui/p/3767365.html
http://blog.chinaunix.net/uid-27105712-id-5612512.html
https://blog.csdn.net/dellme99/article/details/16845991
https://blog.csdn.net/blakeFez/article/details/48321323