
从Google Visor到Microsoft NNI再到Advisor调参服务接口发展史
从规则编程到机器学习,从人工调参到AutoML(meta-machine learning),一直是整个行业发展的趋势。目前各种黑盒优化算法、增强学习算法也越来越得到工业界接受,最著名的当属来自DeepMind的AlphaGo和AlphaZero。我们都知道AlphaZero用了基于蒙特卡罗树搜索的增强学习架构来实现自我提升,但一个模型有数以千计的超参数需要调优,其背后就是基于大规模的GPU训练集群以及启发式的贝叶斯优化算法。BayesianOptimization是目前最流行的黑盒优化算法,也就是说适用于任何函数、模型或者框架,相比与RL需要样本量小很多,基于联合高斯分布的前提数理上保证收敛,除此之外还有Grid search、Random search、TPE、PSO、SMAC等主流调参算法。
调参算法是成熟而公开的,但不是所有开发者都需要掌握其实现,例如BayesianOptimization的实现就需要包含了Gaussian process的计算以及Acquisition function的选择,就像大家都在用sgd/adam/adagrad/ftrl优化器也可以不了解其更新逻辑。因此各种实现黑盒优化算法的调参类库以及调参服务应用而生,这里主要区分Library以及Service因为其使用接口区别很大,本文就将以Google Vizier、Microsoft NNI和Advisor为例介绍这些调参框架的设计和实现。
下面列举其他非常不错、值得参考的开源调参框架:
- Distributed Asynchronous Hyperparameter Optimization in Python hyperopt/hyperopt
- A fully decentralized hyperparameter optimization framework AIworx-Labs/chocolate
- Hyperparameter Optimization for Keras Models autonomio/talos
- AutoML library for building modular, reusable, strongly typed machine learning workflows on Spark salesforce/TransmogrifAI
- hyperparameter_hunter HunterMcGushion/hyperparameter_hunter
- Milano is a tool for automating hyper-parameters search for your models on a backend of your choice https://github.com/NVIDIA/Milano
- Repository for hyperparameter tuning kubeflow/katib
- AMLA: an AutoML frAmework for Neural Networks CiscoAI/amla
- Ray Tune https://ray.readthedocs.io/en/latest/tune.html
Google Vizier
我最早接触自动调参是从Google CloudML的功能列表中了解到的,直到看到Vizier的论文全文才了解到其背后的实现,论文地址 https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46180.pdf 。简单来说,Google CloudML提供了一个云端训练模型和自动调参的功能,用户把Python代码上传上去,定义一个HyperparameterSpec,云平台就会使用调参算法并行训练并且选择效果最优的超参组合和模型,幕后功臣则是Google内部的Vizier服务。在Google内部,Vizier不仅提供调参服务给Google Cloud的服务,面向跟底层还提供了批量获取推荐超参、批量更新模型结果、更新和调试调参算法以及Web控制台等功能,因此内部Vizier服务才展示了最完整的调参服务概况。
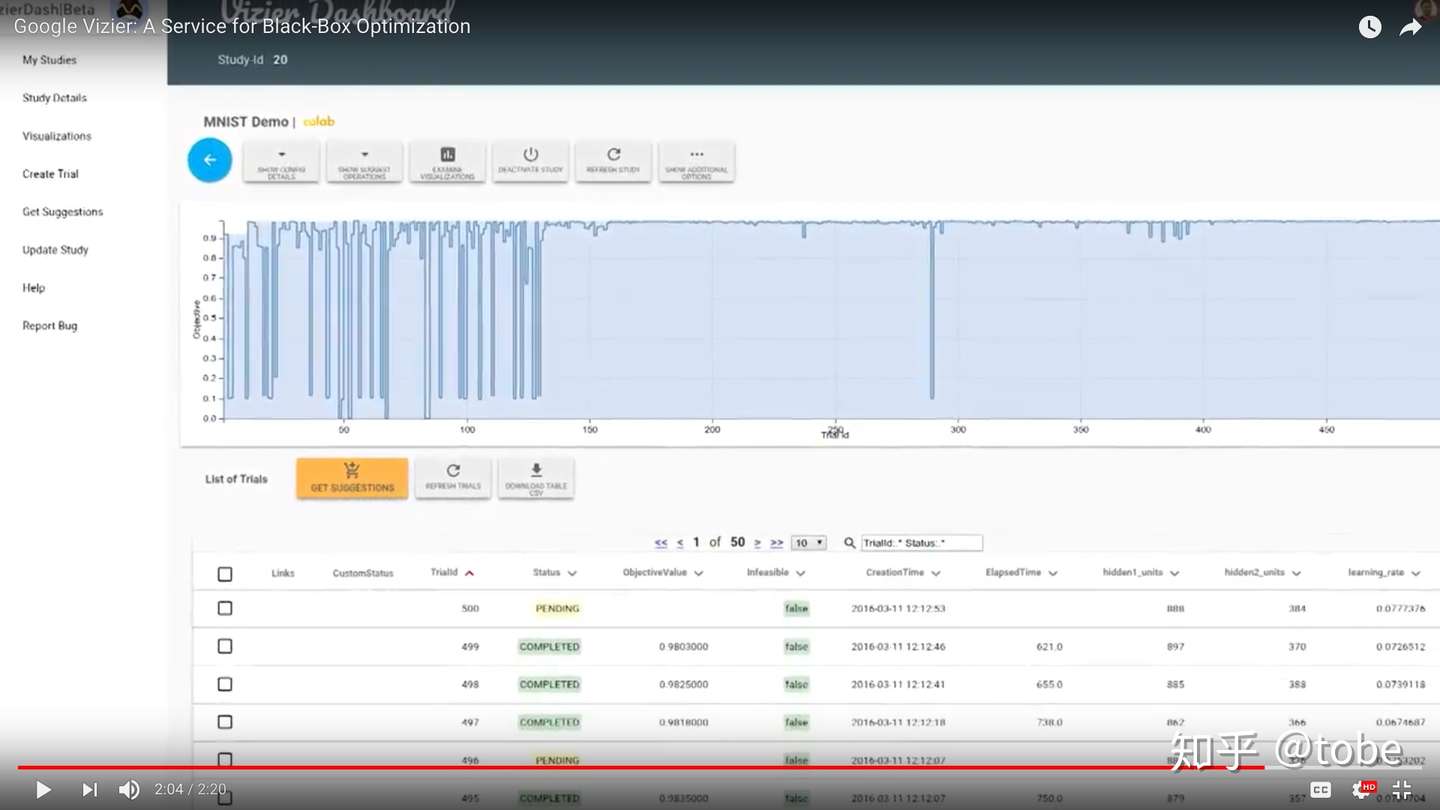
从前面提到的分类方式来讲,Google Vizier属于Service,也就是说所有的算法和逻辑实现都在后端,客户端只能通过API或SDK来访问服务。这样做的好处非常多,例如后端有新算法的更新不需要去升级使用者代码,后端实现高可用比客户端维护状态更安全,后端算法计算不需要占用模型训练者资源,当然还有最重要的一个原因,就是后端服务可以收数据。作为业界最领先的用增强学习和迁移学习来下围棋和为机房省电的企业,Google用自动调参服务的数据来调优自动调参服务当然就在情理之中了,如果机器学习就是基于数据的meta-learning,那么调超参的服务就是meta-meta-learning,那么“调”调超参服务的这个服务就是meta-meta-meta-learning了。实际上Google Vizier也做不到所有超参或者超参的超参都由机器来学习调整,但他们确实从历史调参数据中用迁移学习解决了算法冷启动问题,目前即使是贝叶斯优化也存在冷启动问题,也就是说有一定量样本后才可以开始启发式地调优,如果没有样本数据只能先Random search几把才用贝叶斯优化,Google Vizier论文则提到通过对搜索空间的变换可以复用历史推荐样本,感兴趣可以一起探讨下细节。
当然,看似美好的接口设计也存在不足,最大的问题就是难用,或者说需要改代码才能用。这是所有调参框架都要面对的问题之一,因为框架需要保证用户的模型用上了推荐的超参数,而且需要收集用户模型的指标以便于后续超参的推荐,因此用户代码至少需要加两个接口getParameters()和outputMetrics()。前面提到Google CloudML只需要定义一个HyperparameterSpec就可以了,实际上你的模型代码也要改,首先是通过tf.FLAGS或者argparse等参数的方式获取Vizier提供的超参,然后使用TensorBoard event file或者Estimator add metrics把模型的指标回报给Vizier。使用Google CloudML的话只要按照 https://cloud.google.com/ml-engine/docs/tensorflow/using-hyperparameter-tuning 这个文档的规范编码就可以了,但开发者更多时候要在本地调试代码而且也不一定非要用TensorFlow来建模,这样Google CloudML就很难支持了。
当然Google Vizier在内部提供了更底层的API,例如可以CRUD各种资源,如Study、Trial、Metrics等,甚至可以在Algorithm Playground中添加自己实现的黑盒调优算法。由于Google Vizier没有开源,具体的API接口不得而知,但从我们实现的开源版Vizier发现,提供Study/Trial/Metrics接口其实并不易用,而且对用户代码侵入较大,易用性远不如基于Library的hyperopt、chocolate等框架好用。
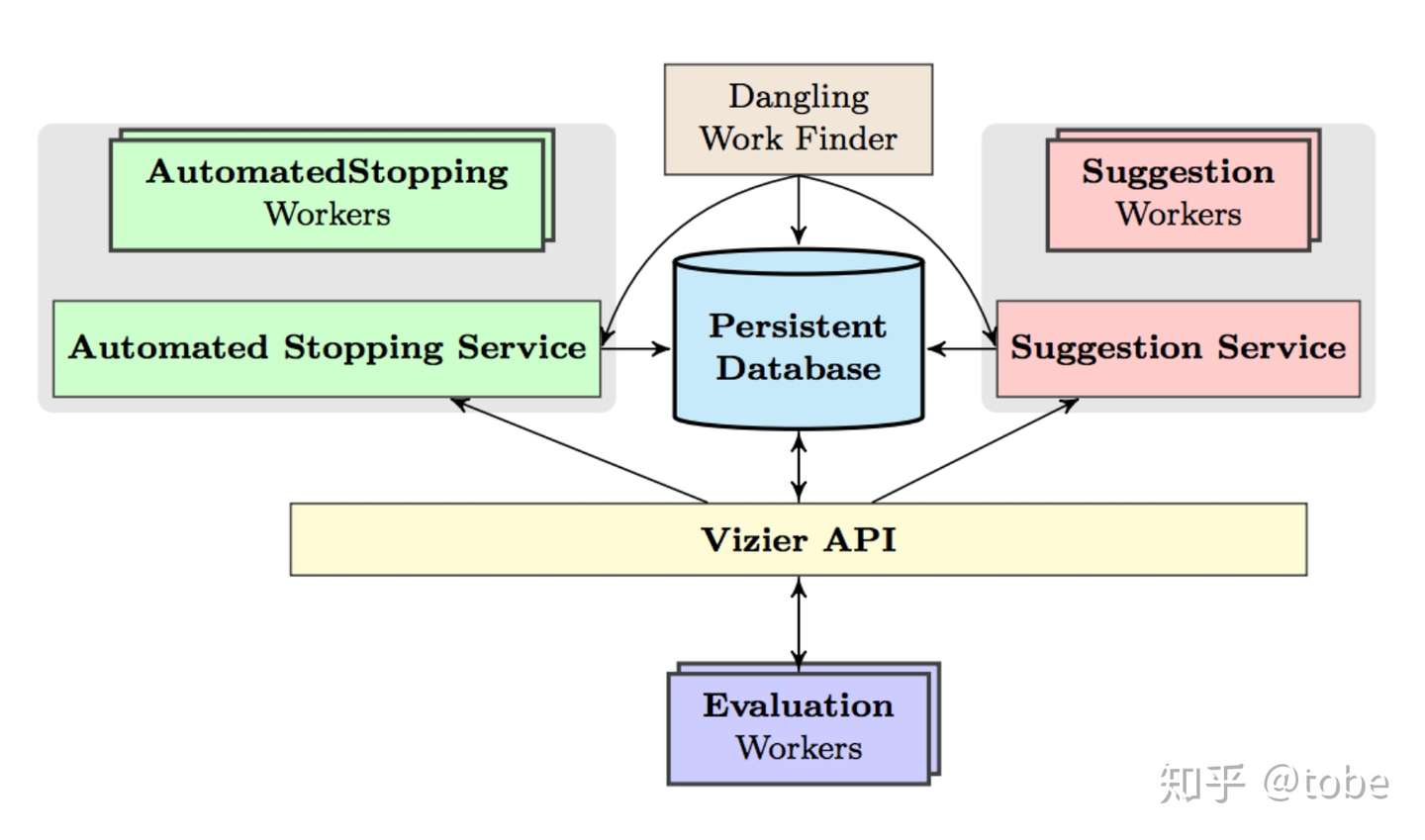
上图是Google Vizier的整体架构,看图其实也基本了解其实现了,有定义调参服务的接口API,包括Search sapce的格式规范和支持的类型,还有数据库进行数据持久化,两边是可扩展、可插拔的Suggestion算法和Early stopping算法。通过对API的封装实现了一个HyperTune subsystem,也就是Google CloudML产品中的自动调参功能。
Microsoft NNI
说完Google的调参服务,我们来看看业界另一大标杆巨硬公司的产品,NNI(Neural Network Intelligence)是Microsoft近期开源的调参工具包,项目地址 Microsoft/nni 。从名字和官方教程可以看出,NNI相比于Vizier其实是一个Library,也就是说算法是运行在客户端本地的,当然NNI也提供了远程运行训练任务的功能,运行NNI的机器相当于算法控制器。
NNI与Hyperopt类似(实际上NNI内置的TPE算法就是用的hyperopt),使用体验上要比Vizier好不少,同样地用户需要定义Search space和修改代码来获取参数、导出Metrics结果,但提供了一个运行配置,可以像本地命令行一样执行模型训练代码,不论用户使用TensorFlow还是CNTK等任意框架,下面是官方提供的使用流程图。

如果深入看NNI源码,本体是Python实现的命令行工具,和大部分调参Library实现类似,亮点是可以集成其他类库的调参算法,因此借此可以介绍下一般通用调参框架的架构实现。
首先,所有调参服务都有自定义的Search space格式规范,为什么不能有统一的规范让所有框架去实现?是因为不同框架实现的处理方式有区别,例如Google Vizier支持了INTEGER、DOUBLE、DISCRETE、CATEGORICAL这几种类型描述,而Microsoft NNI因为兼容hyperopt算法,开源类库chocolate也有相似的定义,支持的都是类似hyperopt.hp.uniform()、hyperopt.hp.choice()的超参描述。虽然框架不同,但Search space基本都可以用JSON来表达,对于Service类型调参框架因为只能通过API请求,因此必须是标准的JSON数据,不能包含Python SDK函数,而Library类型调参框架可以像Hyperopt用函数来表示,也可以像NNI用标准JSON数据格式来表示。如果我们去取所有框架搜索空间类型的子集,理论上所有框架的算法都可以互通互用,在后面要提到的Advisor调参服务上,我们也是参考NNI实现了对Hyperopt的TPE、Random search、Simulate anneal算法以及Chocolate的Quasi random search、Random search、Grid search、Bayes search、CMAES、MOCMAES算法集成。
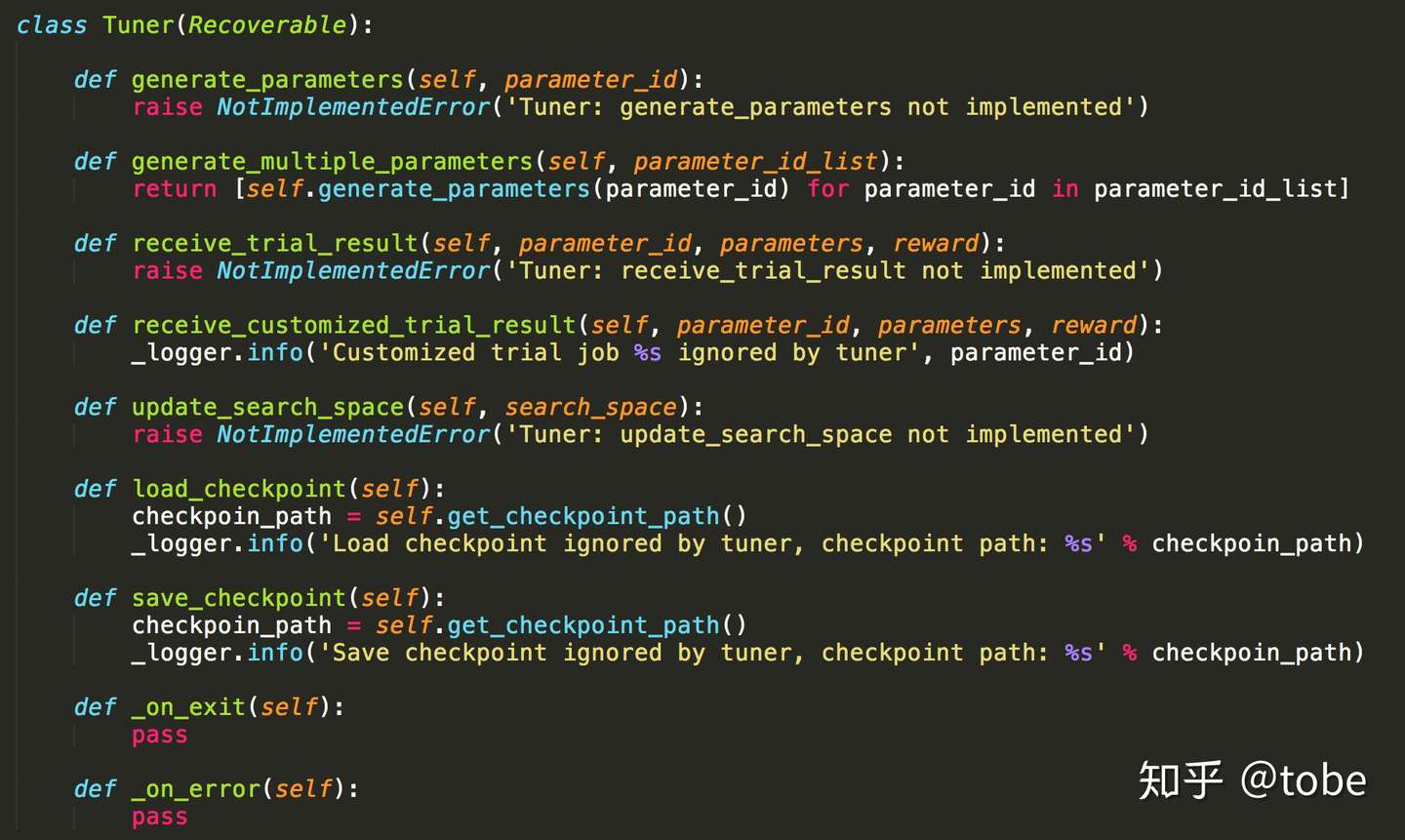
第二步就是调参算法的实现,在NNI中除了前面提到的Hyperopt TPE算法,底层实现了Evolution tuner也就是进化算法。对于这类算法的实现,主要是要实现一个generate_parameters()接口,当然好的算法需要根据历史的训练数据来“启发式”推荐参数,因此NNI也提供一个receive_trial_result()接口,算法可以根据用户模型的结果动态更新调参算法本身的参数。下面是Microsoft NNI各种调参算法实现的基类接口。
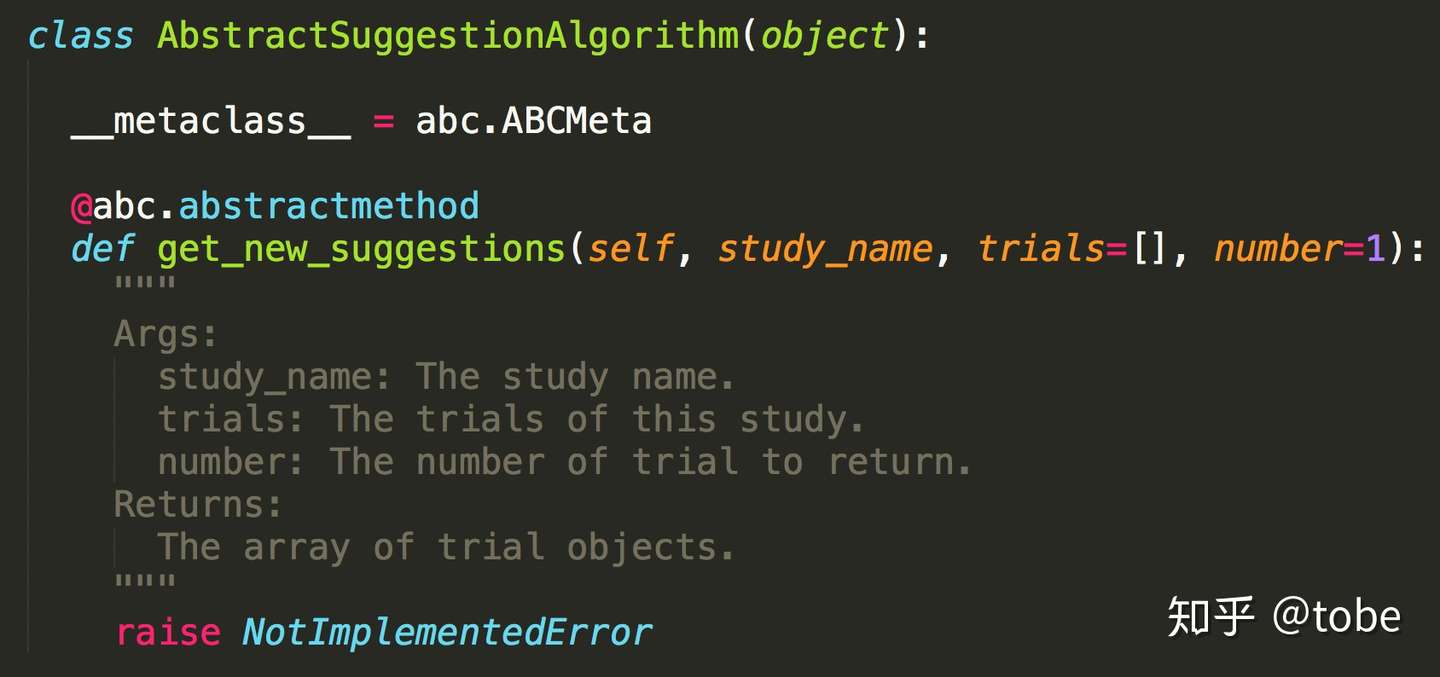
在Advisor项目中,我们的算法定义就更加简洁了,当然从极致的性能角度考虑,Library类型框架可以把调参对象放在内存中维护,生成超参不需要重新加载历史结果因此效率更高,不过调参服务性能不会是调参瓶颈因此一般可以不考虑。
最后就是定义调参的API和SDK,这也是直接影响使用者体验和应用场景的关键。前面提到Google Vizier目前只能在Google CloudML中使用,因此只能优化TensorFlow模型的超参,而NNI提供了pynni的Python SDK,因此只要是Python应用都可以使用,也就是几乎所有的机器学习建模脚本(CNTK、TensorFlow、PyTroch、MXNet等等)都可以应用。而且相比于纯SDK的接入方式,NNI还提供一个命令行工具nnictl,用户可以写一个配置文件,然后使用nnictl来启动训练和调参任务,而且通过拓展NNI的TrainingServicePlatform,目前支持把任务运行在local和remote,实现上也不复杂使用了TypeScript的ssh库,当然未来很容易可以拓展让任务运行在Kubernetes、Mesos、Yarn等分布式平台上。除了NNI这类使用方式,还有更机制的调参框架集成,例如针对Scikit-learn封装Hyperopt而成的hyperopt-sklearn,只要简单替换Scikit-learn中的Estimator对象就可以实现全自动的多任务调参过程,这种封装在已经实现了调参核心算法和逻辑的框架上就非常好实现了。
Advisor
看完Google Vizier和Microsoft NNI服务的架构,其实最想重点介绍的是Advisor,一个基于Vizier论文实现的调参服务,同时也集成了NNI的接口使用特点,当然还有最流行的BayesianOptimization等算法实现,开源地址 tobegit3hub/advisor 。

如果想了解Advisor的架构特点和领域抽象,可以直接参考Vizier论文,因为里面定义的Study、Trial、TrialMetrics都与Vizier一致(好的抽象很重要!),甚至Search space的配置也保持与Vizier兼容,而选择Service的实现方式有助于未来迁移学习的算法实现。在Vizier的架构基础上,我们可以摆脱对TensorFlow的绑定,提供无侵入的使用体验。前面提到使用所有调参框架都必须修改代码调用getParameters()和outputMetrics()接口,所谓“无侵入”只能通过约定的方式实现,参考Google CloudML我们可以把超参作为命令行参数传入,这样与用户在本地命令行调试模型的体验一致,而回报模型指标只需要用户在stdout最后一行打印Metrics即可,这比NNI必须依赖SDK来获取参数和回报指标跟进一步。
下面是使用Scikit-learn进行MNIST模型训练的一个例子,这个代码逻辑可以由开发者在命令行通过调参来观察模型效果进而选择最优的超参,同样也可以直接使用Advisor进行自动的分布式的调参。
import argparse
from sklearn import datasets, svm, metrics
parser = argparse.ArgumentParser()
parser.add_argument("-gamma", type=float, default=0.001)
parser.add_argument("-C", type=float, default=0.5)
parser.add_argument("-kernel", type=str, default="sigmoid")
parser.add_argument("-coef0", type=float, default=0.1)
args = parser.parse_args()
def main():
digits = datasets.load_digits()
images_and_labels = list(zip(digits.images, digits.target))
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
classifier = svm.SVC(
gamma=args.gamma, C=args.C, kernel=args.kernel, coef0=args.coef0)
classifier.fit(data[:n_samples // 2], digits.target[:n_samples // 2])
expected = digits.target[n_samples // 2:]
predicted = classifier.predict(data[n_samples // 2:])
accuracy = metrics.accuracy_score(expected, predicted)
print(accuracy)
if __name__ == "__main__":
main()对于Adhoc的Python函数,在我们不知道函数是否可导或者有极值的情况下,我们也可以用Advisor来计算(算力越大效果越好),不同场景也可以选用BO、RS、GS、TPE、PSO等对应的调参算法,是真正的黑盒优化,甚至是不同编程语言实现的机器学习框架也原生支持。
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("-x", type=float, default=0.0)
args = parser.parse_args()
def main():
# Read parameters
x = args.x
# Compute or learning
y = x * x - 2 * x + 1
print("Formula: {}, input: {}, output: {}".format("y = x * x - 2 * x + 1", x, y))
# Output the metrics
print(y)
if __name__ == "__main__":
main()这里介绍下使用Advisor的调参全流程,安装是很简单的可以使用“pip install advisor-clients”,启动Server服务端方式有多种,使用内置的脚本、Docker容器、docker-compose或者是Kubernetes集群。
advisor_admin server start
docker run -d -p 8000:8000 tobegit3hub/advisor
docker-compose up -d
kubectl create -f ./kubernetes_advisor.yaml
然后编写你的模型训练代码,由于“无侵入”的约定用户不需要再引入任务与模型无关的代码,例如不需要"import advsior_client",直接用前面的Scikit-learn代码以及原生Python脚本即可。到目前为止我们还没有定义Search space,实际上这是调参应用所必须定义的,也就是创建Vizier中的Stduy或者是NNI中的Experiment,这个我们参考NNI用法提供了JSON配置文件,用户可以在文件中指定Search space、调优算法、启动目录、启动脚本等系列参数。
{
"name": "demo",
"algorithm": "BayesianOptimization",
"trialNumber": 10,
"concurrency": 1,
"path": "./advisor_client/examples/python_function/",
"command": "./min_function.py",
"search_space": {
"goal": "MINIMIZE",
"randomInitTrials": 3,
"params": [
{
"parameterName": "x",
"type": "DOUBLE",
"minValue": -10.0,
"maxValue": 10.0,
"scalingType": "LINEAR"
}
]
}
}最后命令行运行即可,启动后可以看到终端打印的调试信息以及推荐的参数,使用BayesianOptimization设置可以看到样本越多推荐的结果越接近最优解,当然这个配置Aquisition function的expolration和exploitation来控制,这里就不赘叙了。
advisor run -f ./advisor_client/examples/python_function/config.json
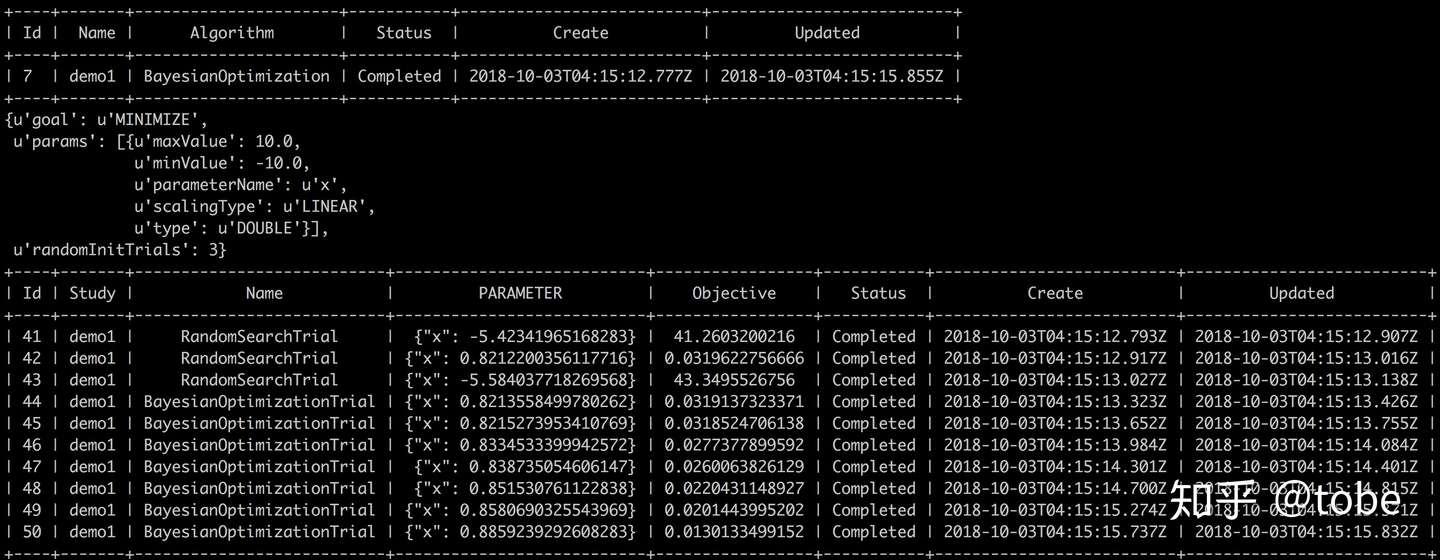
考虑到用户还有其他方式训练模型的可能,Advisor API和SDK还有批量导入Trial、TrialMetrics等功能,这样就可以集成不用Advisor训练的历史结果提高贝叶斯优化效果,而不需要像hyperopt那样手动插入数据到SQLite(后续单开文章介绍hyperopt的源码和集成TPE算法的方法)。算法拓展也非常容易,除了可以使用已经集成的八种算法,只要编写一个Python文件实现get_new_suggestions(self, study_name, trials=[], number=1)接口即加入自己的算法,所有算法实现都有对应的单元测试,感兴趣可以阅读源码了解 tobegit3hub/advisor 。未来考虑提供TensorFlow/Keras/Scikit-learn/XGBoost Estimator的wrapper,为Kaggle比赛的自动调参提供极致的体验。
总结
最后总结一下,目前自动调参服务正所谓百花齐放,Microsoft、Nvidia、Salesforce都有对应的开源产品,而Spark、Ray和Kubernetes也有高度集成的功能模块,但所有调参框架都存在接口格式不统一,代码侵入性较大的问题。
希望通过本文大家可以了解业界主流的黑合优化框架的架构设计和实现原理,对比Google Vizier、Microsoft NNI以及Advisor的接口设计进程,实现代码“无侵入”的调参服务,同时也欢迎大家来使用和改进Advisor,任何Issue和PR都是非常有价值的。最近(2018年10月1日)我们就收到3个来自不同地区的Pull-request,开发者分别来自法国雷恩、巴西圣保罗以及瑞士,虽然都是小改动但也是十分appreciated的。
黑盒优化作为AutoML、NAS的基础,meta-learning中的meta,相信未来必然有更广的应用场景!
贝叶斯优化: 一种更好的超参数调优方式
简介
本文受 浅析 Hinton 最近提出的 Capsule 计划 启发,希望以更通俗的方式推广机器学习算法,让有数学基础和编程能力的人能够乐享其中。
目前人工智能和深度学习越趋普及,大家可以使用开源的Scikit-learn、TensorFlow来实现机器学习模型,甚至参加Kaggle这样的建模比赛。那么要想模型效果好,手动调参少不了,机器学习算法如SVM就有gamma、kernel、ceof等超参数要调,而神经网络模型有learning_rate、optimizer、L1/L2 normalization等更多超参数可以调优。
很多paper使用一个新的模型可以取得state of the art的效果,然后提供一组超参数组合方便读者复现效果,实际上这些超参数都是“精挑细选”得到的,背后有太多效果不好的超参数尝试过程被忽略,大家也不知道对方的超参数是如何tune出来的。因此,了解和掌握更好的超参数调优方法在科研和工程上是很有价值的,本文将介绍一种更好的超参数调优方式,也就是贝叶斯优化(Bayesian Optimization),以及开源调参服务Advisor的使用介绍。
超参数介绍
首先,什么是超参数(Hyper-parameter)?这是相对于模型的参数而言(Parameter),我们知道机器学习其实就是机器通过某种算法学习数据的计算过程,通过学习得到的模型本质上是一些列数字,如树模型每个节点上判断属于左右子树的一个数,或者逻辑回归模型里的一维数组,这些都称为模型的参数。
那么定义模型属性或者定义训练过程的参数,我们称为超参数,例如我们定义一个神经网络模型有9527层网络并且都用RELU作为激活函数,这个9527层和RELU激活函数就是一组超参数,又例如我们定义这个模型使用RMSProp优化算法和learning rate为0.01,那么这两个控制训练过程的属性也是超参数。
显然,超参数的选择对模型最终的效果有极大的影响。如复杂的模型可能有更好的表达能力来处理不同类别的数据,但也可能因为层数太多导致梯度消失无法训练,又如learning rate过大可能导致收敛效果差,过小又可能收敛速度过慢。
那么如何选择合适的超参数呢,不同模型会有不同的最优超参数组合,找到这组最优超参数大家会根据经验、或者随机的方法来尝试,这也是为什么现在的深度学习工程师也被戏称为“调参工程师”。根据No Free Lunch原理,不存在一组完美的超参数适合所有模型,那么调参看起来是一个工程问题,有可能用数学或者机器学习模型来解决模型本身超参数的选择问题吗?答案显然是有的,而且通过一些数学证明,我们使用算法“很有可能”取得比常用方法更好的效果,为什么是“很有可能”,因为这里没有绝对只有概率分布,也就是后面会介绍到的贝叶斯优化。
自动调参算法
说到自动调参算法,大家可能已经知道了Grid search(网格搜索)、Random search(随机搜索),还有Genetic algorithm(遗传算法)、Paticle Swarm Optimization(粒子群优化)、Bayesian Optimization(贝叶斯优化)、TPE、SMAC等。
这里补充一个背景,机器学习模型超参数调优一般认为是一个黑盒优化问题,所谓黑盒问题就是我们在调优的过程中只看到模型的输入和输出,不能获取模型训练过程的梯度信息,也不能假设模型超参数和最终指标符合凸优化条件,否则的话我们通过求导或者凸优化方法就可以求导最优解,不需要使用这些黑盒优化算法,而实际上大部分的模型超参数也符合这个场景。其次是模型的训练过程是相对expensive的,不能通过快速计算获取大量样本,我们知道DeepMind用增强学习模型DQN来打Atari游戏,实际上每一个action操作后都能迅速取得当前的score,这样收集到大量样本才可以训练复杂的神经网络模型,虽说我们也可以用增强学习来训练超参数调优的模型,但实际上一组超参数要训练一个模型需要几分钟、几小时、几天甚至几个月的时间,无法快速获取这么多样本数据,因此需要有更“准确和高效”的方法来调优超参数。
像遗传算法和PSO这些经典黑盒优化算法,我归类为群体优化算法,也不是特别适合模型超参数调优场景,因为需要有足够多的初始样本点,并且优化效率不是特别高,本文也不再详细叙述。
目前业界用得比较多的分别是Grid search、Random search和Bayesian Optimization。网格搜索很容易理解和实现,例如我们的超参数A有2种选择,超参数B有3种选择,超参数C有5种选择,那么我们所有的超参数组合就有2 * 3 * 5也就是30种,我们需要遍历这30种组合并且找到其中最优的方案,对于连续值我们还需要等间距采样。实际上这30种组合不一定取得全局最优解,而且计算量很大很容易组合爆炸,并不是一种高效的参数调优方法。
业界公认的Random search效果会比Grid search好,Random search其实就是随机搜索,例如前面的场景A有2种选择、B有3种、C有5种、连续值随机采样,那么每次分别在A、B、C中随机取值组合成新的超参数组合来训练。虽然有随机因素,但随机搜索可能出现效果特别差、也可能出现效果特别好,在尝试次数和Grid search相同的情况下一般最值会更大,当然variance也更大但这不影响最终结果。在实现Random search时可以优化,过滤随机可能出现过的超参数组合,不需要重复计算。
实际上Grid search和Random search都是非常普通和效果一般的方法,在计算资源有限的情况下不一定比建模工程师的个人经验要好,接下来介绍的Bayesian Optimization就是“很可能”比普通开发者或者建模工程师调参能力更好的算法。首先贝叶斯优化当然用到了贝叶斯公式,这里不作详细证明了,它要求已经存在几个样本点(同样存在冷启动问题,后面介绍解决方案),并且通过高斯过程回归(假设超参数间符合联合高斯分布)计算前面n个点的后验概率分布,得到每一个超参数在每一个取值点的期望均值和方差,其中均值代表这个点最终的期望效果,均值越大表示模型最终指标越大,方差表示这个点的效果不确定性,方差越大表示这个点不确定是否可能取得最大值非常值得去探索。因此实现贝叶斯优化第一步就是实现高斯过程回归算法,并且这里可以通过类似SVM的kernel trick来优化计算,在后面的开源项目Advisor介绍中我们就使用Scikit-learn提供的GaussianProgressRegressor,最终效果如下图,在只有3个初始样本的情况下我们(通过100000个点的采样)计算出每个点的均值和方差。
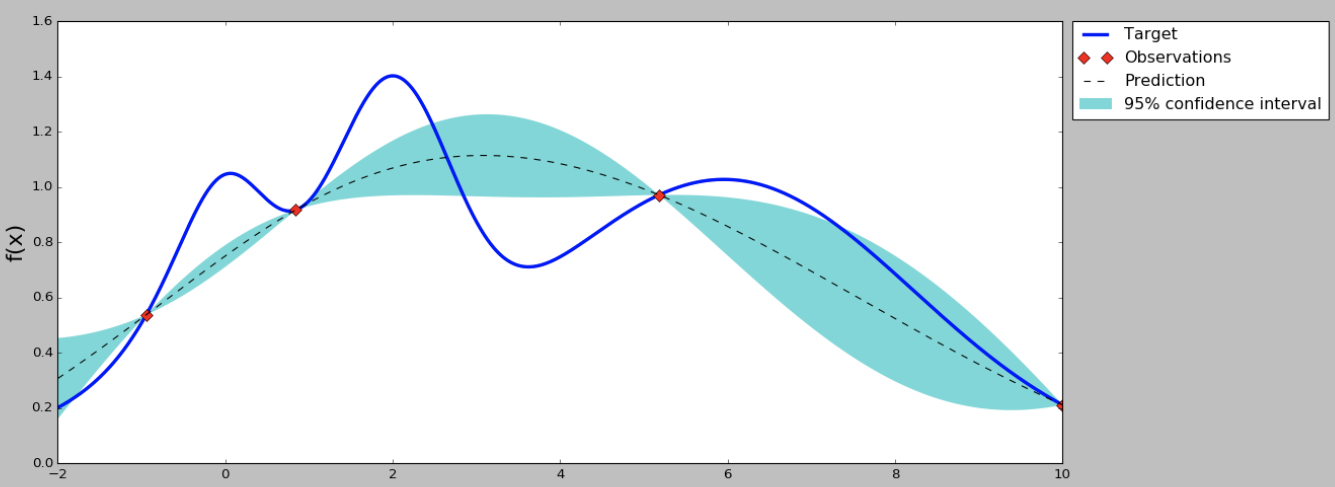
从曲线可以看出,中间的点均值较大,而且方差也比较大,很有可能这个点的超参数可以训练得到一个效果指标好的模型。那为什么要选均值大和方差大的点呢?因为前面提到均值代表期望的最终结果,当然是越大越好,但我们不能每次都挑选均值最大的,因为有的点方差很大也有可能存在全局最优解,因此选择均值大的点我们成为exploritation(开发),选择方差大的点我们称为exploration(探索)。那么究竟什么时候开发什么时候探索,并且开发和探索各占多少比例呢?不同的场景其实是可以有不同的策略的,例如我们的模型训练非常慢,只能再跑1组超参数了,那应该选择均值较大的比较有把握,如果我们计算力还能可以跑1000次,那么就不能放弃探索的机会应该选择方差大的,而至于均值和方差比例如何把握,这就是我们要定义的acquisition function了。acquisition function是一个权衡exploritation和exploration的函数,最简单的acquisition function就是均值加上n倍方差(Upper condence bound算法),这个n可以是整数、小数或者是正数、负数,更复杂的acquisition function还有Expected improvement、Entropy search等等。在原来的图上加上acquisition function曲线,然后我们求得acquisition function的最大值,这是的参数值就是贝叶斯优化算法推荐的超参数值,是根据超参数间的联合概率分布求出来、并且均衡了开发和探索后得到的结果。
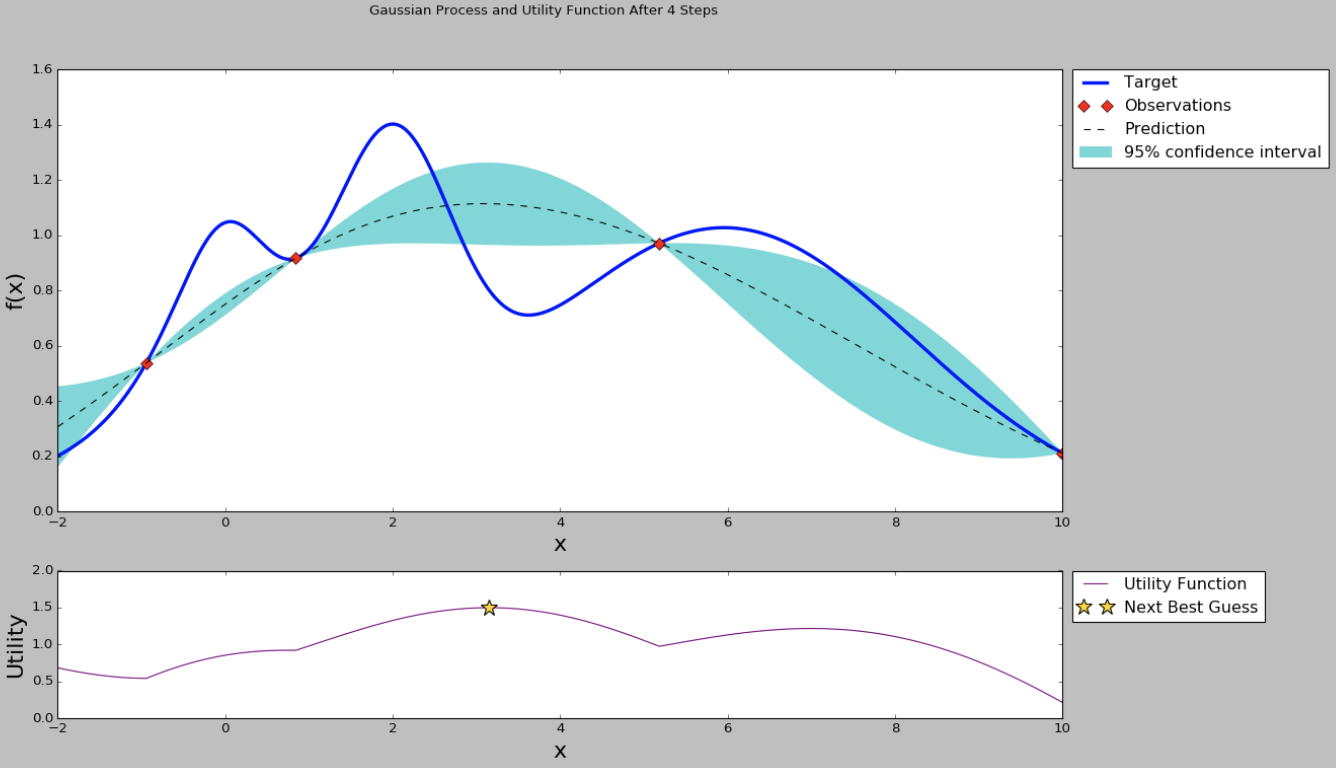
因此如果我们使用贝叶斯优化,那么我们下一个点就取中间偏左的点,使用这个点代表的超参数来训练模型,并且得到这个模型在这住超参数组合下的效果指标。有了新的指标,贝叶斯优化模型的样本就从3个变成了4个,这样可以重新计算超参数之间的后验概率分布和acquisition function,效果如下图。
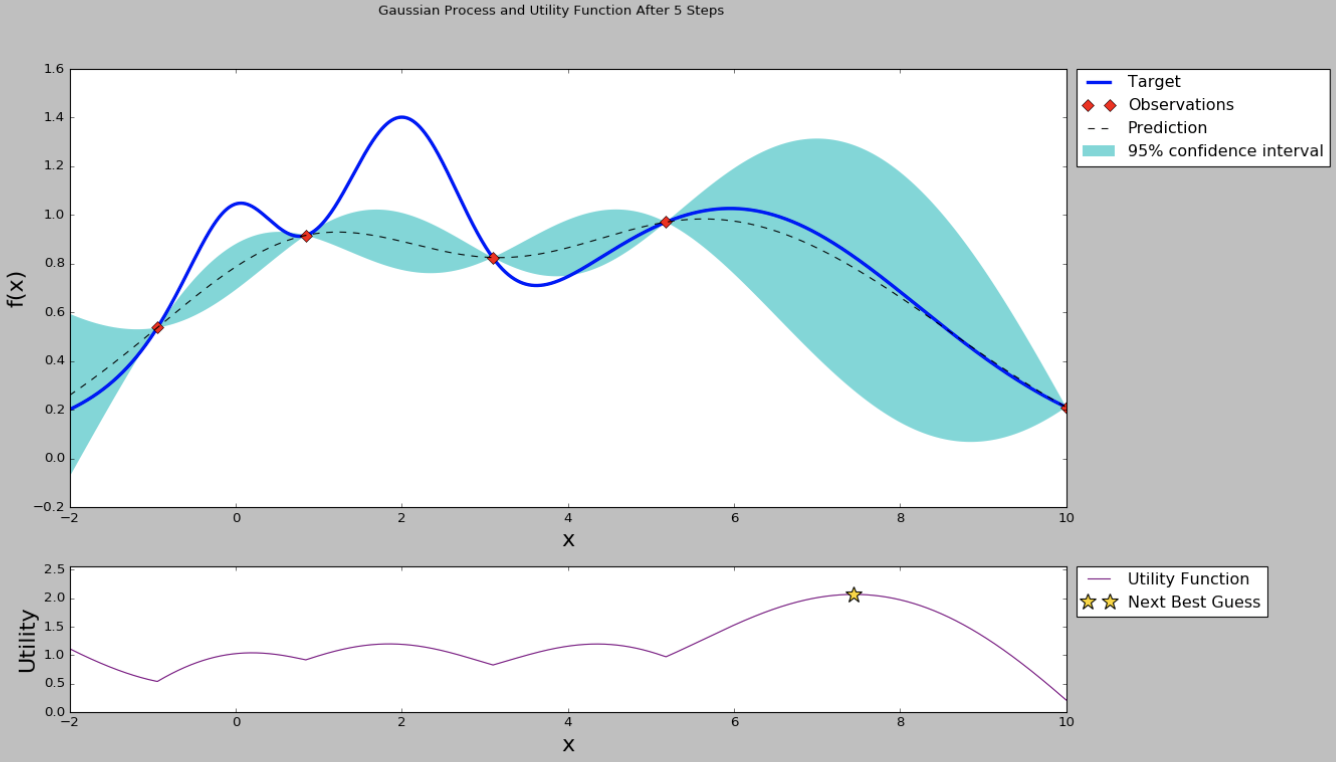
从均值和方差曲线看出,目前右边的点均值不低,并且方差是比较大,直观上我们认为探索右边区域的超参数是“很可能”有价值的。从acquisition function曲线我们也可以看出,右边的点在考虑了开发和探索的情况下有更高的值,因此我们下一个超参数推荐就是右边星号的点。然后我们使用推荐的超参数继续训练,得到新的模型效果指标,加入到高斯过程回归模型里面,得到新的均值-方差曲线和acquisition function曲线。
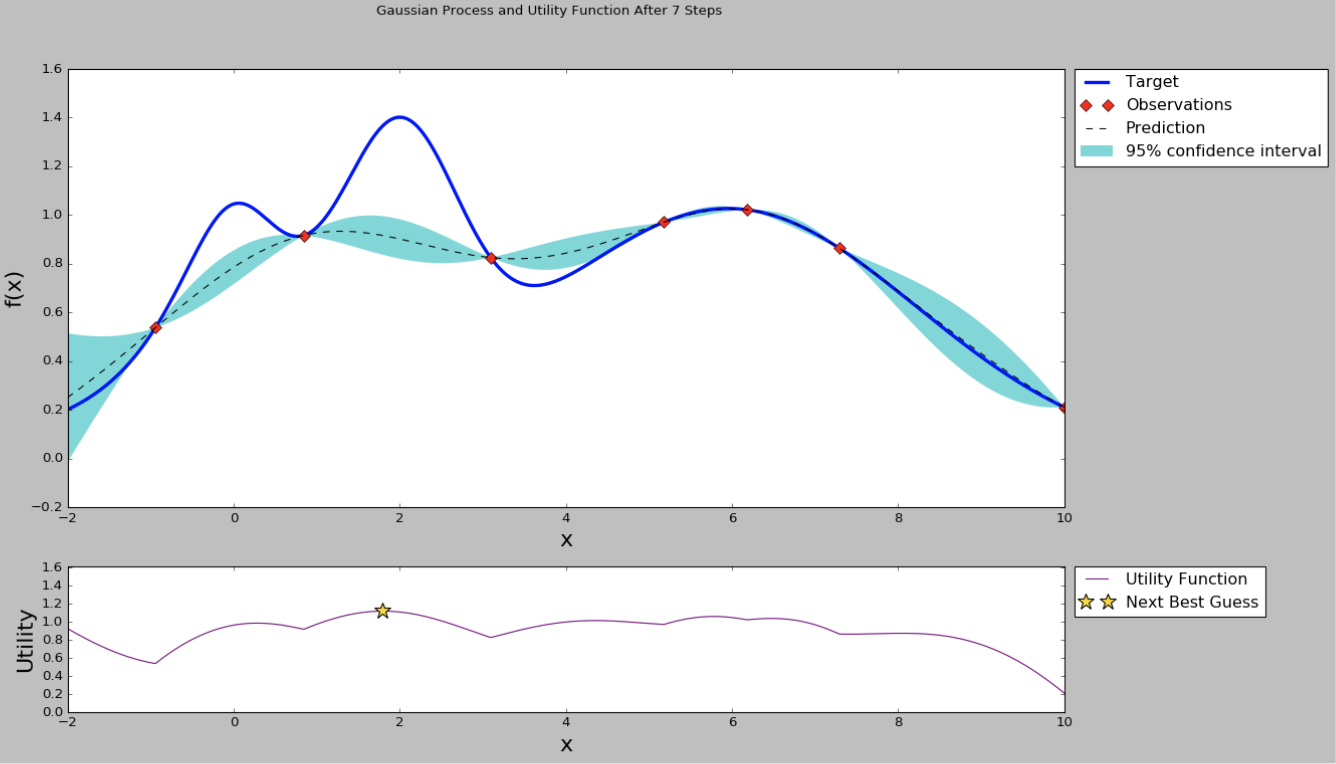
通过不断重复上述的步骤,我们的曲线在样本极少的情况下也可以毕竟最终真实的曲线。当然上面的图是在一个黑盒优化问题上模拟的,因此我们知道真实的曲线形状,现实的机器学习模型的超参数间不一定能画出完整的曲线,但通过符合联合高斯概率分布的假设,还有高斯过程回归、贝叶斯方程等数学证明,我们可以从概率上找到一个“很可能”更好的超参数,这是比Grid search或者Random search更有价值的方法。
注意,前面提到的Bayesian Optimization等超参数优化算法也是有超参数的,或者称为超超参数,如acquisition function的选择就是可能影响超参数调优模型的效果,但一般而言这些算法的超超参数极少甚至无须调参,大家选择业界公认效果比较好的方案即可。
Google Vizier
前面已经介绍了Grid search、Random search和Bayesian Optimization等算法,但并不没有完,因为我们要使用这些自动调参算法不可能都重新实现一遍,我们应该关注于自身的机器学习模型实现而直接使用开源或者易用的调参服务。
近期Google就开放了内部调参系统Google Vizier的论文介绍,感兴趣可以在这里阅读paper https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46180.pdf

与开源的hyperopt、optunity不同,Vizier是一个service而不是一个library,也就是算法开发者不需要自己部署调参服务或者管理参数存储,只需要选择合适的调参算法,如贝叶斯优化,然后Vizier就会根据模型的一些历史指标推荐最优的超参数组合给开发者,直接使用这些超参数会比自己瞎猜或者遍历参数组合得到的效果更好。当然开发者可以使用Vizier提供的Algorithm Playground功能实现自己的自动调参算法,还有内置一些EarlyStopAlgorithm也可以提前发现一些“没有前途”的调优任务提前结束剩下计算资源。
目前Google Vizier已经支持Grid search、Random search已经改良过的Bayesian optimization,为什么是改良过的呢?前面提到贝叶斯优化也需要几个初始样本点,这些样本点一般通过随机搜索要产生,这就有冷启动的代价了,Google将不同模型的参数都归一化进行统一编码,每个任务计算的GaussianProcessRegressor与上一个任务的GaussianProcessRegressor计算的残差作为目标来训练,对应的acquisition function也不是简单的均值乘以n倍方差了,这相当于用了迁移学习模型的概念,从paper的效果看基本解决了冷启动的问题,这个模型被称为(Stacked)Batch Gaussian Process Bandit。
Google Vizier除了实现很好的参数推荐算法,还定义了Study、Trial、Algorithm等非常好的领域抽象,这套系统也直接应用到Google CloudML的HyperTune subsystem中,开发者只需要写一个JSON配置文件就可以在Google Cloud上自动并行多任务调参了。
Advisor开源项目
Google Vizier是目前我看过最赞的超参数自动调优服务,可惜的是它并没有开源,外部也只有通过Google CloudML提交的任务可以使用其接口,不过其合理的基础架构让我们也可以重现一个类似的自动调参服务。
Advisor就是一个Google Vizier的开源实现,不仅实现了和Vizier完全一致的Study、Trial、Algorithm领域抽象,还提供Grid search、Random search和Bayesian optimization等算法实现。使用Advisor很简单,我们提供了API、SDK、Web以及命令行等多种访问方式,并且已经集成Scikit-learn、XGBoost和TensorFlow等开源机器学习框架,基本只要写一个Python函数定义好模型输入和指标就可以实现任意的超参数调优(黑盒优化)功能。
Advisor使用Python实现,基于Scikit-learn的GPR实现了贝叶斯优化等算法,也欢迎更多开发者参与,开源地址 tobegit3hub/advisor 。
Advisor在线服务
hypertune.cn 是我们提供的在线超参数推荐服务,也是体验Advisor调参服务的最好入口,在网页上我们就可以使用所有的Grid search、Random search、Bayesian optimization等算法功能了。
首先打开 http://hypertune.cn , 目前我们已经支持使用Github账号登录,由于还没有多租户权限隔离因此不需要登录也可以访问全局信息。在首页我们可以查看所有的Study,也就是每一个模型训练任务的信息,也可以在浏览器上直接创建Study。

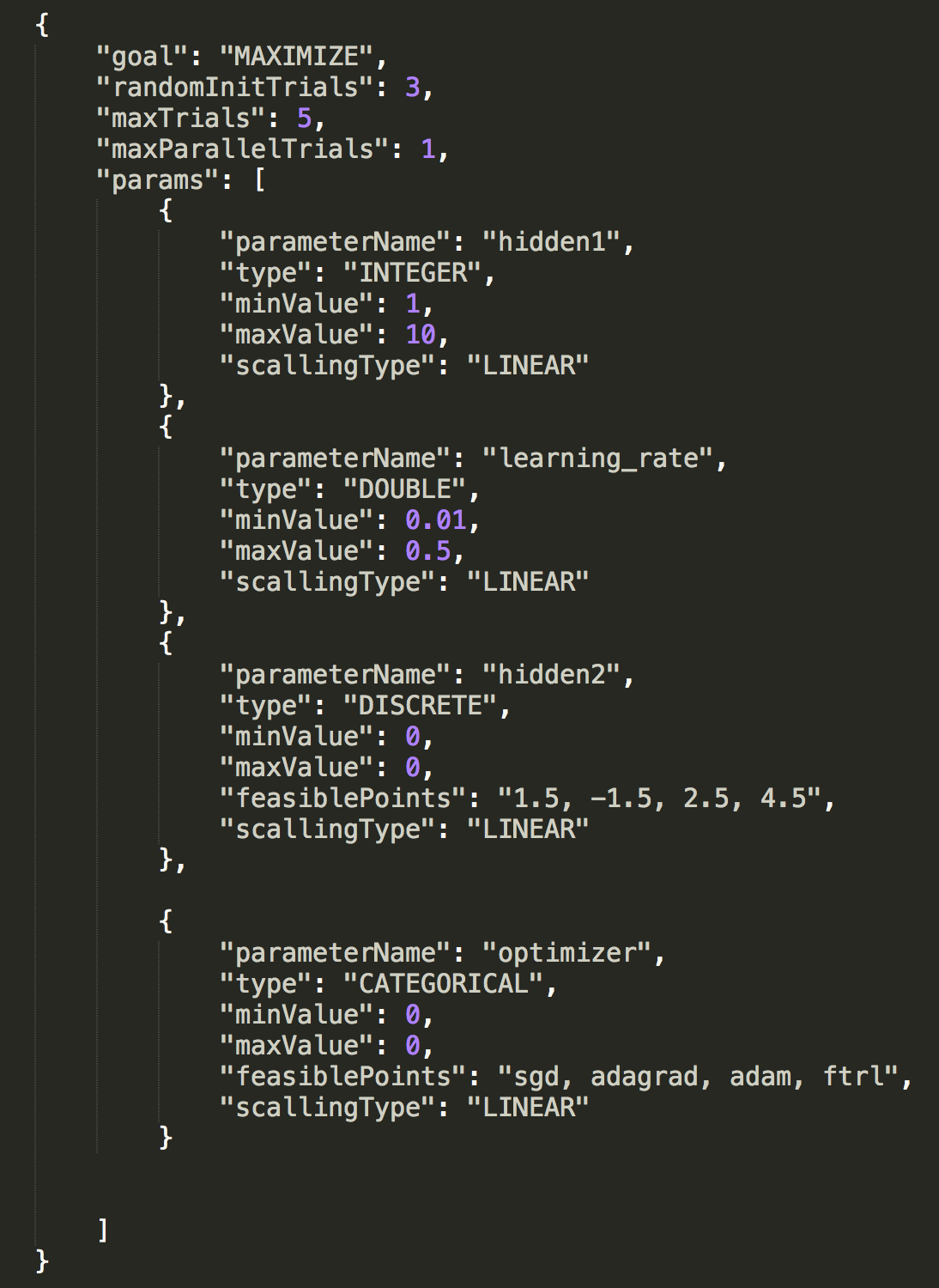
这里需要用户定义Study configuration,也就是模型超参数的search space,和Google Vizier一样我们支持Double、Integer、Discrete和Categorical四种类型的超参数定义,基本涵盖了数值型、字符串、连续型以及离散型的任意超参数类别,更详细的例子如下图。
定义好Study好,我们可以进入Study详情页,直接点击“Generate Suggestions”按钮生成推荐的超参数组合,这会根据用户创建Study选择的调参算法(如BayesianOptimization)来推荐,底层就是基于Scikit-learn实现的联合高斯分布、高斯过程回归、核技巧、贝叶斯优化等算法实现。
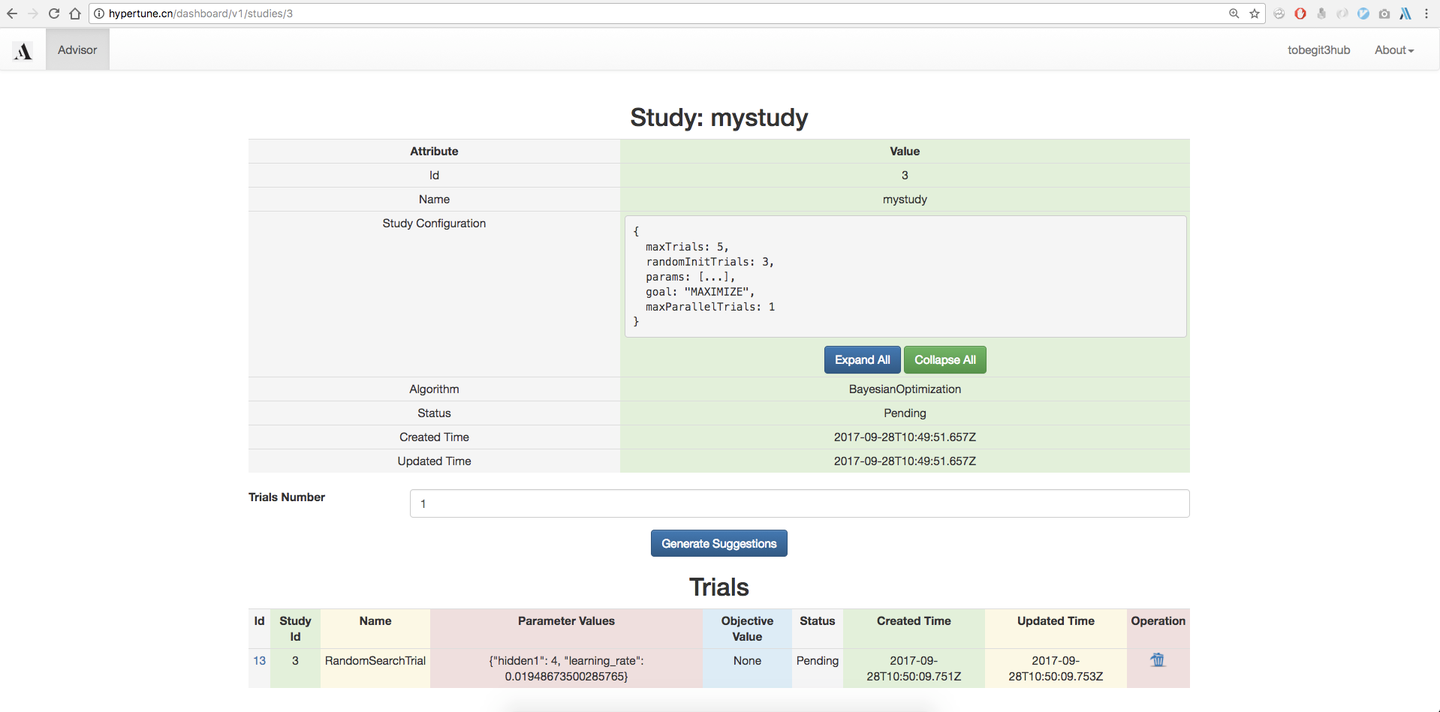
当然我们也可以使用Grid search、Random search等朴素的搜索算法,生成的Trial就是使用的该超参数组合的一次运行,默认是没有objective value的,我们可以在外部使用该超参数进行模型训练,然后把auc、accuracy、mean square error等指标在网页上回填到参数推荐服务,下一次超参数推荐就会基于已经训练得到模型数据,进行更优化、权衡exploritation和exploration后的算法推荐。对于Eearly stop算法,我们还需要每一步的性能指标,因此用户可以提供Training step以及对应的Objective value,进行更细化的优化。
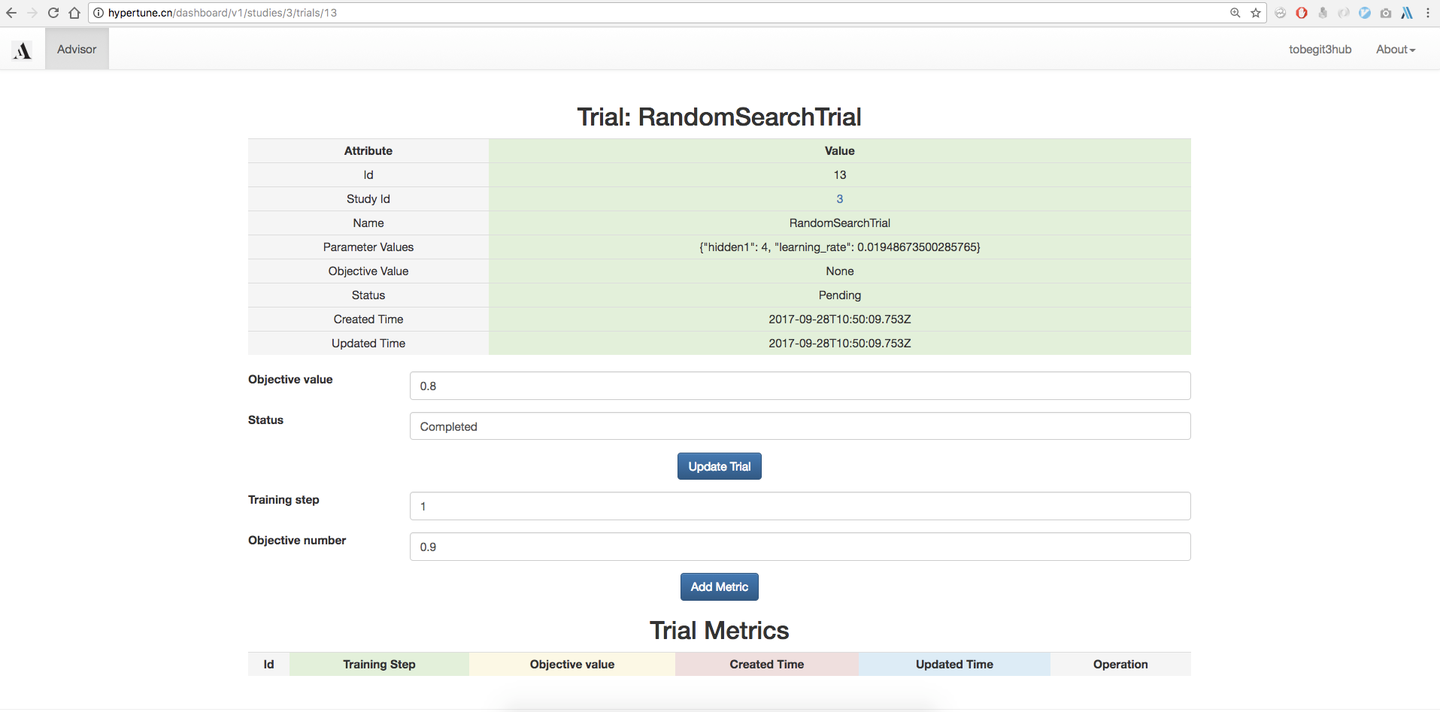
除了提供在网页上集成推荐算法,我们也集成了Scikit-learn、XGBoost和TensorFlow等框架,在命令行只要定义一个函数就可以自动实现创建Study、获取Trial以及更新Trial metrics等功能,参考 https://github.com/tobegit3hub/advisor/tree/master/examples 。对于贝叶斯优化算法,我们还提供了一维特征的可视化工具,像上面的图一样直观地感受均值、方差、acquisition function的变化,参考 https://github.com/tobegit3hub/advisor/tree/master/visualization 。
总结
本文介绍了一种更好的超参数调优方法,也就是贝叶斯优化算法,并且介绍了Google内部的Vizier调参服务以及其开源实现Advisor项目。通过使用更好的模型和工具,可以辅助机器学习工程师的建模流程,在学术界和工业界取得更多、更大的突破。
如果你有更好的超参数推荐算法,不妨留言,我们有能力实现并且让更多人用上 :)