Elasticsearch是什么
The Elastic Stack, 包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。 能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。Elaticsearch,简称为 ES,ES 是一个开源的高扩展的分布式全文搜索引擎,是整个 Elastic Stack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据
全文搜索引擎
Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
基于以上原因可以分析得出,在一些生产环境中,使用常规的搜索方式,性能是非常差的:
- 搜索的数据对象是大量的非结构化的文本数据
- 文件记录量达到数十万或数百万个甚至更多
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。 为了解决结构化数据搜索和非结构化数据搜索性能问题,我们就需要专业,健壮,强大的全文搜索引擎
Elasticsearch And Solr
Lucene 是 Apache 软件基金会 Jakarta 项目组的一个子项目,提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在 Java 开发环境里 Lucene 是一个成熟的免费开源 工具。就其本身而言,Lucene 是当前以及最近几年最受欢迎的免费 Java 信息检索程序库。 但 Lucene 只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的 服务框架搭建起来进行应用。
目前市面上流行的搜索引擎软件,主流的就两款:Elasticsearch 和 Solr,这两款都是基 于 Lucene 搭建的,可以独立部署启动的搜索引擎服务软件。由于内核相同,所以两者除了 服务器安装、部署、管理、集群以外,对于数据的操作 修改、添加、保存、查询等等都十 分类似。
在使用过程中,一般都会将 Elasticsearch 和 Solr 这两个软件对比,然后进行选型。这两 个搜索引擎都是流行的,先进的的开源搜索引擎。它们都是围绕核心底层搜索库 Lucene 构建的,但它们又是不同的。像所有东西一样,每个都有其优点和缺点:
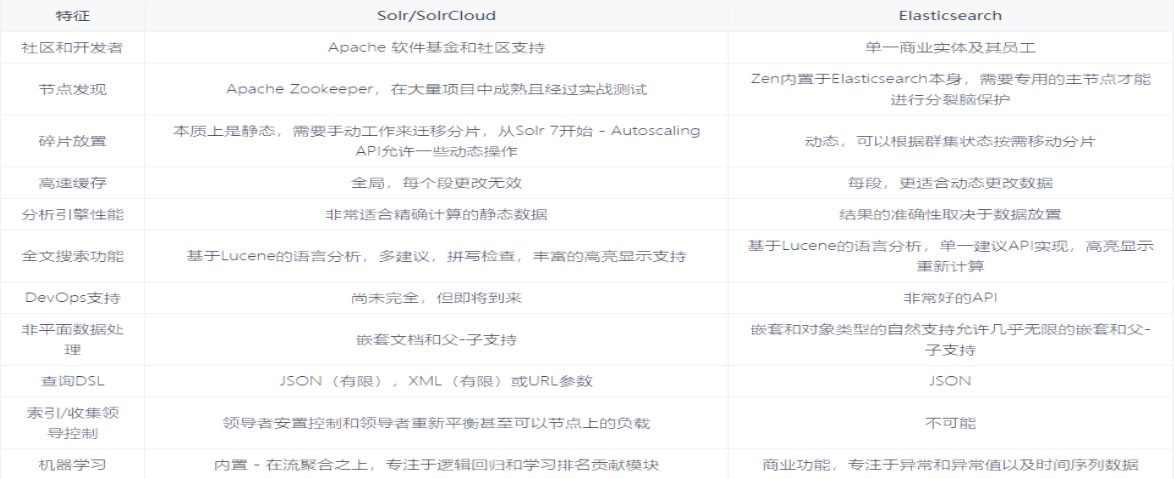
无论选择 Solr 还是 Elasticsearch,首先需要了解正确的用例和未来需求。总结一下Elasticsearch的特点:
- 由于易于使用,Elasticsearch 在新开发者中更受欢迎。一个下载和一个命令就可以启动一切
- 如果除了搜索文本之外还需要它来处理分析查询,Elasticsearch 是更好的选择
- 如果需要分布式索引,则需要选择 Elasticsearch。对于需要良好可伸缩性和以及性能分布式环境,Elasticsearch 是更好的选择
- Elasticsearch 在开源日志管理用例中占据主导地位,许多组织在 Elasticsearch 中索引它们的日志以使其可搜索
- 如果你喜欢监控和指标,那么请使用 Elasticsearch,因为相对于 Solr,Elasticsearch 暴露了更多的关键指标
Elasticsearch 安装
Elasticsearch 的官方地址:https://www.elastic.co/cn/
目录结构如下:
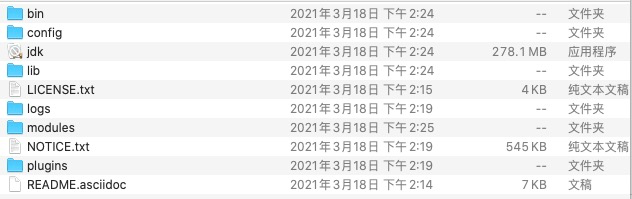
| 目录 | 含义 |
|---|---|
| bin | 可执行脚本目录 |
| config | 配置目录 |
| jdk | 内置 JDK 目录 |
| lib | 类库 |
| logs | 日志目录 |
| modules | 模块目录 |
| plugins | 插件目录 |
进入bin目录,启动elasticsearch即可启动服务
[2021-04-13T13:19:55,134][INFO ][o.e.n.Node ] [B-LW01J1WL-0028.local] initialized
[2021-04-13T13:19:55,134][INFO ][o.e.n.Node ] [B-LW01J1WL-0028.local] starting ...
[2021-04-13T13:19:55,193][INFO ][o.e.x.s.c.PersistentCache] [B-LW01J1WL-0028.local] persistent cache index loaded
[2021-04-13T13:20:00,475][INFO ][o.e.t.TransportService ] [B-LW01J1WL-0028.local] publish_address {127.0.0.1:9300}, bound_addresses {[::1]:9300}, {127.0.0.1:9300}
[2021-04-13T13:20:00,821][WARN ][o.e.b.BootstrapChecks ] [B-LW01J1WL-0028.local] the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
[2021-04-13T13:20:00,835][INFO ][o.e.c.c.ClusterBootstrapService] [B-LW01J1WL-0028.local] no discovery configuration found, will perform best-effort cluster bootstrapping after [3s] unless existing master is discovered
[2021-04-13T13:20:03,845][INFO ][o.e.c.c.Coordinator ] [B-LW01J1WL-0028.local] setting initial configuration to VotingConfiguration{havNlIPpSIKsyb4mq42F3Q}
[2021-04-13T13:20:04,170][INFO ][o.e.c.s.MasterService ] [B-LW01J1WL-0028.local] elected-as-master ([1] nodes joined)[{B-LW01J1WL-0028.local}{havNlIPpSIKsyb4mq42F3Q}{GWO-_Ju0TgKDaXcELngWqw}{127.0.0.1}{127.0.0.1:9300}{cdfhilmrstw}{ml.machine_memory=8589934592, xpack.installed=true, transform.node=true, ml.max_open_jobs=20, ml.max_jvm_size=4294967296} elect leader, _BECOME_MASTER_TASK_, _FINISH_ELECTION_], term: 1, version: 1, delta: master node changed {previous [], current [{B-LW01J1WL-0028.local}{havNlIPpSIKsyb4mq42F3Q}{GWO-_Ju0TgKDaXcELngWqw}{127.0.0.1}{127.0.0.1:9300}{cdfhilmrstw}{ml.machine_memory=8589934592, xpack.installed=true, transform.node=true, ml.max_open_jobs=20, ml.max_jvm_size=4294967296}]}
[2021-04-13T13:20:04,256][INFO ][o.e.c.c.CoordinationState] [B-LW01J1WL-0028.local] cluster UUID set to [8s0OS-nhQHazoUw6adHJEw]
[2021-04-13T13:20:04,324][INFO ][o.e.c.s.ClusterApplierService] [B-LW01J1WL-0028.local] master node changed {previous [], current [{B-LW01J1WL-0028.local}{havNlIPpSIKsyb4mq42F3Q}{GWO-_Ju0TgKDaXcELngWqw}{127.0.0.1}{127.0.0.1:9300}{cdfhilmrstw}{ml.machine_memory=8589934592, xpack.installed=true, transform.node=true, ml.max_open_jobs=20, ml.max_jvm_size=4294967296}]}, term: 1, version: 1, reason: Publication{term=1, version=1}
[2021-04-13T13:20:04,431][INFO ][o.e.h.AbstractHttpServerTransport] [B-LW01J1WL-0028.local] publish_address {127.0.0.1:9200}, bound_addresses {[::1]:9200}, {127.0.0.1:9200}
[2021-04-13T13:20:04,434][INFO ][o.e.n.Node ] [B-LW01J1WL-0028.local] started
9300端口为 Elasticsearch 集群间组件的通信端口,9200 端口为浏览器访问的 http 协议 RESTful 端口
// 访问服务
huanliu@B-LW01J1WL-0028 ~ % curl http://127.0.0.1:9200
{
"name" : "B-LW01J1WL-0028.local",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "8s0OS-nhQHazoUw6adHJEw",
"version" : {
"number" : "7.12.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "78722783c38caa25a70982b5b042074cde5d3b3a",
"build_date" : "2021-03-18T06:17:15.410153305Z",
"build_snapshot" : false,
"lucene_version" : "8.8.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
数据格式

Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比:ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type,Elasticsearch 7.X 中, Type的概念已经被删除了
Elasticsearch 基本操作
索引操作
// 创建索引,对比关系型数据库,创建索引就等同于创建数据库
PUT请求:http://127.0.0.1:9200/shopping
{
"acknowledged"【响应结果】: true, # true操作成功
"shards_acknowledged"【分片结果】: true, # 分片操作成功
"index"【索引名称】: "shopping"
}
// 如果重复添加索引,会返回错误信息
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [shopping/5upLIUrhTGWX6lWTG6BQBg] already exists",
"index_uuid": "5upLIUrhTGWX6lWTG6BQBg",
"index": "shopping"
}
],
"type": "resource_already_exists_exception",
// 索引已存在
"reason": "index [shopping/5upLIUrhTGWX6lWTG6BQBg] already exists",
"index_uuid": "5upLIUrhTGWX6lWTG6BQBg",
"index": "shopping"
},
"status": 400
}
// 查看所有索引
GET请求:http://127.0.0.1:9200/_cat/indices?v
/**
* 这里请求路径中的_cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES 服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉,服务器响应结果如下
* health:当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
* status:索引打开、关闭状态
* index:索引名
* uuid:索引统一编号
* pri:主分片数量
* rep:副本数量
* docs.count:可用文档数量
* docs.deleted:文档删除状态(逻辑删除)
* store.size:主分片和副分片整体占空间大小
* pri.store.size:主分片占空间大小
*/
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open shopping 5upLIUrhTGWX6lWTG6BQBg 1 1 0 0 208b 208b
// 查看单个索引
GET请求:http://127.0.0.1:9200/shopping
{
// 索引名
"shopping": {
// 别名
"aliases": {},
// 映射
"mappings": {},
// 设置
"settings": {
// 索引
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
// 主分片数据量
"number_of_shards": "1",
// 索引名称
"provided_name": "shopping",
// 创建时间
"creation_date": "1618294231972",
// 副分片数量
"number_of_replicas": "1",
// 唯一标识
"uuid": "5upLIUrhTGWX6lWTG6BQBg",
// 版本
"version": {
"created": "7120099"
}
}
}
}
}
// 删除索引
DELETE请求:http://127.0.0.1:9200/shopping
{
"acknowledged": true
}
// 重复请求会报错
{
"error": {
"root_cause": [
{
"type": "index_not_found_exception",
"reason": "no such index [shopping]",
"resource.type": "index_or_alias",
"resource.id": "shopping",
"index_uuid": "_na_",
"index": "shopping"
}
],
"type": "index_not_found_exception",
"reason": "no such index [shopping]",
"resource.type": "index_or_alias",
"resource.id": "shopping",
"index_uuid": "_na_",
"index": "shopping"
},
"status": 404
}
文档操作
// 创建文档,索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数 据库中的表数据,添加的数据格式为 JSON 格式
POST 请求 :http://127.0.0.1:9200/shopping/_doc
请求体:
// 这里数据创建后,由于没有指定数据唯一性标识(ID),默认情况下,ES 服务器会随机 生成一个。 如果想要自定义唯一性标识,需要在创建时指定:http://127.0.0.1:9200/shopping/_doc/1
{
"title":"小米手机",
"category":"小米",
"image":"https://www.xiaomi.com/1.jpg",
"price":1999
}
{
// 索引
"_index": "shopping",
// 类型-文档
"_type": "_doc",
// 唯一标识,可以类比为MySQL中的主键,随机生成
"_id": "6GbxyXgBsiazCaso13gh",
// 版本
"_version": 1,
// 结果,这里的create表示创建成功
"result": "created",
// 分片
"_shards": {
// 总数
"total": 2,
// 成功
"successful": 1,
// 失败
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
// 查看文档
GET请求:http://127.0.0.1:9200/shopping/_doc/6GbxyXgBsiazCaso13gh
{
// 索引
"_index": "shopping",
// 文档类型
"_type": "_doc",
"_id": "6GbxyXgBsiazCaso13gh",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
// 查询结果:true表示查找到,false表示未查找到
"found": true,
// 文档源信息
"_source": {
"title": "小米手机",
"category": "小米",
"image": "https://www.xiaomi.com/1.jpg",
"price": 1999
}
}
// 修改文档
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖
POST 请求 :http://127.0.0.1:9200/shopping/_doc/6GbxyXgBsiazCaso13gh
请求体内容为
{
"title": "华为手机",
"category": "华为",
"image": "https://www.huawei.com/1.jpg",
"price": 2999
}
{
"_index": "shopping",
"_type": "_doc",
"_id": "6GbxyXgBsiazCaso13gh",
// 版本
"_version": 2,
// 结果,updated表示数据被更新
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
// 修改字段,修改数据时,也可以只修改某一给条数据的局部信息
POST 请求 :http://127.0.0.1:9200/shopping/_update/6GbxyXgBsiazCaso13gh
{
"doc": {
"price":3000.00
}
}
{
"_index": "shopping",
"_type": "_doc",
"_id": "6GbxyXgBsiazCaso13gh",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
// 删除文档,删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
DELETE 请求 :http://127.0.0.1:9200/shopping/_doc/6GbxyXgBsiazCaso13gh
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
//#对数据的操作,都会更新版本
"_version" : 4,
// deleted表示数据被标记为删除
"result"【结果】: "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 2
}
// 条件删除文档:一般删除数据都是根据文档的唯一性标识进行删除,实际操作时,也可以根据条件对多条数据进行删除
POST 请求 :http://127.0.0.1:9200/shopping/_delete_by_query
请求体内容为:
{
"query":{
"match":{
"price":4000.00
}
}
}
{
// 耗时
"took": 175,
// 是否超时
"timed_out": false,
// 总数
"total": 2,
// 删除数量
"deleted": 2,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1.0,
"throttled_until_millis": 0,
"failures": []
}
映射操作
有了索引库,等于有了数据库中的 database。接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。 创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
// 创建映射
PUT 请求 :http://127.0.0.1:9200/student/_mapping
//
// 映射说明:
// 字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
// type:类型,Elasticsearch中支持的数据类型非常丰富,说几个关键的:
// String 类型,又分两种:
// text:可分词
// keyword:不可分词,数据会作为完整字段进行匹配
// Numerical:数值类型,分两类
// 基本数据类型:long、integer、short、byte、double、float、half_float
// 浮点数的高精度类型:scaled_float
// Date:日期类型
// Array:数组类型
// Object:对象
// index:是否索引,默认为true,也就是说你不进行任何配置,所有字段都会被索引。
// true:字段会被索引,则可以用来进行搜索
// false:字段不会被索引,不能用来搜索
// store:是否将数据进行独立存储,默认为 false。原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储 的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置 "store": true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用 更多的空间,所以要根据实际业务需求来设置。
// analyzer:分词器,这里的 ik_max_word 即使用 ik 分词器
{
"properties": {
"name":{
"type": "text",
"index": true
},
"sex":{
"type": "text",
"index": false
},
"age":{
"type": "long",
"index": false
}
}
}
// 查看映射
GET 请求 :http://127.0.0.1:9200/student/_mapping
{
"student": {
"mappings": {
"properties": {
"age": {
"type": "long",
"index": false
},
"name": {
"type": "text"
},
"sex": {
"type": "text",
"index": false
}
}
}
}
}
// 索引映射关联
PUT 请求 :http://127.0.0.1:9200/student1
请求体:
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": false
},
"age": {
"type": "long",
"index": false
}
}
}
}