为什么需要进行代码拆分?
随着前端代码需要处理的业务越来越繁重,我们不得不面临的问题是前端的代码体积也变得越来越庞大。这造成无论是在调试还是在上线时候都需要
花长时间等待编译完成,并且用户也不得不花额外的时间和带宽下载更大体积的脚本文件。对于性能优化来说,需要减少http请求,用webpack
进行应用的构建打包,将我们应用以及应用所需的模块打包成一个大bundle。这样确实是减少了HTTP的请求,但这样做也产生了其他问题:
- 首屏加载时间过长,导致白屏,移动端网络不稳定最明显
- 当修改业务代码以后,整个大的bundle需要重新下载
- 在开发时候,如果是修改有一行代码,我们需要重新打包文件
- 用户只是粗略浏览页面也需要将整个站点的脚本全部先下载下来
所以就需要按需的,有策略性的将代码拆分和提供给用户。webpack就允许我们在打包时候讲脚本分块;利用浏览器缓存我们根据需要加载资源。
根据webpack术语表,存在两类文件的分离。这些名词听起来可以互换的,但是实际上不行
- 打包分离(Bundle splitting):为了更好的缓存创建更多、更小的文件(但仍然以每一个文件一个请求的方式进行加载);
- 代码分离(Code splitting):动态加载代码,所以用户只需要下载当前他正在浏览站点这部分代码
Bundle VS Chunk VS Module
首先对于模块(module)的概念相信大家都没有异议,它指的是我们在编码过程中有意识的封装和组织起来的代码片段。狭义上我们首先先到的是碎片化的Vue组件,或者是CommonJS模块
又或者是ES6模块,但是对Webpack和loader而言,广义上的模块还包括样式和图片,甚至说是不同类型的文件。
而包(bundle)就是把相关代码都打包进入的耽搁文件。如果你不想把所有的代码都放入一个包中,你可以把它们划分为多个包,也就是块(chunk)中。从这个角度看,块(chunk)等于包(bundle),
他们都是对代码再一层的组织和封装。如果必须要给一个区分的话,通常我们在讨论时,bundle指的是所有某块都打包进入的耽搁文件,而chunk指的是按照某种规则的模块集合,chunk的体积大于
单个模块,同时小于整个bundle
Bundle splitting打包分离
打包分离背后的思想非常简单。如果你有一个体积巨大的文件,并且只改了一行代码,用户仍然需要重新下载整个文件。但是如果你把它分为了两个文件,那么用户只需要下载那个被修改的文件,
而浏览器则可以从缓存中加载另一个文件。值得注意的是因为打包分离预缓存相关,所以对站点的首次访问者来说没有区别。当谈论到频繁访问者时,量化性能提升会稍有棘手,但是我们必须量化
这将需要一张表格,我们将每一种场景与每一种策略的组合结果都记录下来
我们假设一个场景
- Alice连续10周每周访问站点一次
- 我们每周更新站点一次
- 我们每周更新"产品列表"页面
- 我们也有一个"产品详情的页面",但是目前不许需要对他进行更新
- 在第5周的时我们给站点新增了一个npm包
- 在第8周时我们更新了现有的一个npm包
性能基线
假设我们的Javascript打包后的总体积为400KB,将它命名为main.js,然后以单文件的形式加载它
const path = require('path');
const HtmlWebpackPlugin = require("html-webpack-plugin");
const {CleanWebpackPlugin} = require("clean-webpack-plugin");
module.exports = {
entry:"./src/index.js",
output:{
filename:"[name].[contenthash].js",
path:path.resolve(__dirnane,"dist")
}
}
当只有单个入口,webpack会自动把结果命名为main.js。main.js实际上是在说类似于main.xxxx.js这种包含一堆带有文件内容哈希字符串的东西。这意味着当你应用代码发生改变时
新的文件名会生成,这样就能迫使浏览器下载新的文件
所以当每周我想沾点发布新的变更时,包的contenthash就会发生更改。以至于每周Alice访问我们沾点时不得不下载一个全新的400KB大小的文件
| 文件 | week1 | week2 | week3 | week4 | week5 | week6 | week7 | week8 | week9 | week10 |
|---|---|---|---|---|---|---|---|---|---|---|
| main.js | 400 | 400 | 400 | 400 | 420 | 420 | 420 | 420 | 420 | 420 |
| 连续十周就是4.12MB |
哈希(hash)与性能
是否会产生疑问
- 为什么带哈希串的文件名会对浏览器缓存产生影响?
- 为什么文件名里的哈希后缀是contenthash?如果把contenthash换成hash或者chunkhash有什么影响?
为了每次访问时不让浏览器都重新下载同一个文件,我们通常会把这个文件返回的HTTP头中的Cache-Control设置为max-age = 31536000,也就是一年(描述时间)。这样一来,
在一年之内用户访问这个文件时候,都不会再次向服务器发送请求二十直接从缓存中读取,知道或者手动清除了缓存。
如果我中途修改了文件内容必须让用户重新下载怎么办?修改文件名就好了,不同的文件(名)对应不同的缓存策略。二一个哈希字符串就是根据文件内容产生的"签名",每当文件内容发生更改时,
哈希串也就发生了更改,文件名也就随之更改。这样一来,旧版本文件的策略就会失效,浏览器就会重新加载新版本的改文件。当然这只是其中一种最基础的缓存策略。
所以在webpack中配置的filename:[name]:[contenthash].js就是为了每次发布时候自动生成的文件名。
对于webpack,它提供了另外两种哈希算法供开发者使用:hash和chunkhash。那么为什么不适用他们二十使用contenthash?这要从他们的区别说起。原则上来说,他们是为不同
目的服务的,但在实际操作中,也可以交替使用。
hash
hash针对的是每一次构建(build)而言,每一次构建之后生成的文件所带的哈希都是一致的。它关心的是整体项目的变化,只要有任一文件内容发生了更改,那么构建之后其他文件的哈希也会发生更改
很显然这不是我们需要的,如果module_a文件内容发生更改,module_a的打包文件的哈希应该发生变化,但是module_b不应该。这回导致用户不得不重新下载没有发生变化的module_b打包文件
chunkhash
chunkhash基于的是每一个chunk内容的改变,如果该chunk所属的内容发生了变化,那么只有该chunk的输出文件的哈希会发生变化,其他的不会。这听上去符合我们的需求。
在之前我们对chunk进行过定义,既是小单位的代码聚合形式。在下面面的例子中以entry入口体现,也就是说每一个入口对应的文件就是一个chunk。
contenthash
该哈希根据的是文件的内容。从这个角度上说,他和chunkhash是能够相互代替的。所以在"性能基线"代码中作者使用了contenthash,不过特殊之处是,或者说是关于它的使用说明中,都只是如果你
想在ExtractTextWebpackPlugin或者MiniCssExtractPlugin中使用到哈希标识,应该使用contenthash。
例子
webpack.bundleSplitting.js内容
const path = require("path");
const MiniCssExtractPlugin = require("mini-css-extract-plugin")
module.exports = {
entry:{
index:path.resolve(__dirname,'src/index.js'),
module_a:path.resolve(__dirname,"src/module_a.js"),
module_b:path.resolve(__dirname,"src/module_b.js")
},
output:{
filename:"[name].[hash].js",
path:path.resolve(__dirname,'dist')
},
module:{
rules:[
{
test:/.css/,
use:[
MiniCssExtractPlugin.loader,
"css-loader"
]
}
]
},
plugins:[
new MiniCssExtractPlugin({
filename:"[name].[contenthash].css"
})
]
}
index.js内容
import mathFn from "./math.js";
import "./reset.css"
math.js
function add(a,b){
return a + b;
}
function minus(a,b){
return a - b
}
function multiple(a,b){
return a*b
}
export default{
add,
minus,
multiple
}
module_a.js
function moduleA(){
console.log("this is moduleA")
}
moduleA()
module_b.js
function moduleB(){
console.log("this is moduleB")
}
moduleB()
packge.json
{
"name": "webpackDevServer",
"sideEffects": [
"*.css",
".scss"
],
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1",
"dev": "webpack-dev-server --config demo/webpack-dev-server/webpack-dev-server.js",
"server": "node demo/webpack-dev-middleware/server.js",
"hmr": "webpack-dev-server --config demo/HMR/webpack.hmr.js",
"treeShaking:dev": "webpack-dev-server --config demo/tree-shaking/tree-shaking.js",
"treeShaking:build": "webpack --config demo/tree-shaking/tree-shaking.js",
"buildProd:dev": "webpack-dev-server --config demo/buildProduction/webpack.dev.js",
"buildProd:build": "webpack --config demo/buildProduction/webpack.prod.js",
"bundleSplitting":"webpack --config demo/bundleSplitting/webpack.bundleSplitting.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"@babel/core": "7.6.4",
"@babel/plugin-transform-runtime": "^7.6.2",
"@babel/preset-env": "^7.6.3",
"autoprefixer": "^9.7.1",
"babel-loader": "8.0.6",
"clean-webpack-plugin": "3.0.0",
"css-loader": "^3.2.0",
"express": "4.17.1",
"file-loader": "^4.2.0",
"html-webpack-plugin": "3.2.0",
"mini-css-extract-plugin": "^0.8.0",
"node-sass": "^4.13.0",
"postcss-import": "^12.0.1",
"postcss-loader": "^3.0.0",
"postcss-url": "^8.0.0",
"sass-loader": "8.0.0",
"style-loader": "^1.0.0",
"url-loader": "^2.2.0",
"webpack": "4.41.2",
"webpack-cli": "3.3.9",
"webpack-dev-middleware": "3.7.2",
"webpack-dev-server": "3.8.2",
"webpack-merge": "^4.2.2"
}
}
执行 npm run bundleSplitting
结果如下
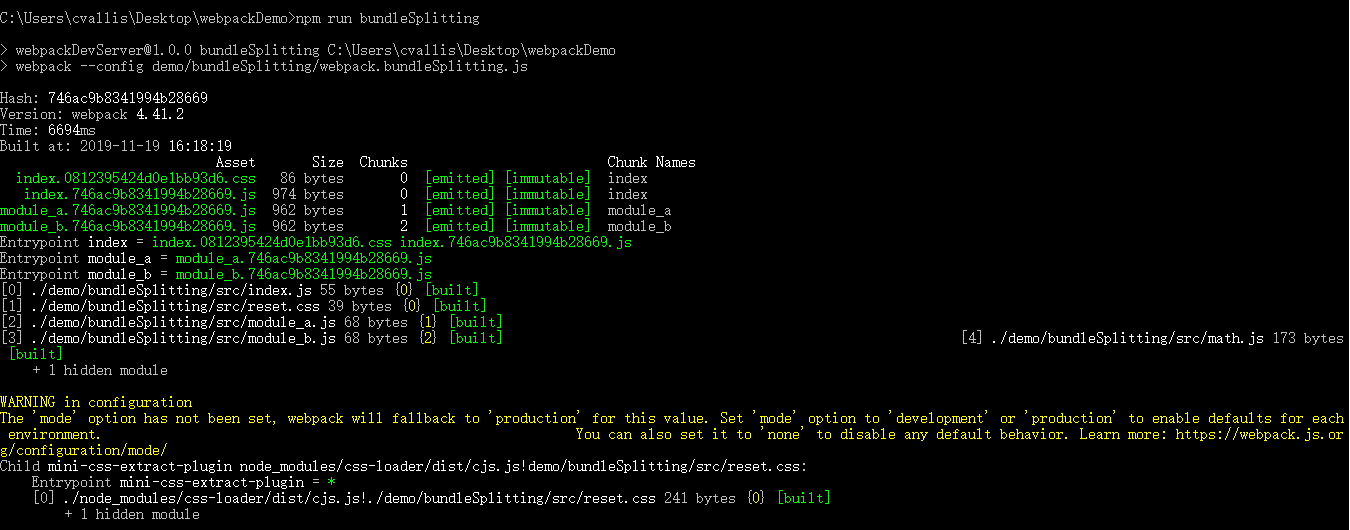
在没有对任何文件修改,在执行npm run bundleSplitting,结果如下
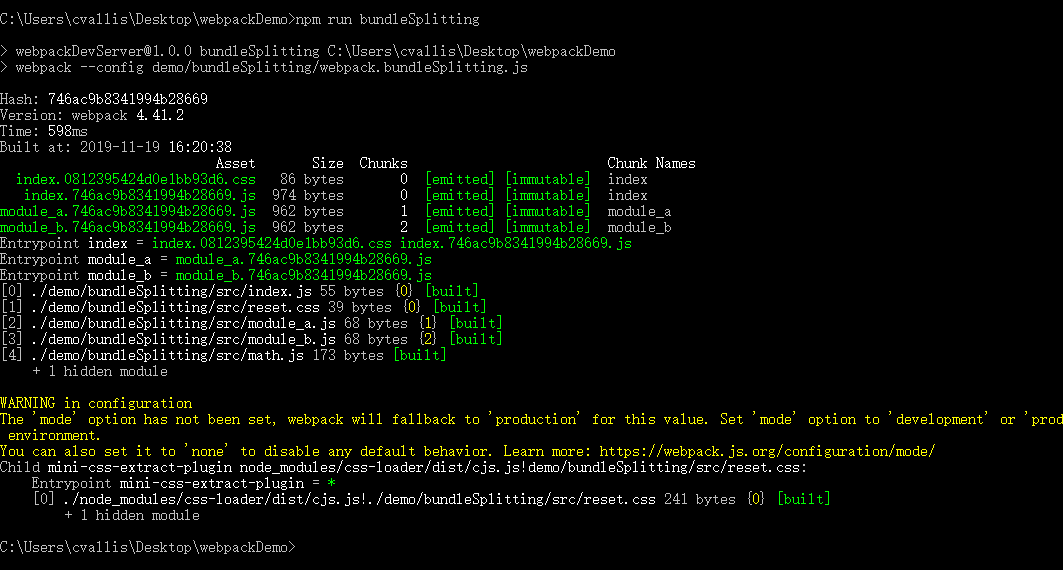
修改module_a.js内容
function moduleA(){
console.log("我是修改了的moduleA")
}
moduleA()
执行npm run bundleSplitting
结果如下
在设置为hash的时候,文件命的hash都是相同的,而且当修改了module_a.js后执行打包,所有文件hash都一起改变
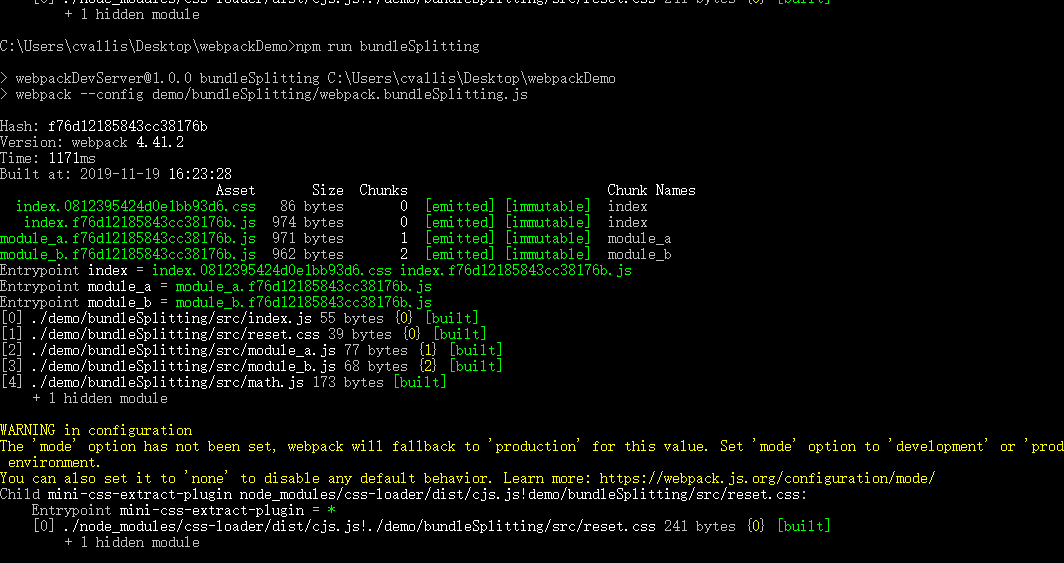
将webpack.bundleSplitting.js的hash改成chunkhash
执行npm run bundleSplitting
结果如下
在没有对任何文件修改,在执行npm run bundleSplitting,结果如下
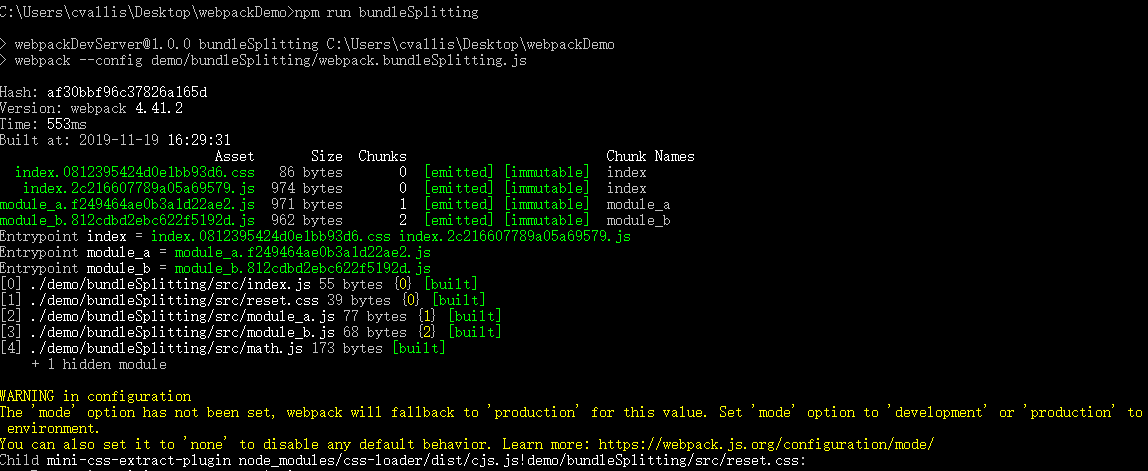
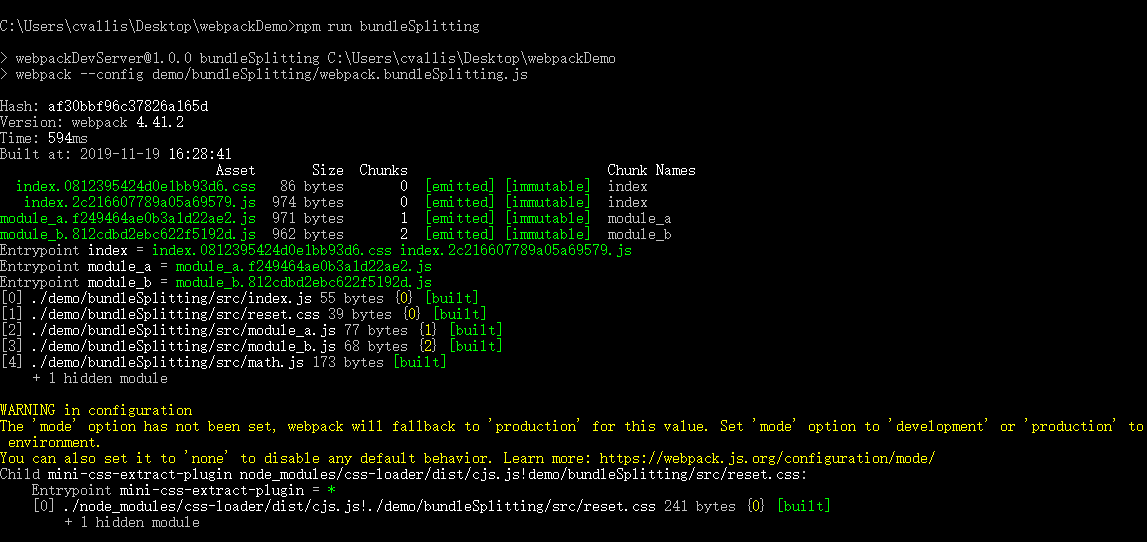
修改module_a.js内容
function moduleA(){
console.log("我是修改成chunkhash的moduleA")
}
moduleA()
执行npm run bundleSplitting
结果如下

在设置为contenthash的时候。文件的contenthash都是不一样的,当修改了module_a.js后执行打包,只有module_a.js的contenthash发生改变
分离第三方类库
让我们把打包文件划分为main.js和vendor.js
很简单,类似于
const path = require("path");
module.exports = {
entry:path.resolve(__dirname,'src/index.js'),
output:{
path:path.resolve(__dirname,'dist'),
filename:'[name].[contenthash].js'
},
optimization:{
splitChunks:{
chunks:"all"
}
}
在webpack4使用了optimization.solitChunks替代了CommonsChunkPlugin
设置optimization.chunks为'all'就是默认打包node_module到venders.js中
设置optimization.chunks.runtimeChunk为true,是讲webpack运行时候生成代码打包到runtime.js中
在实现基本的打包分离条件后,Alice在每次访问时候仍需要下载200KB大小的main.js文件,但是只需要在第一周、第五周、第八周下载200KB vendors.js脚本
| 文件 | week1 | week2 | week3 | week4 | week5 | week6 | week7 | week8 | week9 | week10 |
|---|---|---|---|---|---|---|---|---|---|---|
| main.js | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 |
| vendors.js | 200 | 220 | 220 | |||||||
| totol | 400 | 200 | 200 | 200 | 420 | 200 | 200 | 420 | 200 | 200 |
也就是2.64MB
分离每一个npm包
我们的vendors.js承受着和开始main.js文件同样的问题——部分的修改会意味着重新下载所有的文件,所以为什么不把每一个npm包都分割到单独的文件?做起来非常简单
让我们把react,lodash,redux,moment等分立为不同的文件
const path = require('path');
const webpack = require('webpack');
module.exports = {
entry: path.resolve(__dirname, 'src/index.js'),
plugins: [
new webpack.HashedModuleIdsPlugin(), // so that file hashes don't change unexpectedly
],
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash].js',
},
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'all',
maxInitialRequests: Infinity,
minSize: 0,
cacheGroups: {
vendor: {
test: /[\/]node_modules[\/]/,
name(module) {
// get the name. E.g. node_modules/packageName/not/this/part.js
// or node_modules/packageName
const packageName = module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/)[1];
// npm package names are URL-safe, but some servers don't like @ symbols
return `npm.${packageName.replace('@', '')}`;
},
},
},
},
},
};
这份文档非常好的揭示了这里做的事情,但是我仍然需要解释一下其中精妙的部分
- webpack有一些不那么智能的默认"智能"配置,比如当分离打包输出文件时只允许最多3个文件,并且最小文件的尺寸是30KB(如果存在更小的文件就把它们拼接起来)。所以这里把这些都覆盖了
- cacheGroups使我们用来指定规则告诉webpack应该如何组织chunks到打包输出文件的地方。在这里对所有加载自node_modules里的module指定了一条名为"vendor"的规则。通常
情况下,你只需要为你的输出文件的name定义一个字符串。但是这里把name定义为一个函数(当文件被解析时会被调用)。在函数中会根据module的路径返回包的名称、结果就是,对于每一个包,我
都会得到一个单独的文件 - 为了能够正常发布npm包的名称必须是合法的URL,所以我们不需要encodeURI对包的名词进行转移处理
- 整个步骤的配置设置之后就不需要维护了——我们不需要使用名称引用任何的类库
Alice每周都要重新下载200KB的main.js文件,并且在她首次访问时,仍然需要下载200KB的npm包文件,但是她在也不用重复的下载同一个包两次。