原文地址:
https://blog.csdn.net/jiangpeng59/article/details/72867368
作者:PJ-Javis
来源:CSDN
------------------------------------------------------------------------------------------------------
1.实验环境
C
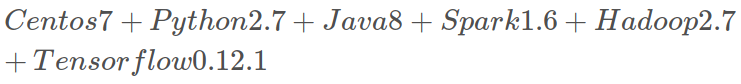
Spark和Hadoop的集群搭建网上教程比较多,这里以最简洁的方法配置集群,针对tensorflow添加的额外配置,我会进行强调(其实地上本没有坑,跌的人多了,也便成了Keng)
1>系统环境环境变量
export JAVA_HOME=/hadoop/jdk1.8.0_65 export HADOOP_HOME=/hadoop/hadoop-2.7.0 export SPARK_HOME=/hadoop/spark-1.6.0 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$SPARK_HOME/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
在/etc/profile或者~/.bashrc中配置都行,CLASSPATH不能少(Keng1)
2>hadoop集群
需修改的配置文件都在$HADOOP_HOME/hadoop-2.7.0/etc/hadoop目录下
(1)修改hadoop-env.sh 文件
export JAVA_HOME=/hadoop/jdk1.8.0_65
(2)修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoop-2.7.0/tmp</value>
</property>
</configuration>
注意这里我把hdfs的namenode也设置在master节点上,hadoop.tmp.dir为hadoop的绝对路径
(3)修改文件hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/hadoop-2.7.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/hadoop-2.7.0/dfs/data</value>
</property>
</configuration>
(4)修改slaves文件,配置DataNode节点地址
这里的hosts我已经配置好,所以输入你对应的hostname就行了
slave01
slave02
slave03
(5)格式化namenode并启动hdfs
hdfs namenode -format
$HADOOP_HOME/sbin/start-dfs.sh
3>Spark集群
Spark集群Standalone的配置非常简单,修改2个文件即可,在此之前记得重命名去掉template
(1)配置spark-env.sh
export JAVA_HOME=/hadoop/jdk1.8.0_65 export HADOOP_CONF_DIR=/hadoop/hadoop-2.7.0/etc/hadoop export HADOOP_HDFS_HOME=/hadoop/hadoop-2.7.0 SPARK_MASTER_IP=master SPARK_WORKER_CORES=4 SPARK_WORKER_MEMORY=12G SPARK_EXECUTOR_MEMORY=8G
核数和内存根据自己的机器进行设置,环境变量HADOOP_CONF_DIR和HADOOP_HDFS_HOME不能少(Keng2)
(2)配置slaves
slave01
slave02
slave03
(3)启动spark集群
$SPARK_HOME/sbin/start-all.sh
Worker Id Cores Memory
worker1 4 (0 Used) 12.0 GB (0.0 B Used)
worker2 4 (0 Used) 12.0 GB (0.0 B Used)
worker3 4 (0 Used) 12.0 GB (0.0 B Used)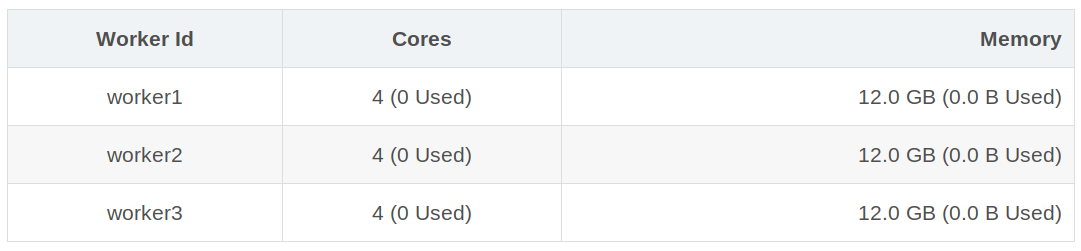
集群总共3个worker-instance,每个worker4核12G,总12核,所有的环境配置均和master节点一致(Keng3)
2.Tensorflow安装
雅虎目前开源的框架是基于python2.7和Tensorflow0.12.1的,目前Tensorflow版本为1.2,但是考虑到兼容性,我们还是使用推荐的版本进行测试。
安装Tensorflow0.12.1
pip install https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.1-cp27-none-linux_x86_64.whl
测试tf,无异常说明安装成功
import tensorflow as tf
3.下载TensorflowOnSpark源码
git clone https://github.com/yahoo/TensorFlowOnSpark.git
cd TensorFlowOnSpark
export TFoS_HOME=$(pwd)
这里使用git进行下载,最后我会所有用到资源的百度云链接。顺便提一句,TensorflowOnSpark最近好像更新了,但是指导文档貌似有点问题,下面会进行说明。
[root@master TensorFlowOnSpark]# ls examples LICENSE README.md scripts setup.cfg setup.py tensorflow tensorflowonspark tfspark.zip
下载成功后,你会得到类似上面的文件夹,tfspark.zip是我们生成的python库文件,之后提交Spark的时候用到,其就是把tensorflowonspark所有文件进行了打包,在TensorFlowOnSpark目录运行如下的命令进行打包(Keng4)
zip -r tfspark.zip tensorflowonspark/*
Spark集群测试
1>转换MNIST数据文件
${SPARK_HOME}/bin/spark-submit
--master=local[*]
${TFoS_HOME}/examples/mnist/mnist_data_setup.py
--output examples/mnist/csv
--format csv
该命令的功能是把之前下载的.gz文件转换为对应的scv文件,网上有人说要修改源码才能正常运行,能偷懒的地方绝不放过。可以先看下mnist_data_setup.py的源码
def writeMNIST(sc, input_images, input_labels, output, format, num_partitions): """Writes MNIST image/label vectors into parallelized files on HDFS""" # load MNIST gzip into memory with open(input_images, 'rb') as f: images = numpy.array(mnist.extract_images(f)) imageRDD = sc.parallelize(images.reshape(shape[0], shape[1] * shape[2]), num_partitions) if not args.read: # Note: these files are inside the mnist.zip file writeMNIST(sc, "mnist/train-images-idx3-ubyte.gz", "mnist/train-labels-idx1-ubyte.gz", args.output + "/train", args.format, args.num_partitions) writeMNIST(sc, "mnist/t10k-images-idx3-ubyte.gz", "mnist/t10k-labels-idx1-ubyte.gz", args.output + "/test", args.format, args.num_partitions)
使用python的IO流读取gz文件数据,显然gz文件肯定本地而非hdfs上,因此为了兼容源码,可以把mnist放在$PARK_HOME/bin下,然后使用本地模式进行数据转换即可
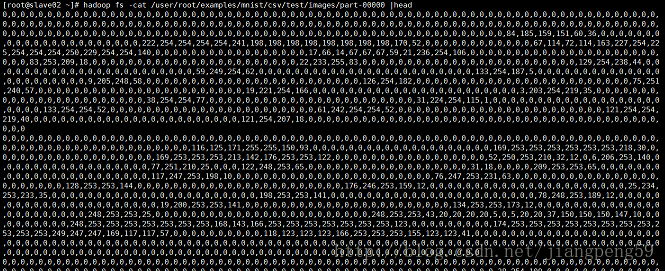
里面的内容和之前tensorflow介绍的一样是一个[,28*28]的向量,这里就是784个数为一行。
2>训练模型
${SPARK_HOME}/bin/spark-submit
--master=spark://master:7077
--conf spark.executorEnv.LD_LIBRARY_PATH="${JAVA_HOME}/jre/lib/amd64/server"
--conf spark.executorEnv.CLASSPATH="$($HADOOP_HOME/bin/hadoop classpath --glob):${CLASSPATH}"
--py-files ${TFoS_HOME}/examples/mnist/spark/mnist_dist.py,${TFoS_HOME}/tfspark.zip
--conf spark.cores.max=12
--conf spark.task.cpus=4
${TFoS_HOME}/examples/mnist/spark/mnist_spark.py
--cluster_size 3
--images examples/mnist/csv/train/images
--labels examples/mnist/csv/train/labels
--format csv
--mode train
--model mnist_model
这里是个天Keng,
-No.1_作者更新git,在指导文档中居然没有再提及tfspark.zip,这叫我这个Python菜鸟情何以堪
-No.2_因为本人的Spark集群和作者的不一样,这里建议设置spark.cores.max(集群总核数)和spark.task.cpus(worker节点分配核数)满足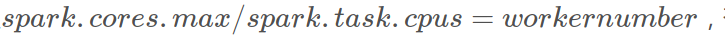
否则会出现无尽等待的情况:
2017-06-05 09:20:06,132 INFO (MainThread-23875) waiting for 1 reservations ..........
-No.3_这个Keng有点深,之前不知道是什么原因,执行命后会出现卡住的情况,百度到如下解决方案:
需要改一下mnist_dist.py的第109行,把logdir=logdir 改成 logdir=None
虽然解决了卡主的情况,但是训练完成后,不知道mnist_model去哪了?本地和hdfs都找不到,继续执行测试集,发现准确度几乎是0%(⊙﹏⊙)…之后查看worker的error日志,发现该信息一直都存在
INFO:tensorflow:Waiting for model to be ready. Ready_for_local_init_op: None, ready: Variables not initialized: hid_w, hid_b, sm_w, sm_b, Variable, hid_w/Adagrad, hid_b/Adagrad, sm_w/Adagrad, sm_b/Adagrad 2017-06-05 05:00:55,324 INFO (MainThread-31600) Waiting for model to be ready. Ready_for_local_init_op: None, ready: Variables not initialized: hid_w, hid_b, sm_w, sm_b, Variable, hid_w/Adagrad, hid_b/Adagrad, sm_w/Adagrad, sm_b/Adagrad
最终在github上找到了解决方法,原来python在写hdfs文件的时候,找不到对应的jar包,在提交的时候添加如下的配置信息
--conf spark.executorEnv.LD_LIBRARY_PATH="${JAVA_HOME}/jre/lib/amd64/server" --conf spark.executorEnv.CLASSPATH="$($HADOOP_HOME/bin/hadoop classpath --glob):${CLASSPATH}"
最终可以解决卡住的情况,终于在hdfs上面和model相遇了O(∩_∩)O~
3>模型测试
如此多的Keng 做铺垫,测试的时候终于一气呵成了!
${SPARK_HOME}/bin/spark-submit
--master spark://master:7077
--conf spark.executorEnv.LD_LIBRARY_PATH="${JAVA_HOME}/jre/lib/amd64/server"
--conf spark.executorEnv.CLASSPATH="$($HADOOP_HOME/bin/hadoop classpath --glob):${CLASSPATH}"
--py-files ${TFoS_HOME}/tfspark.zip,${TFoS_HOME}/examples/mnist/spark/mnist_dist.py
--conf spark.cores.max=12
--conf spark.task.cpus=4
--conf spark.executorEnv.JAVA_HOME="$JAVA_HOME"
${TFoS_HOME}/examples/mnist/spark/mnist_spark.py
--cluster_size 3
--images examples/mnist/csv/test/images
--labels examples/mnist/csv/test/labels
--mode inference
--format csv
--model mnist_model
--output predictions
部分结果如下:
[root@slave01 ~]# hadoop fs -cat /user/root/predictions/part-00000 2017-06-05T05:48:00.385513 Label: 7, Prediction: 7 2017-06-05T05:48:00.385574 Label: 2, Prediction: 2 2017-06-05T05:48:00.385591 Label: 1, Prediction: 1 2017-06-05T05:48:00.385625 Label: 0, Prediction: 0 2017-06-05T05:48:00.385639 Label: 4, Prediction: 4 2017-06-05T05:48:00.385653 Label: 1, Prediction: 1 2017-06-05T05:48:00.385667 Label: 4, Prediction: 4 2017-06-05T05:48:00.385680 Label: 9, Prediction: 9 2017-06-05T05:48:00.385697 Label: 5, Prediction: 6 2017-06-05T05:48:00.385711 Label: 9, Prediction: 9 2017-06-05T05:48:00.385724 Label: 0, Prediction: 0 2017-06-05T05:48:00.385736 Label: 6, Prediction: 6 2017-06-05T05:48:00.385749 Label: 9, Prediction: 9 2017-06-05T05:48:00.385762 Label: 0, Prediction: 0 2017-06-05T05:48:00.385775 Label: 1, Prediction: 1 2017-06-05T05:48:00.385788 Label: 5, Prediction: 5
解铃还须系铃人,问题来于Git解决于Git
tf百度资源:http://pan.baidu.com/s/1bpEhPHP
参考:
https://github.com/yahoo/TensorFlowOnSpark/issues/33
------------------------------------------------------------------------------------------------------