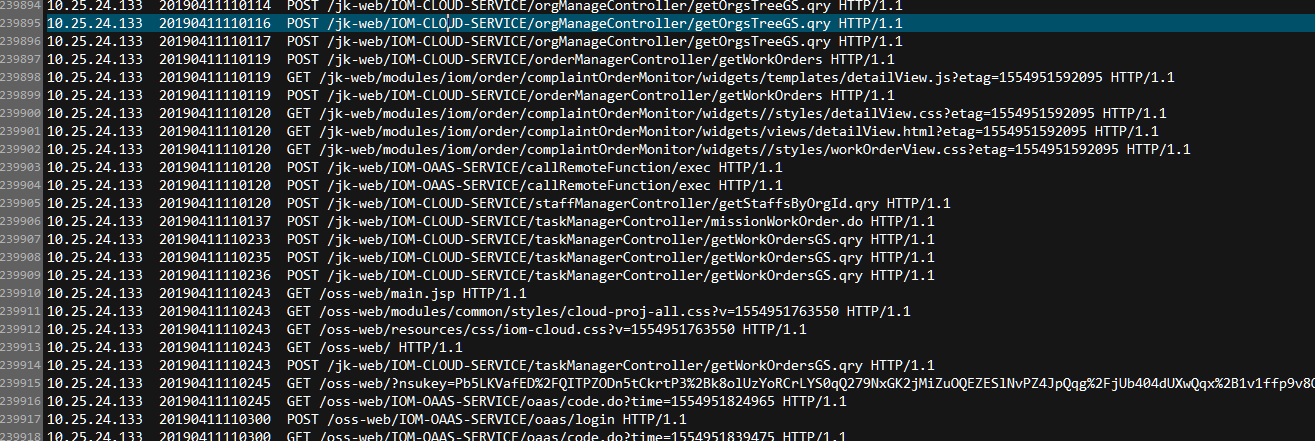
1.首先我们需要一个util辅助类
package cn.cutter.demo.hadoop.mapreduce.nginxlog.util; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Locale; /** * @ClassName AccessLogUtil * @Description * @Author xiaof * @Date 2019/5/15 22:07 * @Version 1.0 **/ public class AccessLogUtil { public static final SimpleDateFormat FORMAT = new SimpleDateFormat( "d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); public static final SimpleDateFormat dateformat1 = new SimpleDateFormat( "yyyyMMddHHmmss");/** * 解析英文时间字符串 * * @param string * @return * @throws ParseException */ private static Date parseDateFormat(String string) { Date parse = null; try { parse = FORMAT.parse(string); } catch (ParseException e) { e.printStackTrace(); } return parse; } /** * 解析日志的行记录 * * @param line * @return 数组含有5个元素,分别是ip、时间、url、状态、流量,请求来源 */ public static String[] parse(String line) { String ip = parseIP(line); String time = parseTime(line); String url = parseURL(line); String status = parseStatus(line); String traffic = parseTraffic(line); String sourcePath = parseSource(line); return new String[] { ip, time, url, status, traffic, sourcePath }; } private static String parseTraffic(String line) { // final String trim = line.substring(line.lastIndexOf("-") + 1) // .trim(); int start = line.indexOf("""); int second = line.indexOf(""", start + 1); int three = line.indexOf(""", second + 1); final String trim = line.substring(second + 1, three) .trim(); String traffic = trim.split(" ")[1]; return traffic; } private static String parseStatus(String line) { int start = line.indexOf("""); int second = line.indexOf(""", start + 1); int three = line.indexOf(""", second + 1); final String trim = line.substring(second + 1, three) .trim(); String status = trim.split(" ")[0]; return status; } private static String parseURL(String line) { final int first = line.indexOf("""); final int second = line.indexOf(""", first + 1); final int last = line.lastIndexOf("""); String url = line.substring(first + 1, second); return url; } private static String parseTime(String line) { final int first = line.indexOf("["); final int last = line.indexOf("+0800]"); String time = line.substring(first + 1, last).trim(); Date date = parseDateFormat(time); return dateformat1.format(date); } private static String parseIP(String line) { String ip = line.substring(0, line.indexOf("-")).trim(); return ip; } private static String parseSource(String line) { final int end = line.lastIndexOf("""); final int start = line.lastIndexOf(""", end - 1); String sourcePath = line.substring(start + 1, end).trim(); return sourcePath; } public static void main(String args[]) { String s1 = "10.25.24.133 - admin [07/Mar/2019:14:19:53 +0800] "GET /oss-eureka-server/console HTTP/1.1" 200 21348 "http://218.200.65.200:9425/oss-web/main.jsp" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36" "; String result[] = AccessLogUtil.parse(s1); for(int i = 0; i < result.length; ++i) { System.out.println(result[i]); } } }
2.map类
package cn.cutter.demo.hadoop.mapreduce.nginxlog.map; import cn.cutter.demo.hadoop.mapreduce.nginxlog.util.AccessLogUtil; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * @ProjectName: cutter-point * @Package: cn.cutter.demo.hadoop.mapreduce.nginxlog.map * @ClassName: NginxAccessLogMap * @Author: xiaof * @Description: ${description} * @Date: 2019/5/17 11:12 * @Version: 1.0 */ public class NginxAccessLogCleanMap extends Mapper<LongWritable, Text, LongWritable, Text> { Text outputValue = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //解析没行数据,获取不同的数据 String data[] = AccessLogUtil.parse(value.toString()); //组装前三个数据信息,输出到combine outputValue.set(data[0] + " " + data[1] + " " + data[2]); context.write(key, outputValue); } }
3.reduce类
package cn.cutter.demo.hadoop.mapreduce.nginxlog.reduce; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * @ProjectName: cutter-point * @Package: cn.cutter.demo.hadoop.mapreduce.nginxlog.reduce * @ClassName: NginxAccessLogReduce * @Author: xiaof * @Description: 进行数据清洗 * @Date: 2019/5/17 11:21 * @Version: 1.0 */ public class NginxAccessLogCleanReduce extends Reducer<LongWritable, Text, Text, NullWritable> { @Override protected void reduce(LongWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //循环所有遍历到的数据并输出 for(Text v : values) { context.write(v, NullWritable.get()); } } }
4.启动类
package cn.cutter.demo.hadoop.mapreduce.nginxlog; import cn.cutter.demo.hadoop.mapreduce.nginxlog.map.NginxAccessLogCleanMap; import cn.cutter.demo.hadoop.mapreduce.nginxlog.reduce.NginxAccessLogCleanReduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; /** * @ProjectName: cutter-point * @Package: cn.cutter.demo.hadoop.mapreduce.nginxlog * @ClassName: NginxAccessLogClean * @Author: xiaof * @Description: hadoop jar ./cutter-point-service1.jar NginxAccessLogClean /user/xiaof/nginx /user/xiaof/nginx/output * @Date: 2019/5/17 11:25 * @Version: 1.0 */ public class NginxAccessLogClean { public static void main(String args[]) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException { System.out.println("进入NginxAccessLogClean方法"); Configuration conf = new Configuration(); // conf.set("mapreduce.job.jar", "cutter-point-service1.jar"); //其中mr01.jar是你的导出的jar文件名。 conf.set("fs.default.name", "hdfs://jyh-zhzw-inline-27:9000"); conf.set("dfs.client.use.datanode.hostname", "true"); GenericOptionsParser optionsParser = new GenericOptionsParser(conf, args); String[] remainingArgs = optionsParser.getRemainingArgs(); //输出参数 for(int i = 0; i < remainingArgs.length; ++i) { System.out.println(remainingArgs[i]); } Job job = Job.getInstance(conf, NginxAccessLogClean.class.getName()); job.setJarByClass(NginxAccessLogClean.class); job.setMapperClass(NginxAccessLogCleanMap.class); job.setMapOutputKeyClass(LongWritable.class); job.setMapOutputValueClass(Text.class); job.setReducerClass(NginxAccessLogCleanReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 清理已存在的输出文件 FileInputFormat.setInputPaths(job, remainingArgs[0]); FileOutputFormat.setOutputPath(job, new Path(remainingArgs[1])); FileSystem fs = FileSystem.get(new URI(remainingArgs[0]), conf); Path outPath = new Path(remainingArgs[1]); if (fs.exists(outPath)) { fs.delete(outPath, true); } boolean success = job.waitForCompletion(true); if(success){ System.out.println("Clean process success!"); } else{ System.out.println("Clean process failed!"); } } }
数据源:
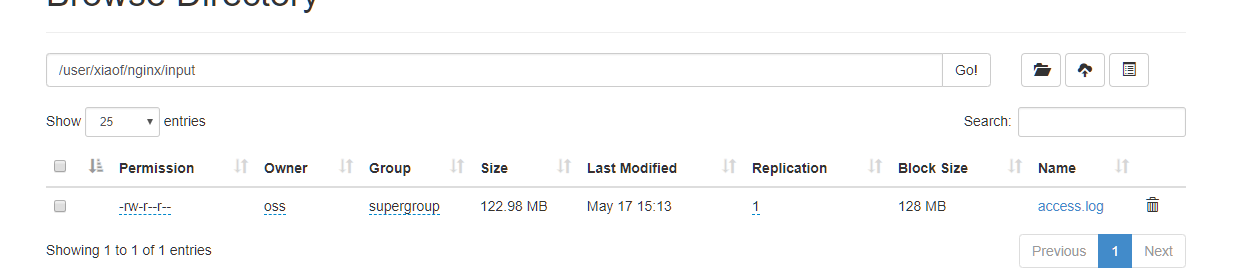
我们文件原始数据格式展示

我们清洗之后数据展示
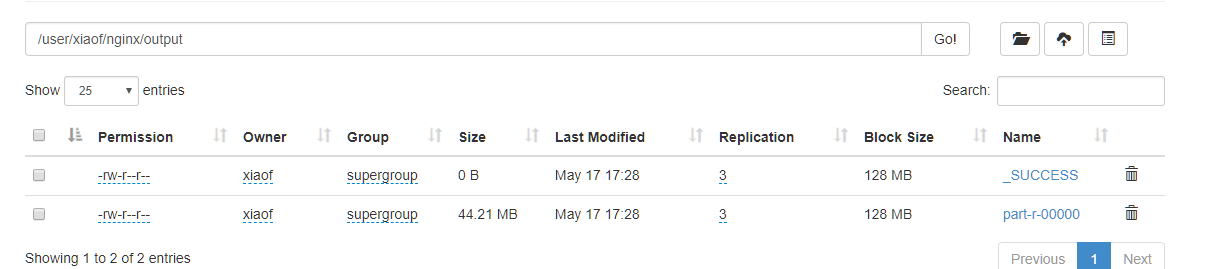
展示数据