1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
(1)通过正则化来防止过拟合
(2)如图,过拟合后,得到的方程很拟合训练的数据,但是用测试集去测试时,则可能认为其不是那一类的,以至于无法预测新样本的标签。
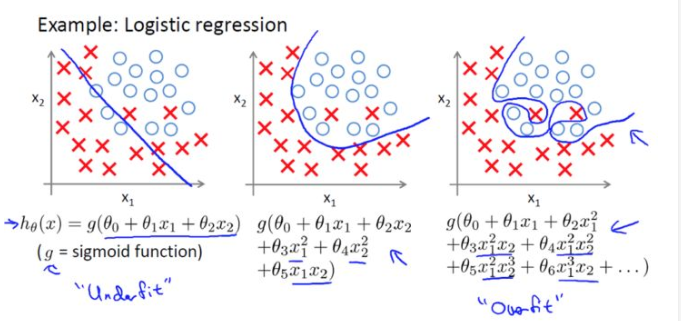
保留所有的特征变量,但是减少特征变量的数量级。
假设我们使θ6,θ7.......,θn很小,那么参数x的影响就会很小,这时过拟合的公式结果就很接近好的情况。
正则化是控制模型空间的一种办法,通过收缩,限制模型变得越来越大,牺牲样本内误差,降低模型的误差。
2.用logistic回归来进行实践操作,数据不限。
从阿里云-天池-数据集里面拿到的信用卡评估数据(https://tianchi.aliyun.com/dataset/dataDetail?dataId=60269)
需要导入以下库:
from sklearn.linear_model import LogisticRegression #从机器学习中导入逻辑回归 from sklearn.model_selection import train_test_split #拆分为训练集合测试集 from sklearn.preprocessing import StandardScaler #标准化 from sklearn.metrics import classification_report #可以得到召回率 import matplotlib.pyplot as plt #画图 import pandas as pd import numpy as np
然后读取数据并且进行清洗:


data = pd.read_csv("./机器学习/credit.csv", engine="python")# 读取数据 data = data.iloc[:, 1:] # 删去第一列 data.describe().T # 统计学描述 # 从统计性描述可以看到,数据中有空值,好坏用户即用户的信用好坏,平均值为0.06,所以为0时,用户信用好,为1是用户信用不好 data.isnull().sum() # 查看每列的空值数 # 数据清洗ing # 满了18岁才可以贷款,所以查看是否有18岁以下的贷款用户,若有则删除 data[data['贷款时年龄'] < 18] data = data[data['贷款时年龄'] > 18] data['月收入'] = data['月收入'].fillna(data['月收入'].mean()) data['受抚养人数'] = data['受抚养人数'].fillna(0) data.describe().T data = data.drop_duplicates() # 删除重复项 # 利用点图可以查看每个数据有无异常数据,然后进行清洗 # plt.scatter(data['60-89天逾期次数'],data['60-89天逾期次数']) data = data[data['30-59天逾期次数'] < 6] data = data[data['负债率'] < 1] data = data[data['月收入'] < 500000] data = data[data['抵押贷款和不动产贷款数量'] < 20] data = data[data['60-89天逾期次数'] < 8] data = data[data['受抚养人数'] < 8] plt.bar([1, 0], [sum(data['好坏用户'] == 1), sum(data['好坏用户'] == 0)])
接下来进行数据集的拆分:
# 拆分数据集 x = data.iloc[:, 0:10] y = data.iloc[:, -1] x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2) # 拆分数据集 # 标准化处理 std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.transform(x_test)
数据集准备好了以后,进行模型的建立、训练、预测:
# 逻辑回归模型的建立、训练、预测 lg_model = LogisticRegression() lg_model.fit(x_train, y_train) y_pre = lg_model.predict(x_test)
最后进行模型的评估:
train_score = lg_model.score(x_train, y_train) test_score = lg_model.score(x_test, y_test) print("训练数据集的准确率:", train_score, "测试数据集的准确率:", test_score) print("召回率:", classification_report(y_test, y_pre)) print("测试样本中预测正确的个数: {0}/{1}".format(np.equal(y_pre, y_test).sum(), y_test.shape[0]))
