Solr的defType有dismax/edismax两种,这两种的区别,可参见:http://blog.csdn.net/duck_genuine/article/details/8060026
下面示例用于演示如下场景:
有一网站,在用户查询的结果中,需要按这样排序:
- VIP的付费信息需要排在免费信息的前头
- 点击率越高越靠前
- 发布时间越晚的越靠前
这样的查询排序使用普通的查询结果的Order by是做不到的,必需使用solr的defType。
做法:
1、先看schema.xml的定义:

<?xml version="1.0" ?>
<schema name="sample5" version="1.1">
<fieldtype name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="tdate" class="solr.TrieDateField" precisionStep="6" positionIncrementGap="0"/>
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldtype name="binary" class="solr.BinaryField"/>
<fieldType name="text_cn" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false" />
<analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="true" />
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory" ignoreCase="true"/>
</analyzer>
</fieldType>
<!-- general -->
<fields>
<field name="id" type="long" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="subject" type="text_cn" indexed="true" stored="true" />
<field name="content" type="text_cn" indexed="true" stored="true" />
<field name="regionId" type="int" indexed="true" stored="true" />
<field name="region" type="text_cn" indexed="true" stored="true" />
<field name="categoryId" type="int" indexed="true" stored="true" />
<field name="category" type="text_cn" indexed="true" stored="true" />
<field name="price" type="float" indexed="true" stored="true" />
<field name="createTime" type="tdate" indexed="true" stored="true" />
<field name="point" type="long" indexed="true" stored="true" />
<field name="vip" type="boolean" indexed="true" stored="true" />
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="searchText" type="text_cn" indexed="true" stored="false" multiValued="true" />
</fields>
<copyField source="subject" dest="searchText" />
<copyField source="content" dest="searchText" />
<copyField source="region" dest="searchText" />
<copyField source="category" dest="searchText" />
<!-- field to use to determine and enforce document uniqueness. -->
<uniqueKey>id</uniqueKey>
<!-- field for the QueryParser to use when an explicit fieldname is absent -->
<defaultSearchField>searchText</defaultSearchField>
<!-- SolrQueryParser configuration: defaultOperator="AND|OR" -->
<solrQueryParser defaultOperator="AND"/>
</schema>
说明:
a)里头定义了一个copyField:searchText,此字段为:subject+content+region+category,并把这个字段设置为默认查询字段。意思是查询时,默认查询四个字段的内容。
b)把solrQueryParser设置为AND,事实上,大多情况下,我们是习惯使用AND为条件查询,而非OR
c)text_cn字段类型中的:useSmart
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false" />
<analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="true" />
意思是:useSmart =true ,分词器使用智能切分策略, =false则使用细粒度切分。详细,可下载IK分词器的源码看看。
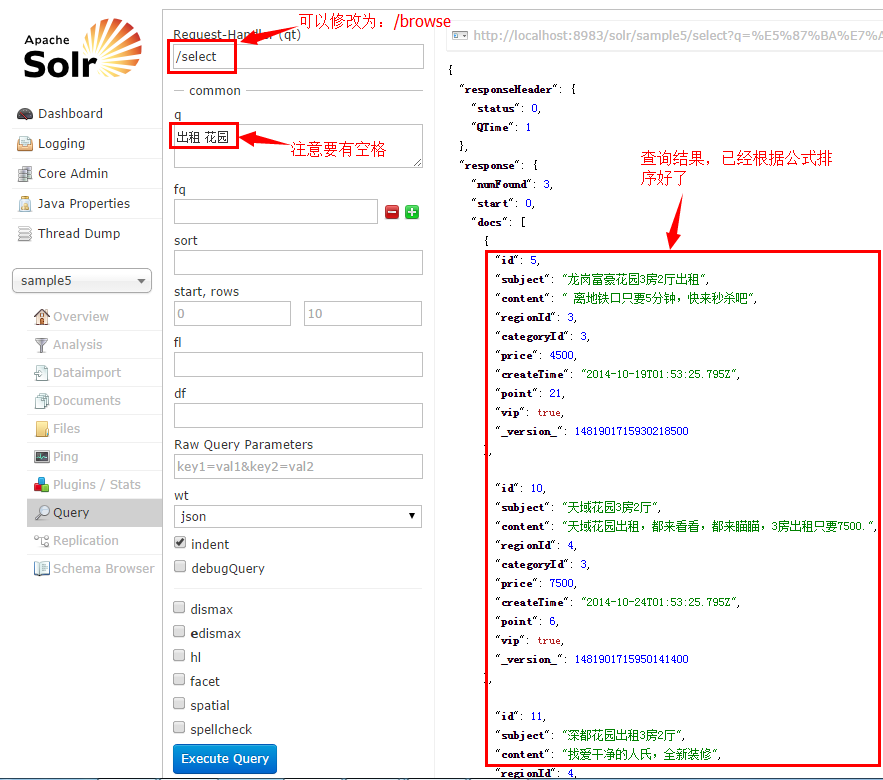
2、加入一个查询Handler到solrconfig.xml的<config/>当中:
<requestHandler name="/browse" class="solr.SearchHandler" default="true" >
<lst name="defaults">
<str name="defType">edismax</str>
<str name="bf">
sum(linear(vip,1000,0),linear(sqrt(log(linear(point,1,2))),100,0),sqrt(log(ms(createTime))))
</str>
<!--<str name="pf">
searchText
</str>
<str name="qf">
subject^1 content^0.8
</str>-->
</lst>
</requestHandler>
说明:
a)上面的default="true"意思为设置为默认的查询handler(记得把原standard中的default="true"删除掉)
b)见已经被注释的这段:
<!--<str name="pf">
searchText
</str>
<str name="qf">
subject^1 content^0.8
</str>-->
这是简单的不使用bf的排序加权方式,可以用于应付简单的排序,具体pf/qf的使用,可以上网上搜搜应用。这里演示的功能相对“复杂”,不适用它。
c)见这句公式:
sum(linear(vip,1000,0),linear(sqrt(log(linear(point,1,2))),100,0),sqrt(log(ms(createTime))))
公式中的函数定义和意思,可以参考:
官方文档:
http://wiki.apache.org/solr/FunctionQuery
中文说明:
http://mxsfengg.iteye.com/blog/352191
这里的函数意思是:
- 如果是vip信息=值+1000,非vip信息=值+0
- 点击率(point)的值范围为:50~500之间
- 发布时间(createTime)值范围为:50以内
以上三个值相加得出最统权重分从高到低排序
3、Java bean:
package com.my.entity;
import java.util.Date;
import org.apache.solr.client.solrj.beans.Field;
public class Item {
@Field
private long id;
@Field
private String subject;
@Field
private String content;
@Field
private int regionId;
@Field
private int categoryId;
@Field
private float price;
@Field
private Date createTime;
@Field
private long point;
@Field
private boolean vip;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject = subject;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public int getRegionId() {
return regionId;
}
public void setRegionId(int regionId) {
this.regionId = regionId;
}
public int getCategoryId() {
return categoryId;
}
public void setCategoryId(int categoryId) {
this.categoryId = categoryId;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
public long getPoint() {
return point;
}
public void setPoint(long point) {
this.point = point;
}
public boolean isVip() {
return vip;
}
public void setVip(boolean vip) {
this.vip = vip;
}
}
4、Java测试代码:
package com.my.solr;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Date;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrQuery.ORDER;
import org.apache.solr.client.solrj.SolrQuery.SortClause;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.impl.XMLResponseParser;
import org.apache.solr.client.solrj.response.FacetField;
import org.apache.solr.client.solrj.response.FacetField.Count;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.params.AnalysisParams;
import org.apache.solr.common.params.CommonParams;
import org.apache.solr.common.params.FacetParams;
import org.apache.solr.common.util.NamedList;
import org.apache.solr.common.util.SimpleOrderedMap;
import com.my.entity.Item;
public class TestSolr {
private static HashMap<Integer, String> mapRegion = new HashMap<Integer, String>();
private static HashMap<Integer, String> mapCategory = new HashMap<Integer, String>();
@SuppressWarnings("unchecked")
public static void main(String[] args) throws IOException,
SolrServerException {
// ------------------------------------------------------
// Set map
// ------------------------------------------------------
mapRegion.put(1, "罗湖区");
mapRegion.put(2, "南山区");
mapRegion.put(3, "龙岗区");
mapRegion.put(4, "福田区");
mapCategory.put(1, "单间");
mapCategory.put(2, "2房1厅");
mapCategory.put(3, "3房2厅");
mapCategory.put(4, "1房1厅");
String url = "http://localhost:8983/solr/sample5";
HttpSolrServer core = new HttpSolrServer(url);
core.setMaxRetries(1);
core.setConnectionTimeout(5000);
core.setParser(new XMLResponseParser()); // binary parser is used by
// default
core.setSoTimeout(1000); // socket read timeout
core.setDefaultMaxConnectionsPerHost(100);
core.setMaxTotalConnections(100);
core.setFollowRedirects(false); // defaults to false
core.setAllowCompression(true);
// ------------------------------------------------------
// remove all data
// ------------------------------------------------------
core.deleteByQuery("*:*");
List<Item> items = new ArrayList<Item>();
items.add(makeItem(items.size() + 1, "龙城公寓一房一厅", "豪华城城公寓1房1厅,拧包入住", 1, 1, 1200f, 10, false));
items.add(makeItem(items.size() + 1, "兴新宿舍楼 1室0厅", " 中等装修 招女性合租", 1, 1, 1000f, 11, false));
items.add(makeItem(items.size() + 1, "西丽新屋村新宿舍楼单间", " 无敌装修只招女性", 2, 1, 1000f, 2, true));
items.add(makeItem(items.size() + 1, "大芬村信和爱琴居地铁口2房1厅", " 地铁口 + 出行便利=居家首选", 3, 2, 2000f, 5, false));
items.add(makeItem(items.size() + 1, "龙岗富豪花园3房2厅出租", " 离地铁口只要5分钟,快来秒杀吧", 3, 3, 4500f, 21, true));
items.add(makeItem(items.size() + 1, "海景房园3房2厅出租", "海景房园出租,无敌海景,可以看到伦敦", 4, 3, 8500f, 12, false));
items.add(makeItem(items.size() + 1, "天域花园1房1厅", "天域花园,男女不限,入住免水电一月", 2, 4, 1500f, 13, true));
items.add(makeItem(items.size() + 1, "神一样的漂亮,玉馨山庄3房2厅", "心动不如行动,拧包即可入住,来吧!", 1, 3, 9500f, 8, false));
items.add(makeItem(items.size() + 1, "玉馨山庄2房1厅,情侣最爱", "宅男宅女快来吧只要2500,走过路过,别再错过", 1, 2, 2500f, 5, false));
items.add(makeItem(items.size() + 1, "天域花园3房2厅", "天域花园出租,都来看看,都来瞄瞄,3房出租只要7500.", 4, 3, 7500f, 6, true));
items.add(makeItem(items.size() + 1, "深都花园出租3房2厅", "找爱干净的人氏,全新装修", 4, 3, 5200f, 31, false));
items.add(makeItem(items.size() + 1, "This is Mobile test", "haha Hello world!", 4, 3, 1200f, 31, false));
core.addBeans(items);
// commit
core.commit();
// ------------------------------------------------------
// Set search text
// ------------------------------------------------------
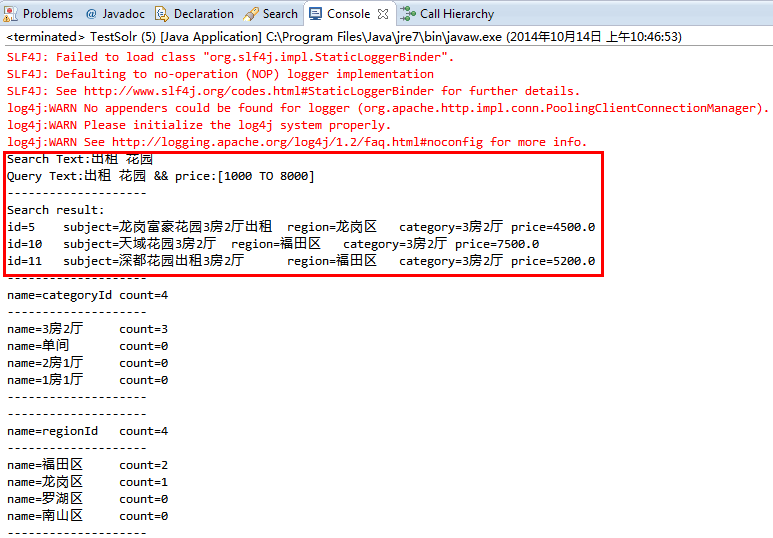
String searchText = AnalysisSearchText(core, "出租花园"); //subject:*出租* && price:[1000 TO 8000]
System.out.println("Search Text:" + searchText);
// ------------------------------------------------------
// Set query text
// ------------------------------------------------------
String queryText = searchText + "&& price:[1000 TO 8000]";
System.out.println("Query Text:" + queryText);
// ------------------------------------------------------
// search
// ------------------------------------------------------
SolrQuery query = new SolrQuery();
query.setQuery(queryText);
query.setStart(0); // query的开始行数(分页使用)
query.setRows(100); // query的返回行数(分页使用)
query.setFacet(true); // 设置使用facet
query.setFacetMinCount(0); // 设置facet最少的统计数量
query.setFacetLimit(10); // facet结果的返回行数
query.addFacetField("categoryId", "regionId"); // facet的字段
query.setFacetSort(FacetParams.FACET_SORT_COUNT);
//query.addSort(new SortClause("id", ORDER.asc)); // 排序
query.setRequestHandler("/browse");
QueryResponse response = core.query(query);
List<Item> items_rep = response.getBeans(Item.class);
List<FacetField> facetFields = response.getFacetFields();
// 因为上面的start和rows均设置为0,所以这里不会有query结果输出
System.out.println("--------------------");
System.out.println("Search result:");
for (Item item : items_rep) {
System.out.println("id=" + item.getId() + " subject=" + item.getSubject()
+ " region=" + mapRegion.get(item.getRegionId())
+ " category=" + mapCategory.get(item.getCategoryId())
+ " price=" + item.getPrice());
}
// 打印所有facet
for (FacetField ff : facetFields) {
System.out.println("--------------------");
System.out.println("name=" + ff.getName() + " count=" + ff.getValueCount());
System.out.println("--------------------");
switch (ff.getName()) {
case "regionId":
printOut(mapRegion, ff.getValues());
break;
case "categoryId":
printOut(mapCategory, ff.getValues());
break;
}
}
}
@SuppressWarnings({ "rawtypes" })
private static void printOut(HashMap map, List<Count> counts) {
for (Count count : counts) {
System.out.println("name=" + map.get(Integer.parseInt(count.getName())) + " count=" + count.getCount());
}
System.out.println("--------------------");
}
private static Item makeItem(long id, String subject, String content, int regionId, int categoryId, float price,
long point, boolean vip) {
Calendar cale = Calendar.getInstance();
cale.setTime(new Date());
cale.add(Calendar.DATE, (int)id);
Item item = new Item();
item.setId(id);
item.setSubject(subject);
item.setContent(content);
item.setRegionId(regionId);
item.setCategoryId(categoryId);
item.setPrice(price);
item.setCreateTime(cale.getTime());
item.setPoint(point);
item.setVip(vip);
return item;
}
@SuppressWarnings("unchecked")
/**
* 重新将需要查询的文本内容解析成分词
* @param core
* @param searchText
* @return
* @throws SolrServerException
*/
private static String AnalysisSearchText(HttpSolrServer core, String searchText) throws SolrServerException {
StringBuilder strSearchText = new StringBuilder();
final String STR_FIELD_TYPE = "text_cn";
SolrQuery queryAnalysis = new SolrQuery();
queryAnalysis.add(CommonParams.QT, "/analysis/field"); // query type
queryAnalysis.add(AnalysisParams.FIELD_VALUE, searchText);
queryAnalysis.add(AnalysisParams.FIELD_TYPE, STR_FIELD_TYPE);
QueryResponse responseAnalysis = core.query(queryAnalysis);
//对响应进行解析
NamedList<Object> analysis = (NamedList<Object>) responseAnalysis.getResponse().get("analysis");// analysis node
NamedList<Object> field_types = (NamedList<Object>) analysis.get("field_types");// field_types node
NamedList<Object> fieldType = (NamedList<Object>) field_types.get(STR_FIELD_TYPE);// text_cn node
NamedList<Object> index = (NamedList<Object>) fieldType.get("index");// index node
List<SimpleOrderedMap<String>> list = (ArrayList<SimpleOrderedMap<String>>)index.get("org.wltea.analyzer.lucene.IKTokenizer");// tokenizer node
// 在每个词条中间加上空格,为每个词条进行或运算
for(Iterator<SimpleOrderedMap<String>> iter = list.iterator(); iter.hasNext();)
{
strSearchText.append(iter.next().get("text") + " ");
}
return strSearchText.toString();
}
}
说明:
a)AnalysisSearchText(...)方法:此方法会把需要查询的语句先使用分词分析,如上例子“出租花园”,调用AnalysisSearchText(...)后,会得到“出租 花园”,会把两个词分拆成以空格分隔的字符串。不然solr会以“出租花园”整体做为词做查询而得不到结果。
b)使用自定义的Handler,需要在代码中加入这句:
query.setRequestHandler("/browse");
对应的是solrconfig.xml中的requestHandler的:/browse
5、运行结果:
或者使用solr的query查询查看结果: