话说今天的一个小小的查询失误给了我比较深刻的教训,也让我对mongo有了更深刻的理解,下面我们来说说这个事情的原委:
我们经常使用阿里云子账号在DMS上查询线上数据库数据,今天也是平常的一次操作
集合:
XXXX_message
数据量约 600万
我执行了下面的mongo查询:
db.XXXX_message.find({"channel_id": "1000000009XXXX700XXXX"}).limit(20);
但是上述语句中的 "channel_id" 字段不存在,真实字段应该是channel(有索引),属于失误操作
在执行过程中,我发现查询时间很久,于是中断了查询又重试了两次,还是很久,最后中断了查询,我意识到我想查的字段可能错了,于是看了下集合索引,使用正确的字段检索得到结果
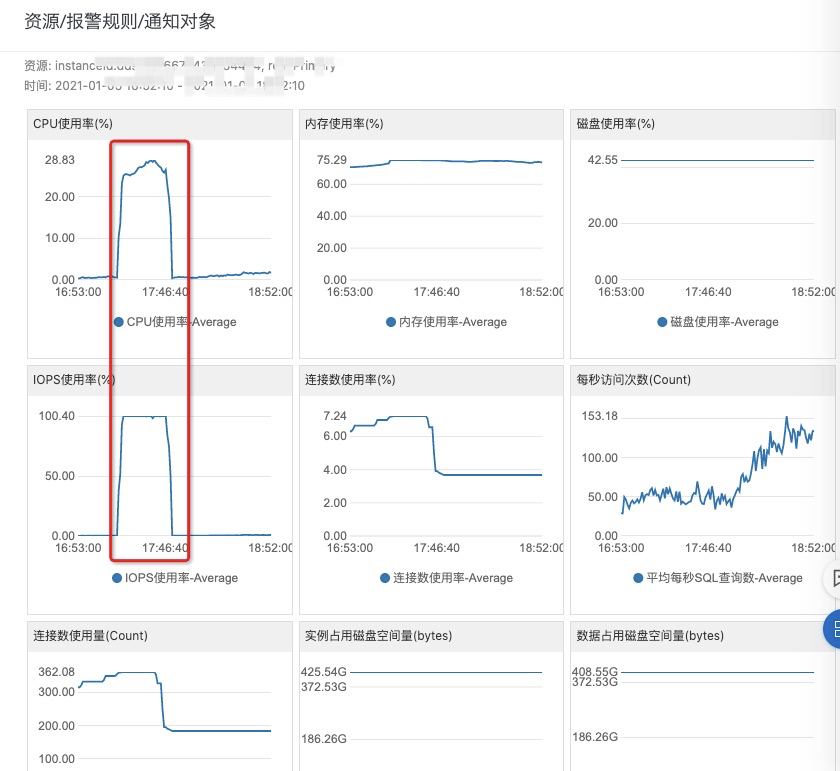
但就在这时候,一场事故也在悄然酝酿,2分钟后,阿里云监控中心打来告警电话,mongo数据库cpu、iops异常升高
起初并没有意识到是这个查询导致的,还以为是半小时前发布的版本可能有问题,于是立即回滚了版本并开始项目检查
查了许久,并没有查到可能造成本次数据库异常告警的原因,项目对该库的依赖的操作的地方非常少。
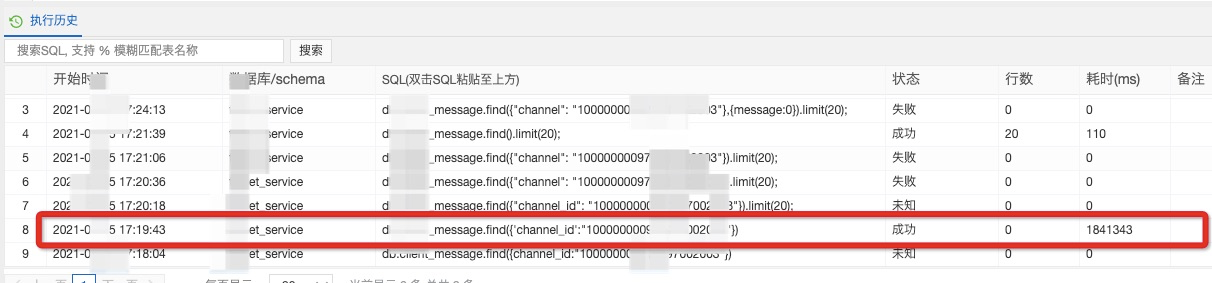
当我们苦苦想不到原因的时候,我们去查了下相关慢sql日志,果然一道耗时约1800000ms的慢sql日志引起了我们的注意
这时候我似乎意识到了点什么,我立马查阿里云控制台查询历史核对了我刚才查询的时间和数据库cpu、磁盘iops异常升高的时间节点
完全对上了,该起事故持续半小时左右,那条没有被成功中断的sql也执行了半小时左右
这让我很震惊,一次控制台查询居然导致整个数据库出现如此严重的问题,mongo底层没有考虑过不存在字段查询问题吗?
我慢慢平复心情,仔细回顾这件事情,我尝试着从mongo和mysql的底层去理解这个问题
mongo本身是集合型数据库,意味着每个集合文档都可以有自己独立的数据结构,和mysql等关系型数据库的很重要的区别就是它没有固定的表结构,它包容且随性
当在查询一个不存在的字段的时候,它仍然按照普通查询检索数据,这时候它会全表扫描,也就是说在上述失误语句中,mongo底层检索了整个集合的数据集,
遍历了该集合所有的磁盘块,这才导致磁盘iops升高且cpu升高。
这次经历让我觉得我有必要记录下相关心得,可能对于很多高级技术人员,这些东西都是很容易理解和规避的事情,但大多数人对此可能并没有深刻认识
这次事故让我对技术多了一层敬畏,这有助于我在今后的代码实践和操作中更加谨慎和多一层思考,希望大家以此为戒!
此文共勉!