MySQL的SELECT语法的执行顺序和Oracle的基本相同,只是增加了MySQL独有的LIMIT语法。
目录
一、SELECT语句的处理过程
1. FROM阶段
2. WHERE阶段
3. GROUP BY阶段
4. HAVING阶段
5. SELECT阶段
6. ORDER BY阶段
7. LIMIT阶段
一、SELECT语句的处理过程
查询操作是关系数据库中使用最为频繁的操作,也是构成其他SQL语句(如DELETE、UPDATE)的基础。
我们知道,SQL 查询的大致语法结构如下:
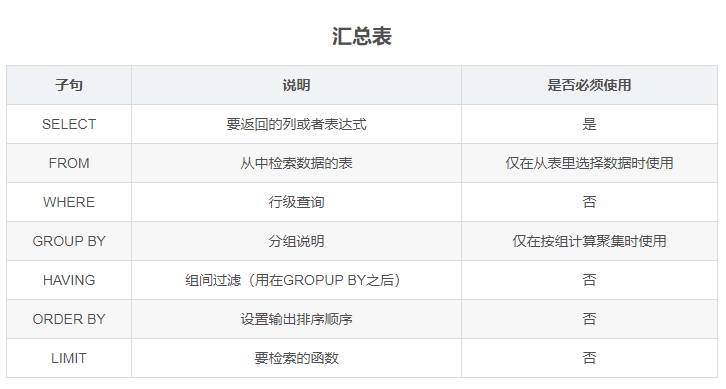
(0)SELECT DISTINCT <select_list> (1)FROM <left_table> <join_type> JOIN <right_table> ON <on_predicate> (2)WHERE <where_predicate> (3)GROUP BY <group_by_specification> (4)HAVING <having_predicate> (6)ORDER BY <order_by_list>
(7)LIMIT n, m
查询处理的顺序如下:
- FROM
- ON
- JOIN
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- LIMIT
这些步骤执行时,每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只是最后一步生成的表才会返回给调用者。如果没有在查询中指定某一子句,将跳过相应的步骤。
SELECT各个阶段分别干了什么:
1. FROM阶段
FROM阶段标识出查询的来源表,并处理表运算符。在涉及到联接运算的查询中(各种JOIN),主要有以下几个步骤:
- 求笛卡尔积。不论是什么类型的联接运算,首先都是执行交叉连接(CROSS JOIN),求笛卡儿积(Cartesian product),生成虚拟表VT1-J1。
- ON筛选器。 这个阶段对上个步骤生成的VT1-J1进行筛选,根据ON子句中出现的谓词进行筛选,让谓词取值为true的行通过了考验,插入到VT1-J2。
- 添加外部行。如果指定了OUTER JOIN,如LEFT OUTERJOIN、RIGHT OUTER JOIN),还需要将VT1-J2中没有找到匹配的行,作为外部行添加到VT1-J2中,生成VT1-J3。如果FROM子句包含两个以上表,则对上一个连接生成的结果表VT1-J3和下一个表重复依次执行3个步骤,直到处理完所有的表为止。
经过以上步骤,FROM阶段就完成了。
2. WHERE阶段
WHERE阶段是根据<where_predicate>中条件对VT1中的行进行筛选,让条件成立的行才会插入到VT2中。此时数据还没有分组,所以不能在WHERE中出现对统计的过滤。
3. GROUP BY阶段
GROUP阶段按照指定的列名列表,将VT2中的行进行分组,生成VT3。最后每个分组只有一行。在GROUP BY阶段,数据库认为两个NULL值是相等的,因此会将NULL值分到同一个分组中。
4. HAVING阶段
该阶段根据HAVING子句中出现的谓词对VT3的分组进行筛选,并将符合条件的组插入到VT4中。COUNT(expr) 会返回expr不为NULL的行数,count(1)、count(*)会返回包括NULL值在内的所有数量。
5. SELECT阶段
这个阶段是投影的过程,处理SELECT子句提到的元素,产生VT5。这个步骤一般按下列顺序进行:
- 计算SELECT列表中的表达式,生成VT5-1。
- 若有DISTINCT,则删除VT5-1中的重复行,生成VT5-2。
6. ORDER BY阶段
根据ORDER BY子句中指定的列明列表,对VT5-2中的行,进行排序,生成VT6。如果不指定排序,数据并非总是按照主键顺序进行排序的。NULL被视为最小值。
7. LIMIT阶段
取出指定行的记录,产生虚拟表VT7,并返回给查询用户。LIMIT n, m的效率是十分低的,一般可以通过在WHERE条件中指定范围来优化 WHERE id > ? limit 10。