1、概述
1TB排序通常用于衡量分布式数据处理框架的数据处理能力。Terasort是Hadoop中的的一个排序作业,在2008年,Hadoop在1TB排序基准评估中赢得第一名,耗时209秒。那么Terasort在Hadoop中是怎样实现的呢?本文主要从算法设计角度分析Terasort作业。
2、算法思想
实际上,当我们要把传统的串行排序算法设计成并行的排序算法时,通常会想到分而治之的策略,即:把要排序的数据划成M个数据块(可以用Hash的方法做到),然后每个map task对一个数据块进行局部排序,之后,一个reduce task对所有数据进行全排序。这种设计思路可以保证在map阶段并行度很高,但在reduce阶段完全没有并行。


为了提高reduce阶段的并行度,TeraSort作业对以上算法进行改进:在map阶段,每个map task都会将数据划分成R个数据块(R为reduce task个数),其中第i(i>0)个数据块的所有数据都会比第i+1个中的数据大;在reduce阶段,第i个reduce task处理(进行排序)所有map task的第i块,这样第i个reduce task产生的结果均会比第i+1个大,最后将1~R个reduce task的排序结果顺序输出,即为最终的排序结果。这种设计思路很明显比第一种高效,但实现难度较大,它需要解决以下两个技术难点:第一,如何确定每个map task数据的R个数据块的范围? 第二,对于某条数据,如果快速的确定它属于哪个数据块?答案分别为【采样】和【trie树】。
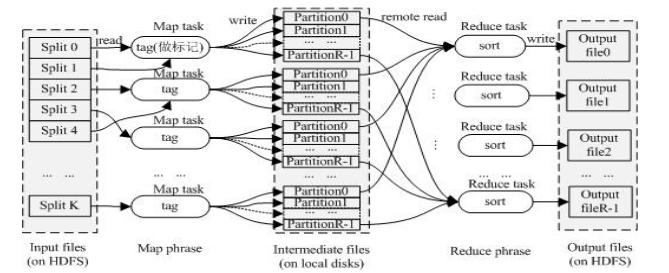

3、Terasort算法
3.1 Terasort算法流程
对于Hadoop的Terasort排序算法,主要由3步组成:采样 –>> map task对于数据记录做标记 –>> reduce task进行局部排序。
数据采样在JobClient端进行,首先从输入数据中抽取一部分数据,将这些数据进行排序,然后将它们划分成R个数据块,找出每个数据块的数据上限和下线(称为“分割点”),并将这些分割点保存到分布式缓存中。
在map阶段,每个map task首先从分布式缓存中读取分割点,并对这些分割点建立trie树(两层trie树,树的叶子节点上保存有该节点对应的reduce task编号)。然后正式开始处理数据,对于每条数据,在trie树中查找它属于的reduce task的编号,并保存起来。
在reduce阶段,每个reduce task从每个map task中读取其对应的数据进行局部排序,最后将reduce task处理后结果按reduce task编号依次输出即可。
3.2 Terasort算法关键点
(1)采样
Hadoop自带了很多数据采样工具,包括IntercalSmapler,RandomSampler,SplitSampler等(具体见org.apache.hadoop.mapred.lib)。
采样数据条数:sampleSize = conf.getLong(“terasort.partitions.sample”, 100000);
选取的split个数:samples = Math.min(10, splits.length); splits是所有split组成的数组。
每个split提取的数据条数:recordsPerSample = sampleSize / samples;
对采样的数据进行全排序,将获取的“分割点”写到文件_partition.lst中,并将它存放到分布式缓存区中。
举例说明:比如采样数据为b,abc,abd,bcd,abcd,efg,hii,afd,rrr,mnk
经排序后,得到:abc,abcd,abd,afd,b,bcd,efg,hii,mnk,rrr
如果reduce task个数为4,则分割点为:abd,bcd,mnk
(2)map task对数据记录做标记
每个map task从文件_partition.lst读取分割点,并创建trie树(假设是2-trie,即组织利用前两个字节)。
Map task从split中一条一条读取数据,并通过trie树查找每条记录所对应的reduce task编号。比如:abg对应第二个reduce task, mnz对应第四个reduce task。

(3)reduce task进行局部排序
每个reduce task进行局部排序,依次输出结果即可。
4、参考资料
(1) hadoop的1TB排序terasort:
http://hi.baidu.com/dtzw/blog/item/cffc8e1830f908b94bedbc12.html
(2)Hadoop-0.20.2代码