前言
本文是笔者学习“林晓斌”老师的《MySQL实战45讲》过程中的,对知识点的总结归纳以及对问题的思考记录,课程18年11月就出了,当时连载形式,我就上班途中一边开车一边听,学的比较糙,时隔两年现在再回头仔细回顾总结下。《MySQL实战45讲》是极客时间的收费课程,价格几十块并不贵,但是绝对是一个好课程,笔者收益颇深,推荐大家阅读。
第一章《一条查询SQL是如何执行的》总结
在第一篇文章中,作者主要通过一条查询SQL是如何执行的为出发点,介绍了MySQL的组成部分,每个部分做哪些事:
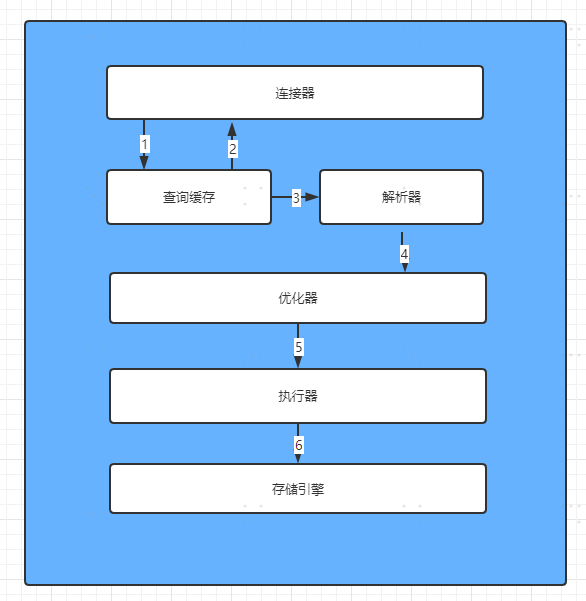
名词解释
连接器:主要管理与客户端的连接,鉴权以及安全性的校验工作。
查询缓存:MySQL为了提高查询效率,可能会将热点数据放入内存中,以便下次查询直接从查询缓存中返回数据。
分析器:当缓存中没有命中,就会想通过分析器,对SQL进行语法分析,是否合法等。
优化器:主要工作就是查询动作的优化,比如是否走索引,选择哪一个索引等。
执行器:负责执行SQL的部分,通过接口与存储引擎交互,获取查询结果并返回。
存储引擎:负责MySQL的数据存储和提取,索引结构都是有存储引擎定义的,并且是可拔插式的,用户可以根据自己需求选择不同的存储引擎,主要有InnoDB和MyISMA,MySQL5.5.5之后默认使用的是InnoDB。
执行步骤
那么一条查询SQL时如何通过这些组件执行的呢?
1、首先客户端需要连接到MySQL服务端,这时就需要连接器来验证用户名和密码,建立TCP连接了。连接后如果连接长期处理空闲状态,连接器就会自动断开他,默认是8小时,可以通过wait_timeout设置。
2、连接成功后,客户端向MySQL发送执行命令,比如发送一条查询语句:SELECT * FROM user WHERE id = 1;首先MySQL会在查询缓存中看是否存在该条数据的缓存,如果有就直接返回。没有则进入下一步。其实查询缓存在8.0版本后就移除了,因为查询缓存会在更新时全部清空,所以对于更新频率较高的场景,查询缓存会变得费力不讨好了,也可以通过query_cash_type设置成DEMAND禁用查询缓存。
3、先经过分析器,对改条SQL进行语法分析,是否符合语法规范,是查询语句还是更新语句等,是需要对哪张表进行操作。
4、之后通过优化器,发现id是主键,可以使用主键索引。
5、通过执行器,执行该条SQL之前会先校验有没有执行权限,如果有,执行器会通过该表存储引擎提供的接口,存储引擎通过索引树找出id=1的数据后,MySQL返回给客户端。
第二章《一条更新SQL是如何执行的》总结
上一章我们通过查询流程了解了MySQL各模块的功能,其实更新时也查不多,只不过为了保证数据的可恢复性引入了两个日志:redo_log和bin_log。那么为什么需要有这两个日志呢?
redo_log
首先redo_log是innoDB引擎提供的。当有数据更新或者插入时,innoDB并不是直接持久到磁盘,而是先修改缓冲池中的数据,成功后直接返回成功,再选择“合适的时机”刷入磁盘中。
那么有的同学就会问了,那如果内存中的数据还没来及刷到磁盘就crash(宕机)了,数据不就是丢失了吗?
是的,为了解决这个问题,innoDB引入了redo_log来解决这个问题。
当有插入更新请求时,innoDB先将结果写入的redo_log日志文件中,再修改缓冲池数据页,最后再适当的时候刷新到磁盘。这样即使宕机时,也可以通过redo_log恢复丢失的数据,这就是所谓的WAL技术 write-ahead-logging。
redo log在innoDB中是固定大小的,由4个1G的文件组成,所以redo log 是循环写的。
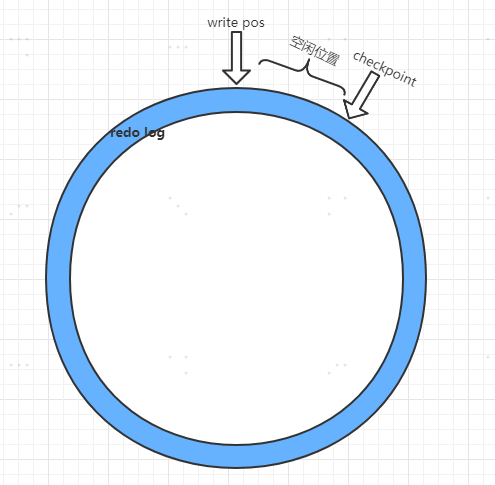
可以把染色环装理解为由4个redo log 文件组成的。
checkpoint:当前数据擦除的位置,擦除前要把记录更新到数据文件。
write pos:当前记录的位置。
checkpoint与write pos之间就是空闲部分,可以持续往后写,当write pos追上checkpoint时,说明文件都没写满,如果继续写,就需要停下来擦除一些数据,把checkpoint继续往前移。
有了redo log,innoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
这里做个扩展:当数据库写物理页时,如果宕机了,那么可能会导致物理页的一致性被破坏。
可能有人会说,重做日志不是可以恢复物理页吗?实际上是的,但是要求是在物理页一致的情况下。
也就是说,如果物理页完全是未写之前的状态,则可以用重做日志恢复。如果物理页已经完全写完了,那么也可以用重做日志恢复。但是如果物理页前面2K写了新的数据,但是后面2K还是旧的数据,则种情况下就无法使用重做日志恢复了。
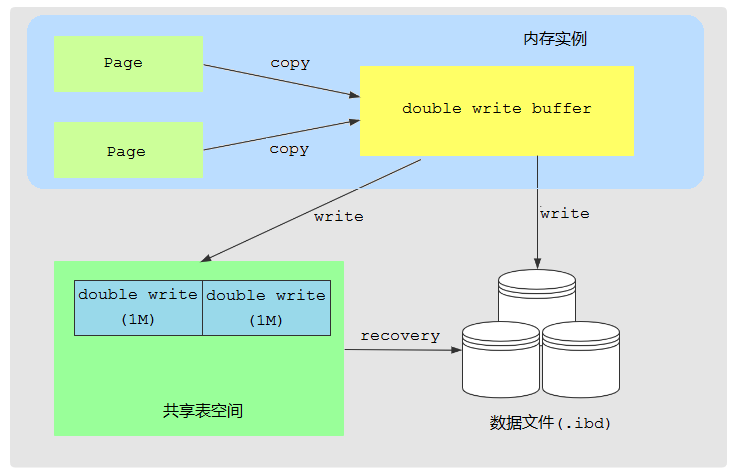
这里的两次写就是保证了物理页的一致性,使得即使宕机,也可以用重做日志恢复。
在写物理页时,并不是直接写到真正的物理页上去,而是先写到一个临时页上去,临时页写完后,再写物理页。这样一来:
A. 如果写临时页时宕机了,物理页还是完全未写之前的状态,可以用重做日志恢复
B. 如果写物理页时宕机了,则可以使用临时页来恢复物理页
InnoDB中共享表空间中划了2M的空间,叫做double write,专门存放临时页。
InnoDB还从内存中划出了2M的缓存空间,叫做double write buffer,专门缓存临时页。
每次写物理页时,先写到double write buffer中,然后从double write buffer写到double write上去。最后再从double write buffer写到物理页上去。
bin_log
binlog是MySQL的server层提供的,是跨存储引擎的,做归档用的。因为没有crash-safa能力,所以innoDB自己引入了redolog。
这两种日志有以下三点不同。
1 . redolog是innoDB引擎特有的;binlogg是MySQL的Server 层实现的,所有引擎都可以使用。
2 . redolog是物理日志,记录的是“在某个数据页上做了什么修改”,mysql 数据最终是保存在数据页中的,物理日志记录的就是数据页变更 。binlogg是逻辑日志,记录的是这个语句的原始逻辑,比如“给ID= 2这一行的c 字段加1 ”。
3 . redolog是循环写的,空间固定会用完;binlogg是可以追加写入的。“追加写”是指binlogg文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
更新语句的执行流程
1、当MySQL接收到一条更新语句时update user name="老王" where id =1;,除了上面查询的那些前期步骤,执行器调用存储引擎接口获取到id=1 的数据。
2、执行器获取数据后,先将name改为老王的数据,调用引擎接口,将数据写入到redolog中,并处于prepared状态。
3、redolog写完后,修改缓冲池的数据。并返回给执行器。
4、执行器获得结果后,记录到binlog中,并修改redolog该条记录改为commit状态,更新完成。
之所以分两次修改redolog是为了与binlog保证数据一致。
第三章《事务隔离》
事务基本概念
这章节没什么好说的,主要介绍了事务的特性,隔离级别以及事务的实现。
说到事务,大家都知道ACID,即原子性,一致性,隔离性,持久性。
多个事务操作同一数据,可能出现的问题:
脏读:一个事务读取到的另一个事务没有提交的数据。
不可重复读:在一个事务中两次读取同一数据结果不一致。
幻读:在一个事务中两次读取数据的数量不一致。
隔离级别
读未提交:可以读到另一个事务中没有提交的数据。
读已提交:可以读到另一个事务已提交的数据。
可重复读:在一个事务中,即使另一个事务已提交了,在本事务中多次读取数据都是跟事务启动时读取的一致的。
串行化:最高的隔离级别,对同一行数据,读会加读锁,写会加写锁,最安全但效率也最低。
事务的实现
在事务开启时,生成一张视图,在事务执行期间读取的数据都是基于这张视图的,这是静态的并不受其他事务影响。
本质上,在MySQL中,当数据发生更新时,都会生成一条回滚操作,通过回滚操作可以获得操作前的状态,在事务中,每次操作都会被记录,直至事务被提交,回滚段才会被清理。所以在未提交之前,都可以通过回滚日志undo log,逐步将数据恢复到事务开启前的状态。
在5.5版本之前,回滚日志是保存在ibdata文件中的,日志回滚段被清理,文件大小也不会变,所以日常开发中,我们应该尽量避免长事务,应该在长事务中会保留很老的视图。