音频多人声分离赛题分析
1.要求
本项目要求能够设计一个在不使用 GPU 的环境下运行,在精细度、速度和模型大小上取得平衡的最佳化的算法模型。
此外,本项目要求实施者自行以收集开源数据或自主建立数据的方式收集数据、建立音频多人声分离算法模型。
并完成模型训练、优化、工程化等工作,最终产出一个可执行程序,针对 50 个音频测试集进行多人声分离。
简单总结一下:
1.自行进行数据采集和数据清洗
2.用于训练的音频数量自定
3.建立合适的网络模型框架进行训练
4.针对多人声分离效果和性能进行参数调整、模型优化
5.提供 PC 端可执行程序入口,对本次提供的 50 个测试集进行多人声分离的效果呈现。
首先,第一条数据采集很简单,自己录下多人交流的录音即可,数据清洗我理解的是将背景的环境噪音去除掉
音频数量自定,应该说的是音频里有几个人声可以自定
建立模型框架以及后续的参数调整与模型优化目前没啥好的想法
最后就是需要将项目打包成一个exe文件,运行exe将数据导入之后可以查看分离效果
赛题还有一些技术要求
【技术要求与指标】
模型大小 不超过 20MB,越小越好,需要注明模型精度格式(FP 32,FP16,INT8)
算法性能指标 在 interli7CPU 处理一个时长 2 分钟的音频的时间不超过 10 秒
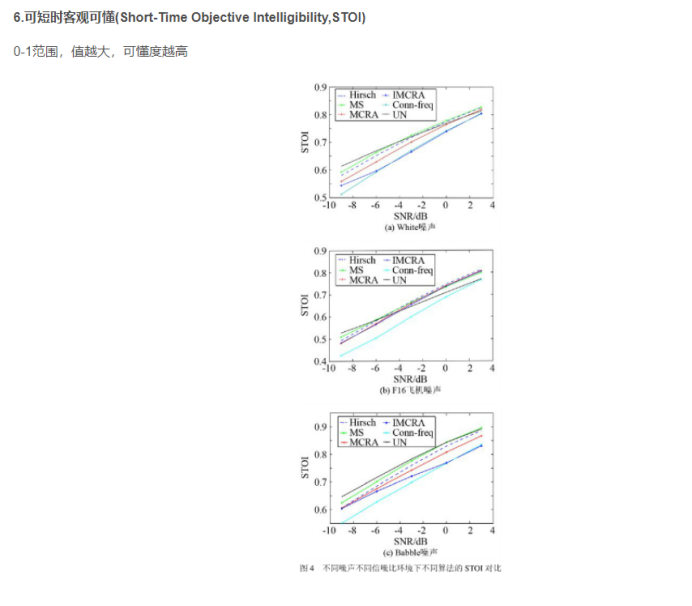
效果指标 STOI(Short-Time Objective Intelligibility)
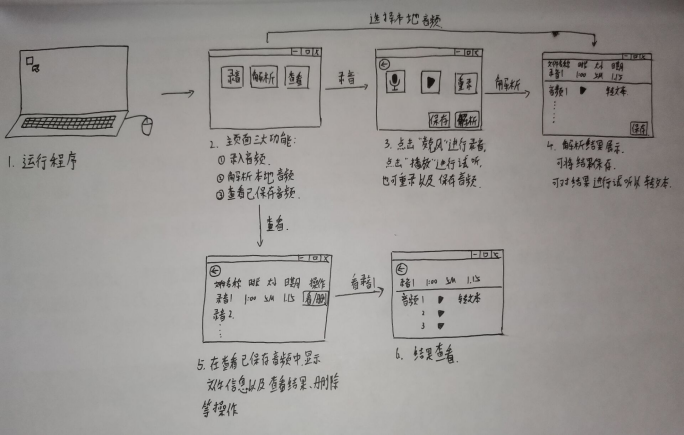
2.个人想法及个人纸上原型图
获取数据很简单,但是将数据中的环境噪音去除以及根据已获取的数据进行模型建立以及训练优化等比较难
因为所需要用到的技术之前并未学习过所以现在没有什么思路与想法,要边学边思考
其次就是在不使用GPU的环境下运行,我不太理解是什么意思与效果
以下为我个人想法中的项目功能雏形,仅供参考
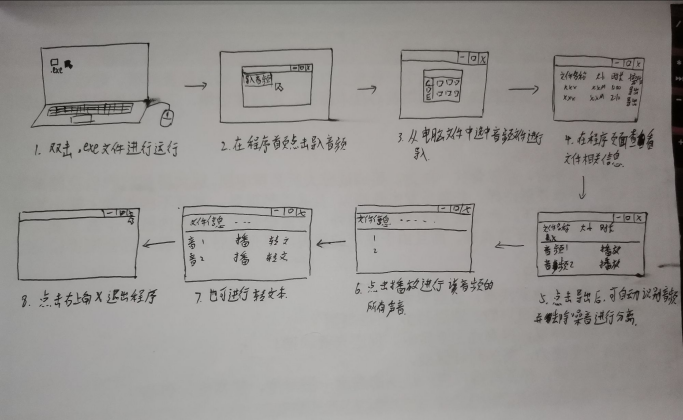
(后续补充)以及在经过小组讨论后,统一了一下