分类模型(分类器)是一种有监督的机器学习模型,其中目标变量是离散的(即类别)。评估一个机器学习模型和建立模型一样重要。我们建立模型的目的是对全新的未见过的数据进行处理,因此,要建立一个鲁棒的模型,就需要对模型进行全面而又深入的评估。当涉及到分类模型时,评估过程变得有些棘手。
在这篇文章中,我会做详细的介绍,说明如何评估一个分类器,包括用于评估模型的一系列不同指标及其优缺点。
我将介绍的概念包括:
-
分类精度(Classification Accuracy)
-
混淆矩阵(Confusion matrix)
-
查准率与查全率(Precision & recall)
-
F1度量(F1 score)
-
敏感性与特异性(Sensitivity & specificity)
-
ROC曲线与AUC(ROC curve & AUC)
分类精度(Classification Accuracy)
分类精度显示了我们所做的预测中有多少是正确的。
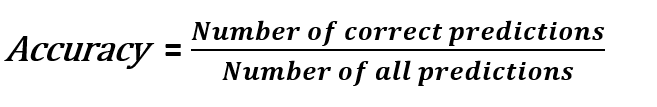
在很多情况下,它表示了一个模型的表现有多好,但在某些情况下,精度是远远不够的。例如,93%的分类精度意味着我们正确预测了100个样本中的93个。在不知道任务细节的情况下,这似乎是可以接受的。
假设我们正在创建一个模型来对不平衡的数据集执行二分类。93%的数据属于A类,而7%属于B类。
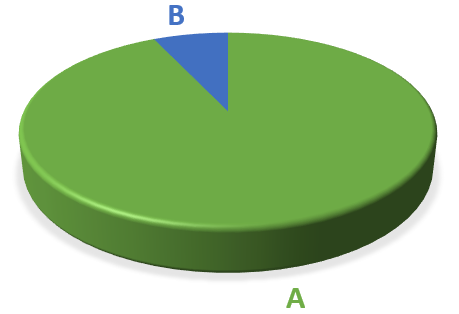
我们有一个只把样本预测为A类的模型,其实我们很难称之为“模型”,因为它只能预测A类,没有任何计算推理。然而,由于93%的样本属于A类,我们的模型的分类精度是93%。
如果正确检测B类至关重要,而且我们无法承受把B类错误地预测为A类的代价(如癌症预测,把癌症病人预测为正常人的后果是不可想象的),该怎么办?在这些情况下,我们需要其他指标来评估我们的模型。
混淆矩阵(Confusion Matrix)
混淆矩阵不是评估模型的一种数值指标,但它可以让我们对分类器的预测结果有深刻的理解。学习混淆矩阵对于理解其他分类指标如查准率和查全率是很重要的。
相比分类精度,混淆矩阵的使用意味着我们在评估模型的道路上迈出了更深的一步路。混淆矩阵显示了对每一类的预测分别是正确还是错误。对于二分类任务,混淆矩阵是2x2矩阵。如果有三个不同的类,它就是3x3矩阵,以此类推。
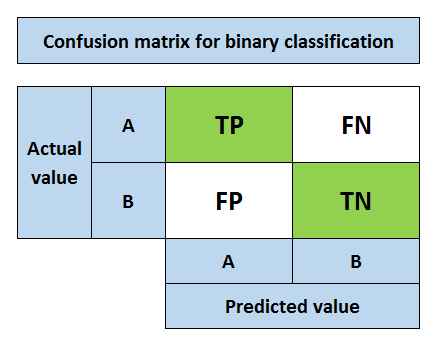
假设A类是正类,B类是反类。与混淆矩阵相关的关键术语如下:
-
真阳性(TP):把正类预测为正类(没问题)
-
假阳性(FP):把负类预测为正类(不好)
-
假阴性(FN):把正类预测为负类(不好)
-
真阴性(TN):把负类预测为负类(没问题)
我们期望的结果是我们的预测能够与真实类别相匹配。这些术语看起来有些让人头晕眼花,但是你可以想一些小技巧来帮助你记住它们。我的诀窍如下:
第二个字表示模型的预测结果
第一个字表示模型的预测是否正确
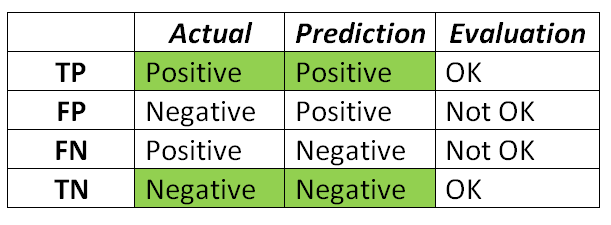
假阳性也称为I类错误,假阴性也称为II型错误。
混淆矩阵的用途是计算查准率和查全率。
完整文章请查看原文或关注公众号
原文地址:https://imba.deephub.ai/p/a5768cf073bb11ea90cd05de3860c663
