DIN 是排序
MIND 是召回
如何刻画用户的多样兴趣——MIND network阅读笔记
导读:同一个用户可能有多样的兴趣,如何在深度模型中刻画这些多样的兴趣呢?阿里今年的文章《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》给出一种方案,本文是阅读此篇文章的笔记。
推荐系统做的事情无非就是在一定的场景(context)下给特定的用户(user)推荐特定的一些物料(item)。
当然,具体的用户、场景、物料是没法直接使用的,需要先进行抽象(即构造特征,比如用年龄、性别等社会人口属性和用户点击等行为特征来表达用户),而如何构造这种抽象表示(representation),使其能在具体业务问题下准确、简洁地表达原先的对象,对推荐的效果起着决定性的作用。
推荐中经典深度模型范式与其局限
深度学习在推荐系统的应用中,最经典的范式是Embedding&MLP(代表为Youtube DNN)。这种范式中,user ID、用户历史交互item ID等高维category特征都被映射成为低维的embedding,MLP只能接受固定长度的输入,而用户历史上交互过的item数目是不固定,Embedding&MLP范式的应对方法是把用户交互过的item embedding求均值(进行average pooling操作),然后把这个固定长度的均值作为user representation的一部分。
 图一 Embedding&MLP范式
图一 Embedding&MLP范式
图示为电商场景下Embedding&MLP的范式图示,用户交互过的N个商品,每个商品都可以求得一个embedding,对N个embedding进行pooling后,再与其他固定长度的特征concat,作为MLP的输入
前面提到用户的特征包括社会人口特征和行为特征,社会人口特征只能对用户大致做一个分群,用户本身的历史行为特征才是个性化地刻画用户的最重要信号,一定程度上,我们可以认为用户的历史行为,就是用户个性化的兴趣。多数用户的兴趣是分散的,比如在电商场景中,很多用户都有百个以上的历史点击商品,这些商品的品牌、类目都有可能十分不同,一个用户可能既对口红有兴趣、也对猫砂有兴趣,而简单地对用户历史点击过商品的embedding求均值来作为用户兴趣的embedding,是不是真的能准确刻画用户多样性的兴趣呢?很可能不准确,当对很多个兴趣(历史交互item)的embedding求均值时,有些长尾兴趣可能被湮没、新求的均值兴趣可能会有不可预知的偏移、原先embedding的维度可能不足以表达分散、多样的兴趣。
阿里的两种改进思路
为了解决表达用户多样兴趣的问题,阿里分别提出了DIN(Deep Interest Network)和MIND(Multi-Interest Network with Dynamic Routing)两种深度网络,分别在推荐的排序阶段和召回阶段建模表达用户的多样兴趣。
- DIN引入了attention机制,同一个用户与不同的item进行预测时,DIN会产生不同的用户embedding,具体来说,当预测某个item时,计算出该item与用户历史交互item的“匹配度”,用这个匹配度作为权重对用户历史交互item做加权平均得到用户的兴趣embedding,之后用这个兴趣embedding与用户的其他特征组成所谓label-aware的用户embedding。
- 而MIND使用另外一种思路,既然使用一个向量表达用户多样兴趣有困难,那么为什么不使用一组向量呢?具体来说,如果我们可以对用户历史行为的embedding进行聚类,聚类后的每个簇代表用户的一组兴趣,不就解决问题了么。
MIND的具体实现
MIND借鉴了Hiton的胶囊网络(Capsule Network),提出了Multi-Interest Extractor Layer来对用户历史行为embedding进行软聚类,,在介绍它之前我们先用一张图来对比一下Capsule Network与传统神经网络的区别。

vector in, vector out versus. scalar in, scalar out
图二 Capsule与传统神经元的对比
Capsule Network中的Capsule概念对应于传统神经网络中的neuron,操作也类似。传统的神经网络输入一组标量,对这组标量求加权和,之后输入非线性激活函数得到一个标量的输出。而Capsule输入是一组向量,对这组向量进行仿射变换之后求加权和,把加权和输入非线性激活函数得到一个向量的输出。Hinton提出Capsule Network是为了解决传统的CNN中只能编码某个特征是否存在而无法编码特征的orientation。(在MIND的中我们只要记住Capsule可以接受一组向量输入,输出一个向量;如果我们K个capsule,就会有K个输出向量)
原始的Capsule Network,如果有m个输入向量,n个输出向量,输入向量和输出向量两两之间各有自己的仿射变换矩阵,那么总共会有m*n个变换矩阵(上图中的Wij),而且仿射变换之后向量的权重(上图中的c_ij)最开始是初始化为0的。MIND做了两处改动,一个是仿射矩阵变为共享,从m*n个变为1个,这么做的原因之一是用户交互过的item数目是不同的(即输入向量的数目会变化),使用共享的变换矩阵可以做到以不变应万变,另外这样做也减少了模型的参数;第二个改动是第一个改动的衍生,共享变换矩阵后,如果权重仍然初始化为0,会导致输出向量一模一样,因此,在这里使用权重随机初始化的策略。图三是原文给出的Multi-Interest Extractor Layer层算法流程,注意在这里权重用w_ij表示,变换矩阵用S表示,另外,输出向量的个数也根据输入向量的个数做了动态调整(后面实验有针对这个策略进行验证,虽然对CTR没有提升,但可以节省资源)。

图三 Multi-Interest Extractor Layer算法流程
动态决定输出向量(兴趣embedding)个数的公式:
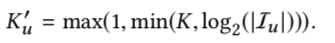
决定输出向量个数的公式
整个MIND network的结构如下图所示:
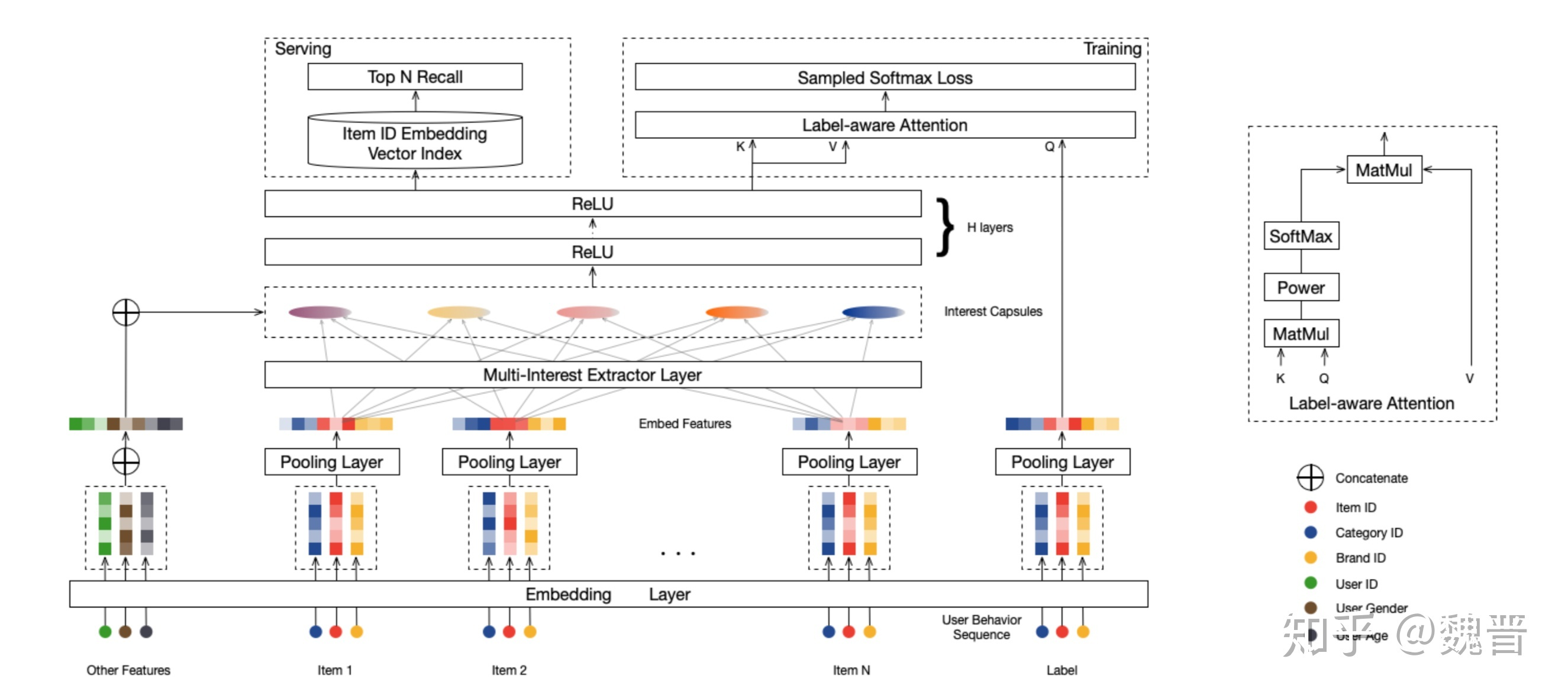
图四 MIND模型结构
MIND中的用户特征由历史交item和基础画像属性组成,用户历史交互item由item ID,item所属类目ID和Item所属品牌ID三部分组成,这三部分进行低维embedding之后做average pooling,合成item本身的embedding表示。用户交互过的items生成的一组向量(即item embedding)作为Multi-Interest Extractor Layer的输入,经过dynamic routing之后,产生另外一组向量(即兴趣embedding),作为用户多样化兴趣的表示。用户基础画像属性的embedding与用户兴趣embedding分别做concat,接着经过两层ReLU隐层,得到用户的一组embedding。
在训练阶段,要进行预测的label只有一个embedding,而用户有一组,没法直接求内积计算匹配度,这里MIND提出了Label-aware Attention,思路跟DIN是一致的,就是根据label的embedding对用户的一组embedding分别求出权重(所谓label-aware),然后对用户的一组embedding求加权和,得到最终的一个embedding,只是具体方案上有差别。图三右上角是Label-aware Attention的图示,K,V都是用户embedding(矩阵),Q是label embedding(向量),K、Q相乘可以得到不同的用户embedding对label的响应程度,Power对求得的响应做指数运算(可以控制指数的大小),从而控制attention的程度,指数越大,响应高的用户embedding最终权重占比越大。SoftMax对结果进行归一化,最后一步的MatMul求得加权和。
在召回阶段,直接使用用户的一组embedding进行召回,假设要召回TOP N,定义召回分如下:
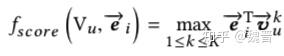
召回分定义
其中Vu代表用户的一组向量,有K个,e代表候选item的embedding,最后计算计算每个item的召回分,取召回分TOP N的item。
实验结果
MIND在Amazon Books和TmallData两个电商数据集上做了实验,并与Youtube DNN等其他方法做了对比,表现都是最好的(要不也不会发论文嘛)。另外还对Label-aware attetion中power操作指数的大小做了实验,结果证明“注意力越集中,效果越好”。
线上实验的话,表现也是优于YouTube DNN和item-based CF的(注意,item-based CF效果要好于YouTubeDNN,作者在这里给YouTubeDNN找了下场子,说是可能因为item-based CF经过长时间实践优化的原因)。另外,线上实验还表明,用户兴趣分得越细(用户向量数K越大),效果越好。根据用户历史行为数动态调整兴趣数(K的值)虽然线上指标没有提升,但是模型资源消耗降低了。