开发环境:
本环境是基于centos 为系统环境。三台虚拟机,分别为master ,slave1 ,slaves2 。适用于hadoop 2.x.y 版本,省略Hadoop压缩包解压过程。
第一步 虚拟机的安装:
1.安装Vmware WorkStation 或者 Visualbox ,在这里以Vmware Workstation 为例
2.找到 新建虚拟机向导 ,一路回车。
加载需要安装系统光盘(以CentOS 为例)
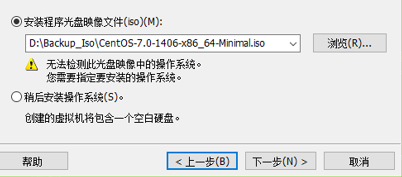
如果无法自动识别,手工选择操作系统。
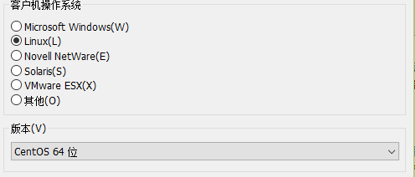
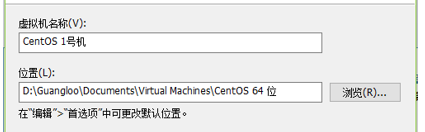
关于命名:为了方便做分布式计算时的区分,给每个虚拟机取独一无二的名字。
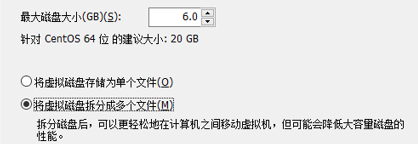
关于容量:根据自己的需要来设置硬盘大小,一般数据量不太大的话16GB合适。把虚拟硬盘拆成多个以后在与其他人合作时拷贝会更方便。
3.(本步若没有做在后面也可以改过来)本次配置为三台虚拟机,分别为master ,slave1 ,slave2 。为了在接下来的平台安装中操作方便,建议将用户名命名为:hadoop ,主机名分别命名为master ,slave1 ,slave2 。
第二步:Hadoop 平台的安装与配置
实验室里用的是Ubuntu 系统,但是我的电脑带不动。
1.创建hadoop用户(3台都要)
我们为hadoop实验专门创建用户hadoop。
在root条件下创建hadoop用户。
修改密码,密码为hadoop
su useradd -m hadoop -s /bin/bash passwd hadoop
修改sudo文件,使得hadoop拥有管理员权限
Visudo
在第98行增加以下指令(i插入,esc shift : 输入指令, q!不保存退出,wq 保存退出)
Hadoop ALL=(ALL) ALL

2.为了操作方便,我们需要修改一下三台主机名。
sudo vim /etc/sysconfig/network
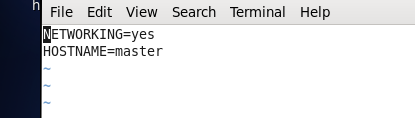
将namenode改为:HOSTNAME=master
将剩下的俩台datanode分别改为HOSTNAME=slave1 HOSTNAME=slave2
以namenode为例:
3.配置网络(3台都要)
输入 ifconfig -a ,查看各个虚拟机的ip 配置
ifconfig -a
以slave1 为例:

查看到三台虚拟机的IP如下:
192.168.93.134 master
192.168.93.135 slave1
192.168.93.136 slave2
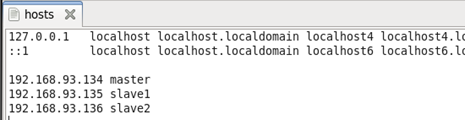
在三台服务器中的hosts文件中分别设置对应的主机名:
sudo gedit /etc/hosts
为了把三台主机的IP 地址都存到各自的host 中,我们把hosts文件最后一行中添加以下信息,:
192.168.93.134 master 192.168.93.135 slave1 192.168.93.136 slave2
4. 设置免密码登陆(在master操作)
在node1设置无密码登陆database服务器,执行:
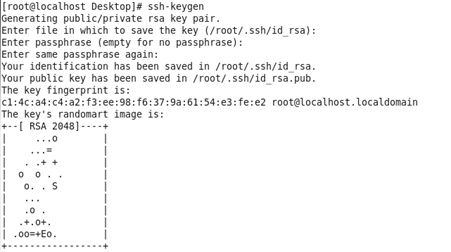
ssh-keygen
一路回车即可(图片是原来root权限下设置的)
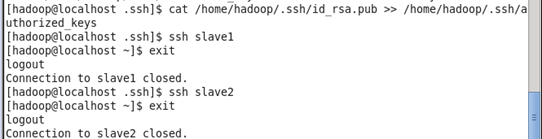
拷贝公钥至datanode。需注意公钥的确切路径(上图生成公钥图中有),需注意过程中需要输入datanode的登陆密码,然后将datanode加入到列表中。
ssh-copy-id –i /home/hadoop/.ssh/id_rsa.pub hadoop@slave1 ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@slave2 cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
注意:
在拷贝过程中无法建立连接时:

修改~/.ssh/下的authorized_keys文件权限(试了很多步骤发现这一步非常非常关键)
chmod 600 ./authorized_keys
在are you sure you want to continue connecting时不要按回车而是yes再回车

第三步:安装JAVA(三台都要)
因为Hadoop 用的是Java API ,所以在这里我们安装Java。
在联网情况下在线安装JAVA,在遇到Y/N时输入y,然后一路回车
sudo yum install java-1.7.0-openjdk java-1.7.0-openjdk-devel
yum默认安装路径为/usr/lib/jvm
查看绝对路径,用于配置环境变量
rpm -ql java-1.7.0-openjdk-devel | grep '/bin/javac'
其中,/bin/javac之前的就是绝对路径了
/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.161.x86_64

先进入.bashrc所在文件位置
打开.bashrc文件
cd ~/
sudo gedit ~/.bashrc
在最后一行输入如下语句,保存退出
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.161.x86_64

接着还需要让该环境变量生效(非常重要!),执行如下代码:
source ~/.bashrc
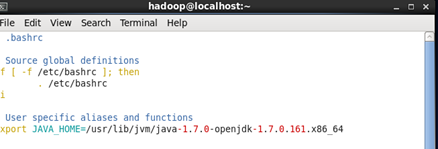
这个时候环境变量应该是配好了,为了验证效果。我们输入
echo $JAVA_HOME
java -version
$JAVA_HOME/bin/java –version
如果设置正确的话,$JAVA_HOME/bin/java -version 会输出 java 的版本信息,且和 java -version 的输出结果一样
第四步:安装hadoop
我们选择下载hadoop 2.6.5版本
下载时需要下载hadoop-2.6.5.tar.gz文件,此为已经编译好的,可以直接使用的压缩包。
Linux系统下载的文件一般在download文件夹中。
我们将压缩文件解压到/usr/local/中,为了防止hadoop文件夹不能被修改,还需要改一下权限。
sudo tar -zxf ~/download/hadoop-2.6.5.tar.gz -C /usr/local cd /usr/local/ sudo mv ./hadoop-2.6.0/ ./hadoop sudo chown -R hadoop:hadoop ./Hadoop
解压后还需要验证hadoops是否能用,输入如下指令验证版本信息
cd /usr/local/hadoop
./bin/hadoop version
然后我们要配置hadoop环境
sudo vim ~/.bashrc
在文件最后添加如下语句,保存退出:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"

保存后依然要使新的配置生效
souce ~/.bashrc
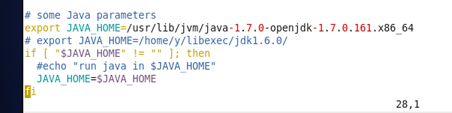
由于我们java版本的限制,所以我们还要修改hadoop文件中相关的java环境变量
文件所在路径:/usr/local/hadoop/etc/hadoop/
需要修改的俩个文件为: hadoop-env.sh,yarn-env.sh
hadoop-env.sh
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改:export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.161.x86_64

yarn-env.sh
sudo vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
修改:export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.161.x86_64
配置分布式环境:
首先需要配置/usr/local/hadoop/etc/hadoop中的5个文件:
(注意master应该与主机名字master一致)
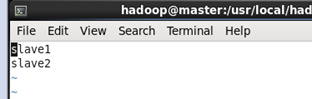
slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
slave:
将文件中原来的localhost删除,添加salve1,slave2
core-site.xml:
改为如下配置:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property>m= <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>
hdfs-site.xml:
改为如下配置:
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
mapred-site.xml:
(可能需要重命名,默认文件名为:mapred-site.xml.template),修改如下:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration> yarn-site.xml,还是修改: <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
yarn-site.xml:
修改如下:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
第五步:启动Hadoop
启动需要在master节点上进行。
输入如下命令:
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
通过jps指令查看各个节点的启动进程,master节点应该看到NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer进程。slave节点可以看到DataNode 和 NodeManager 进程。缺少任何一个进程都表示出错。
jps
如下所示:
Namenode(master节点)

Datanode(slave节点)

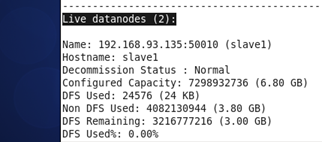
可以通过master节点上命令查看datanode是否正常启动,如果live datanodes不为0,则说明启动成功。如图,我这里俩个datanode都活了。
hdfs dfsadmin –report
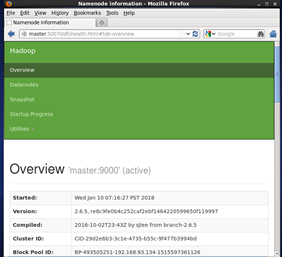
通过 web 页面 http://master:50070/ 可以查看datanode 和nameode 状态
附录:
这些仅仅作为自己安装完成后的一个流程备忘,仅仅记录关键流程。
在学习了网上博主的博客后很有感触。在文末我附上对我帮助非常大的博客原地址,希望大家能有不同的启发。
创建hadoop用户:
如果作为实验的话root用户也可以,注意备份。
安装java环境:
如果要用java写云计算程序,最好用eclipse,可以导入jar包,安装eclipes的前提是java版本2.0+。
直接从官网下的话应该是java8,在windows系统下安装后不需要配环境,linux系统下没试过不知道。
如果相对路径不行,就写绝对路径。
#2018.9.26 更新:
JDK8可行,具体在Ubuntu环境下配置Hadoop分布式集群一文中显示。
防火墙:
centos在在开启Hadoop之前,需要关闭每一个节点的防火墙。
特别感谢:
给力星前辈写的非常好,单机和集群俩篇文章对我启发都很大。可以说我的第一个hadoop集群就是在他的博文指导下搭建好的。吃水不忘挖井人,在向前辈表示感谢的同时,特此附上原网址:
http://www.powerxing.com/install-hadoop-in-centos/
-----------------------------------------------------------------------------------------------------