CAS( compare and swap) 原子操作,保证了如果需要更新的地址没有被其他进程(线程)改动过,那么它可以安全的写入。而这也是我们对于某个数据或者数据结构加锁要保护的内容,保证读写的一致性,不出现dirty data。可在循环中不断执行CAS,如果共享变量没有改变,那么swap,在当前环境中写入,否则继续do-while的Retry-Loop。
1 int compare_and_swap (int* reg, int oldval, int newval) { 2 ATOMIC(); 3 int old_reg_val = *reg; 4 if (old_reg_val == oldval) 5 *reg = newval; 6 END_ATOMIC(); 7 return old_reg_val; 8 }
ABA问题最容易发生在lock free算法中的,地址被重用的情况
无锁相当于“锁”的粒度变小了,主要是“锁”HEAD和TAIL这两个关键资源。而不是整个数据结构。
无锁与自旋锁比较:
无锁

自旋锁
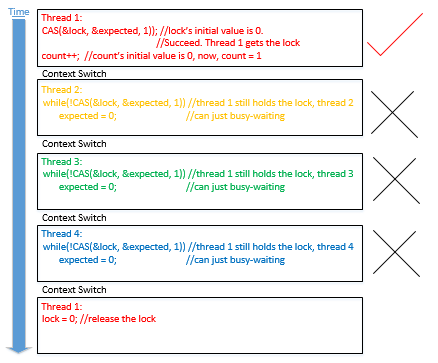
自旋锁与互斥锁比较:
1. 自旋锁不会使线程状态发生切换,一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换,执行速度快
2. 互斥锁在获取不到锁的时候会进入阻塞状态,从而进入内核态,当获取到锁的时候需要从内核态恢复,需要线程上下文切换。 (线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能)
- 自旋锁:线程获取锁的时候,如果锁被其他线程持有,则当前线程将循环等待,直到获取到锁。
- 自旋锁等待期间,线程的状态不会改变,线程一直是用户态并且是活动的(active)。
- 自旋锁如果持有锁的时间太长,则会导致其它等待获取锁的线程耗尽CPU。
- 自旋锁本身无法保证公平性,同时也无法保证可重入性。
- 基于自旋锁,可以实现具备公平性和可重入性质的锁。
- TicketLock:采用类似银行排号叫好的方式实现自旋锁的公平性,但是由于不停的读取serviceNum,每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
- CLHLock和MCSLock通过链表的方式避免了减少了处理器缓存同步,极大的提高了性能,区别在于CLHLock是通过轮询其前驱节点的状态,而MCS则是查看当前节点的锁状态。
Mutex主要解决并发实体之间的互斥的问题,而semaphone主要解决并发实体之间的同步问题。针对一些临界区比较少,处理开销比较小,而且实时性要求比较高的场景可以使用spin_lock来替代mutex实现互斥, 而如果需要共享的数据只有一个字段,可以使用lock-free的方式来替代spin_lock从而达到更高的性能。
条件变量:
用wait和signal实现同步互斥,其中这两个操作需要用互斥量包裹,互斥锁+条件变量可以实现读写锁(多个读锁可以进入临界区,只有一个写锁进入临界区,读写锁同时只能有一种进入临界区)
条件变量是进程中的全局变量(针对线程),信号量是系统中的全局变量(针对进程)
参考博客: