将非局部计算作为获取长时记忆的通用模块,提高神经网络性能在深度神经网络中,获取长时记忆(long-range dependency)至关重要。对于序列数据(例如语音、语言),递归运算(recurrent operation)是长时记忆建模的主要解决方案。对于图像数据,长时记忆建模则依靠大型感受野,后者是多层卷积运算堆叠的结果。

卷积和递归运算处理的都是一个局部邻域,可以是空间局部邻域,也可以是时间局部邻域,因此只有不断重复这些运算,逐步在数据中传播信号,才能获取长时记忆。而不断重复局部计算有几个限制。首先,计算效率低下。其次,会产生一些优化问题,需要仔细解决。最后,这些问题使 multihop dependency 建模十分困难,multihop dependency 建模就是在很长的时间/空间位置之间来回传送信息。

非局部运算是计算机视觉中经典的非局部均值运算的一种泛化结果。直观地说,非局部运算将某一处位置的响应作为输入特征映射中所有位置的特征的加权和来进行计算。
我们将非局部运算作为一个高效、简单和通用的模块,用于获取深度神经网络的长时记忆。我们提出的非局部运算是计算机视觉中经典的非局部均值运算的一种泛化结果。直观地说,非局部运算将某一处位置的响应作为输入特征映射中所有位置的特征的加权和来进行计算。这些位置可以是空间位置,也可以是时间位置,还可以是时空位置,这意味着我们的计算适用于图像、序列和视频问题。
使用非局部运算有几大好处:(a)与递归和卷积运算的渐进的操作相比,非本局部运算直接通过计算任意两个位置之间的交互来获取长时记忆,可以不用管其间的距离;(b)正如他们在实验中所显示的那样,非局部运算效率很高,即使只有几层(比如实验中的5层)也能达到最好的效果;(c)最后,他们的非局部运算能够维持可变输入的大小,并且能很方便地与其他运算(比如实验中使用的卷积运算)相组合。

一个时空非局部组件。特征映射被表示为张量,⊗表示矩阵乘法,⊕表示单元和。每一行进行softmax。蓝框表示1×1×1的卷积。图中显示的是嵌入式高斯版本,具有512个通道的瓶颈。
“我们展示了非局部运算在视频分类应用中的有效性。在视频中,分隔开的像素在空间和时间上都会发生长时交互(long-range interaction)。我们的基本单元,也即单一的一个非局部模块,可以以前向传播的方式直接获取这些时空记忆。增加了几个非局部模块后,我们的“非局部神经网络”结构能比二维和三维卷积网络在视频分类中取得更准确的结果。另外,非局部神经网络在计算上也比三维卷积神经网络更加经济。我们在 Kinetics 和 Charades 数据集上做了全面的对比研究。我们的方法仅使用 RGB 数据,不使用任何高级处理(例如光流、多尺度测试),就取得了与这两个数据集上竞赛冠军方法相当乃至更好的结果。”
为了证明非局部运算的通用性,作者在 COCO 数据集上进行了物体检测、实例分割和人体姿态关键点检测的实验。他们将非局部运算模块与 Mask R-CNN 结合,新模型在计算成本稍有增加的情况下,在所有三个任务中都取得了最高的精度。由此表明非局部模块可以作为一种比较通用的基本组件,在设计深度神经网络时使用。
实验及结果
在这一节我们简单介绍论文中描述的实验及结果。

视频的基线模型是 ResNet-50 C2D。三维输出映射和滤波核的尺寸用T×H×W 表示(二维核则为 H×W),后面的数字代表通道数。输入是32×224×224。方括号里的是残差模块。

(c)展示了将非局部模块加入 C2D 基线后的结果,实验中用到了50层和101层的ResNet,可以看出,总体而言,增加的非局部模块越多,最后的精度越高。
(d)展示了时间、空间和时空同时非局部的效果,时空一起的效果最好。
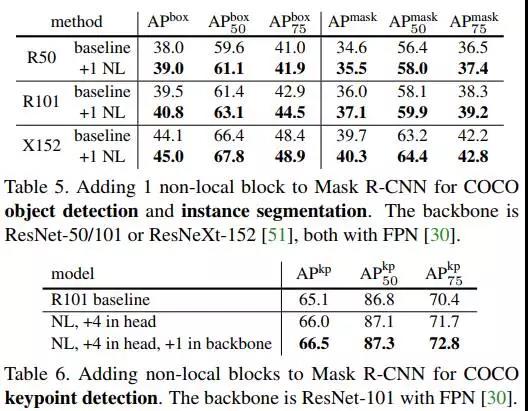
(e)对比了非局部模块和三维卷积神经网络,增加了非局部模块(5个)的效果要好一点点。
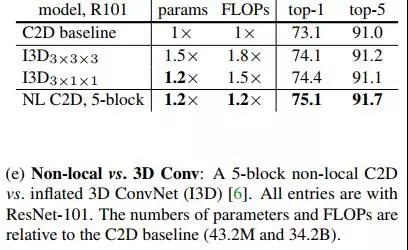
(f)将非局部与三维卷积相结合的效果,结合了比单纯的三维卷积更好。
(g)检验了在128帧的视频中(f)中的模型的效果,发现能够保持比较稳定。
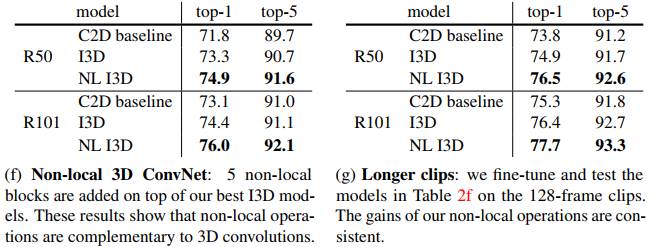
最后,下面这张图展示了将非局部模块与 Mask R-CNN 结合后,在 COCO 物体检测、实例分割以及人体关键点检测任务中性能均有所提升,使用了50和100层的ResNet,以及152层的ResNeXt。