2018年8月份学习使用solr,当时下载的版本是solr7.5,写这篇博文的时候是2019年3月份,solr此时已经出到了8.0版本。一个大版本的变迁肯定有很多的改动,暂时还未研究就不赘述了。
此篇博客只是记述一下当时对solr的使用方面研究。
solr下载地址:http://www.apache.org/dyn/closer.lua/lucene/solr/8.0.0
一、Lucene
在了解solr之前,先了解一下Lucene,Lucene是一个全文检索的工具包,本质上是一个jar包,它无法单独在web容器中运行,但是你可以把它导入到某个项目里进行开发使用。当然现在solr已经帮你整好了,不建议这么用。
Lucene进行全文检索的结构图如下

1)采集数据
从不同的源进行数据收集,例如数据库,web端等。
数据库:其他系统存储在数据库中的数据
web端:直接从web端录入的数据
2)创建索引
数据采集完成后,Lucene会将采集到的所有数据创建索引,并将索引存储在索引库中
3)用户查询
用户在web端,输入索引关键词,SearchIndex会根据关键词在索引库中进行索引查找
4)返回结果
SearchIndex查找到结果后返回给用户
二、solr
solr是建立在Lucene基础上的一个项目包,它可以在Tomcat等web容器中直接运行,同时提供全文检索服务。
但是,solr7.5是可以直接运行的,不需要再像某个版本(我也不知道哪个版本)之前需要将solr打包发布到Tomcat才能运行使用。
1.solr下载
solr下载地址:http://www.apache.org/dyn/closer.lua/lucene/solr/
2.solr包功能介绍
下载solr包后解压,包内目录以及各自功能如下:
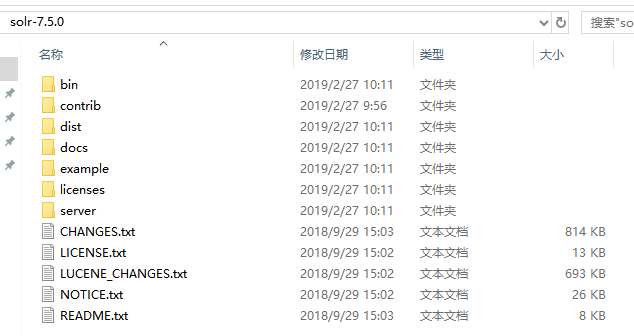
- bin:包括一些使用Solr的重要脚本
solr和solr.cmd:分别用于Linux和Windows系统,根据所选参数不同而控制Solr的启动和停止
post:提供了一个用于发布内容的命令行接口工具。支持导入JSON,XML和CSV,也可以导入HTML,PDF,Microsoft Office格式(如MS Word),纯文本等等。
solr.in.sh和solr.in.cmd:分别用于Linux和Windows系统的属性文件
install_solr_services.sh:用于Linux系统将Solr作为服务安装
- contrib:包含一些solr的一些插件或扩展
analysis-extras: 包含一些文本分析组件及其依赖
clustering:包含一个用于集群搜索结果的引擎
dataimporthandler:把数据从数据库或其它数据源导入到solr
extraction:整合了Apache Tika,Tika是用于解析一些富文本(诸如Word,PDF)的框架
langid:检测将要索引的数据的语言
map-reduce:包含一些工具用于Solr和Hadoop Map Reduce协同工作
morphlines-core:包含Kite Morphlines,它用于构建、改变基于Hadoop进行ETL(extract、transfer、load)的流式处理程序
uima:包含用于整合Apache UIMA(文本元数据提取的框架)类库
velocity:包含基于Velocity模板的简单的搜索UI框架
- dist:包含主要的Solr的jar文件
- docs:文档
- example:包含一些展示solr功能的例子
exampledocs:这是一系列简单的CSV,XML和JSON文件,可以bin/post在首次使用Solr时使用
example-DIH:此目录包含一些DataImport Handler(DIH)示例,可帮助您开始在数据库,电子邮件服务器甚至Atom订阅源中导入结构化内容。每个示例将索引不同的数据集
files:该files目录为您可能在本地存储的文档(例如Word或PDF)提供基本的搜索UI
films:该films目录包含一组关于电影的强大数据,包括三种格式:CSV,XML和JSON
- licenses:包含所有的solr所用到的第三方库的许可证
- server:solr应用程序的核心,包含了运行Solr实例而安装好的Jetty servlet容器。
contexts:这个文件包含了solr Web应用程序的Jetty Web应用的部署的配置文件
etc:主要就是一些Jetty的配置文件和示例SSL密钥库
lib:Jetty和其他第三方的jar包
logs:Solr的日志文件
resources:Jetty-logging和log4j的属性配置文件
solr:新建的core或Collection的默认保存目录,里面必须要包含solr.xml文件
configsets:包含solr的配置文件
solr-webapp:包含solr服务器使用的文件;不要在此目录中编辑文件(solr不是JavaWeb应用程序)
3.solr启动
打开solr的bin目录,shift+鼠标右键,“在此处打开powershell窗口”

输入.solr start

成功启动后,在浏览器中访问如下地址:
http://localhost:8983
4.solr具体参数配置
讲道理,有点多,参照下面这个博客即可。
https://blog.csdn.net/bskfnvjtlyzmv867/article/details/80940089