数据结构
- 数据(data)是对客观事物符号表示,在计算机中是指所有能输入的计算机并被计算机程序处理的数据总称。
- 数据元素(data element)是数据的基本单位,在计算机中通常做为一个整体进行处理。
- 数据对象(data object)是性质相同的数据元素的集合,是数据的一个子集。
- 数据结构(data structure)是相互之间存在一种或多种特定关系的数据元素的集合。
- 数据类型(data type)是和数据结构密切关系的一个概念,在计算机语言中,每个变量、常量或者表达式都有一个所属的数据类型。
- 抽象数据类型(abstract data type ADT)是指一个数据模型以及定义在该模型上的一组操作,抽象数据类型的定义仅取决于它的一组逻辑性,与其在计算机内部如何表示以及实现无关
算法
算法是对特定问题求解的一种描述,它是指令的有限序列,其每一条指令表示一个或多个操作,算法还有以下特性:
- 有穷性
一个算法必须总是在执行有限步骤后的结果,而且每一步都可以在有限时间内完成。 - 确定性
算法中每一条指令都有确切的含义,读者理解时不会产生二义性,在任何条件下,算法只有唯一的一条执行路径,即相同的输入只能得出相同的输出。 - 可行性
一个算法是可行的,即算法中描述的操作都是可以通过已经实现的基本运算来实现的。 - 输入
一个算法有零个或者多个输入,这些输入取自与某个特定对象的集合。 - 输出
一个算法有一个或多个输出,这些输出是和输入有某些特定关系的量
链表
- 对于数组,逻辑关系上相邻的连个元素的物理位置也是相邻的,这种结构的优点是可以随机存储任意位置的元素,但缺点是如果从数组中间删除或插入元素时候,需要大量移动元素,效率不高
- 链式存储结构的特点,元素的存储单元可以是连续的,也可以是不连续的,因此为了表示每个元素a,与其接后的元素a+1之间的关系,对于元素a,除了存储其本身信息外,还需要存储一个指示其接后元素的位置。这两部分数据成为结点(node)
- 一个结点中存储的数据元素被成为数据域。存储接后存储位置的域叫做指针域。n个结点(ai(1<=i<=n)的存储映像链接成一个链表
- 整个链表必须从头结点开始进行,头结点的指针指向下一个结点的位置,最后一个结点的指针指向NULL
- 在链表中,通过指向接后结点位置的指针实现将链表中每个结点“链”到一起。链表中第一个结点称之为头结点
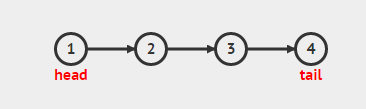
单向链表数据结构定义
struct list
{
int data;//链表数据域
struct list *next;//链表指针域
};
单向链表的实现
struct list *create_list()//建立一个节点
void traverse(struct list *ls)//循环遍历链表
struct list *insert_list(struct list *ls, int n, int data)//在指定位置插入元素
int delete_list(struct list *ls, int n)//删除指定位置元素
int count_list(struct list *ls)//返回链表元素个数
void clear_list(struct list *ls)//清空链表,只保留首节点
int empty_list(struct list *ls)//返回链表是否为空
struct list *locale_list(struct list *ls, int n)//返回链表指定位置的节点
struct list *elem_locale(struct list *ls, int data)//返回数据域等于data的节点
int elem_pos(struct list *ls, int data)//返回数据域等于data的节点位置
struct list *last_list(struct list *ls)//得到链表最后一个节点
void merge_list(struct list *st1, struct list *ls2)//合并两个链表,结果放入st1中
void reverse(struct list *ls)//链表逆置
- 建立一个节点
struct list *create_list()
{
return calloc(sizeof(struct list), 1);
}
- 实现图示节点创建
struct list *first = create_list();
struct list *second = create_list();
struct list *third = create_list();
first->next = second;
second->next = third;
//此处不用谢third->next指向,已经初始化为空
- 删除节点元素
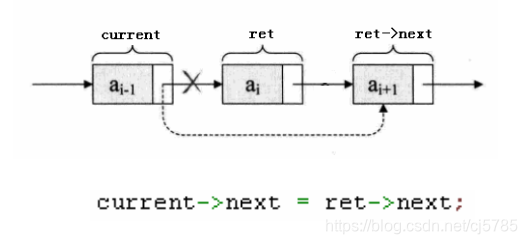
free(second);
first->next = third;
- 循环遍历列表
基础方法
void traverse(struct list *ls)
{
struct list *p = ls;
while(p)
{
printf("%d", p->data);//打印数据域内容
p = p->next;//指向下一个节点
}
}
递归实现
void traverse(struct list *ls)
{
if(ls)
{
printf("%d", ls->data);
traverse(ls->next);
}
}
- 在指定位置插入元素
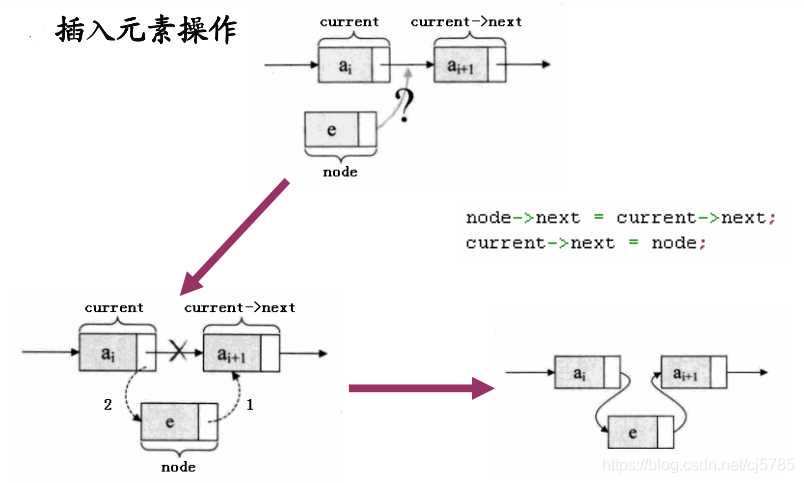
struct list *insert_list(struct list *ls, int n, int data)
{
struct list *p = ls;
while(p && n--)
p = p->next;
if(!p)
return NULL;//指向一个无效的位置
else
{
struct list *node = create_list();
node->date = date;
node->next = p->next;
p->next = node;
return node;
}
}
- 删除指定位置元素
int delete_list(struct list *ls, int n)
{
struct list *p = ls;
while(p && n--)
p = p->nest;
if(!p)
return 0;
else
{
struct list *node = p->next;
if(!node)
return 0;
p->next = node->next;
free(node);
return 1;
}
}
- 返回链表元素个数
int count_list(struct list *ls)//除首节点的有效节点
{
struct list *p = ls->next;
int count;
while(p)
{
p = p->next;
count++;
}
return count;
}
- 清空链表,只保留首节点
创建临时变量用以删除
void clear_list(struct list *ls)
{
struct list *p = ls->next;
while(p)
{
struct list *tmp = p->next;
free(p);
p = tmp;
}
ls->next = NULL;//**尾节点要指向NULL**
}
使用递归删除节点
void clear_list(struct list *ls)
{
if (ls->next)
{
ls = ls->next;
clear_list(ls);
free(ls);
}
}
- 返回链表是否为空
int empty_list(struct list *ls)
{
if(ls->next)
return 1;
else
return 0;
}
- 返回链表指定位置的节点
struct list *locale_list(struct list *ls, int n)
{
struct list *p = ls;
while(p && n--)
p = p->next;
return p;
}
- 返回数据域等于data的节点
struct list *elem_locale(struct list *ls, int data)
{
struct list *p = ls;
while(p)
{
if(p->data == data)
break;
p = p->next;
}
return p;
}
- 返回数据域等于data的节点位置
int elem_pos(struct list *ls, int data)
{
struct list *p = ls;
int index = 0;
while(p)
{
if(p->data == data)
break;
p = p->next;
index++;
}
return index;
}
- 得到链表最后一个节点
用临时节点存储上一节点
struct list *last_list(struct list *ls)
{
struct list *p = ls;
struct list *pre = p;
while(p)
{
pre = p;
p = p->next;
}
return pre;
}
判断是否为最后一个节点
struct list *last_list(struct list *ls)
{
struct list *p = ls;
while(p->next)
{
p = p->next;
}
return p;
}
- 合并两个链表,结果放入st1中
void merge_list(struct list *st1, struct list *ls2)
{
struct list *last = last_list(st1);
last->next = st2->next;
free(st2);
}
- 链表逆置
两种思路,交换数据域和交换指针域
- 判断首节点的next是否为NULL;
- 判断首节点next的next是否为空,如果为空证明链表除首节点之外只有一个节点,所以不需要逆置;
- 定义一个指针last,指向首节点的next域,因为逆置之后,该域为链表尾节点;
- 定义三个指针,分别代表前一个节点,当前节点,下一个节点;
- 前节点指向链表首节点;
- 当前节点指向链表首节点的next域;
- 下一个节点为NULL;
- 循环条件判断当前节点是否为NULL,如果为NULL退出循环;
a) 下一个节点指向当前节点的下一个节点;
b) 当前节点的下一个节点指向前一个节点;
c) 前一个节点指向当前节点;
d) 当前节点指向下一个节点; - 循环完成;
- 设置last节点的next为NULL;
- 设置链表首节点的next为前一个节点
void reverse(struct list *ls)
{
if (!ls->next)
return;//只有首节点,不需要逆置
if (!ls->next->next)
return;//除了首节点,就一个有效节点
struct list *pre = ls;//前一个节点的指针
struct list *cur = ls->next;//当前节点的指针
struct list *next = NULL;//指向下一个节点的指针
struct list *last = ls->next;//因为逆置完成后,首节点的next就成了最后一个节点
while(cur)
{
next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
last->next = NULL;
ls->next = pre;
}
排序
排序方式很多种,最基础的冒泡排序和选择排序必须要会
冒泡排序
- 冒泡排序首先将一个记录的关键字和第二个记录的关键字进行比较,如果为逆序
(elem[1] > elem[2]),则两个记录交换之,然后比较第二个记录和第三个记录的关键字,以此类推,直到第n - 1个记录和第n个记录的关键字进行过比较为止 - 上述过程称作第一次冒泡排序,其结果是将关键字最大的记录被安排到最后一个记录的位置上。然后进行第二次冒泡排序,对前
n - 1个记录进行同样操作,其结果是使关键字第二大记录被安置到第n - 1位置上。直到将所有记录都完成冒泡排序为止
int arr[9] = { 5, 3, 6, 2, 8, 4, 9, 7, 1 };
int i,j,len;
len = sizeof(arr) / sizeof(int);
for(i = 0; i < len; i++)
{
for(j = 0; j < len - i - 1; j++)
{
if(arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
选择排序
- 选择排序是每一次在
n – i + 1(i = 1,2,…n)个记录中选取关键字,最小的记录作为有序序列中第i个记录 - 通过
n - i次关键字间的比较,从n - i + 1个记录中选取出关键字最小的记录,并 和第i(1<=i<=n)个记录交换之
int arr[9] = { 5, 3, 6, 2, 8, 4, 9, 7, 1 };
int i,j,suf,tmp,len;
len = sizeof(arr) / sizeof(int);
for(i = 0; i < len; i++)
{
suf = i;//查找最值的下标
for(j = i + 1; j < len; j++)
if(arr[suf] > arr[j])
suf = j;//交换
if(suf != i)
{
tmp = arr[suf];
arr[suf] = arr[i];
arr[i] = tmp;
}
}
选择排序重要的实现思想,即挨个比较,然后找到最小,故以下实现也属于选择排序
int arr[9] = { 5, 3, 6, 2, 8, 4, 9, 7, 1 };
int i,j,len;
len = sizeof(arr) / sizeof(int);
for(i = 0; i < len; i++)
{
for(j = i + 1; j < len; j++)
{
if(arr[i] > arr[j])
{
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
}
}
查找
查找最常用的两种:顺序查找和二分查找
顺序查找
顺序查找的过程为:从表的最后一个记录开始,逐个进行记录的关键字和给定值比较,如果某个记录的关键字与给定值相等,则查找成功,反之则表明表中没有所查找记录,查找失败
int arr[10] = { 5, 6, 3, 4, 2, 8, 9, 7, 1 };
int i;
for(i = 0; i < 10; i++)
if(7 = arr[i])
printf("数组中存在7");
二分查找
在一个已经排序的顺序表中查找,可以使用二分查找来实现。
二分查找的过程是:先确定待查记录所在的范围(区间),然后逐步缩小查找范围,直到找到或者找不到该记录为止。
假设指针low和high分别指示待查找的范围下届和上届,指针mid指示区间的中间值,即 mid=(low + high) / 2
二分查找时候,常规方法效率更高
常规实现
int binSearch(int array[],int low,int high,int target)
{
while(low <= high)
{
int mid = (low + high) / 2;//得到中间下标
if(array[mid] > target)
high = mid - 1;
else if(array[mid] < target)
low = mid + 1;
else
return mid;
}
return -1;
}
递归实现
int binSearch(int array[],int low,int high,int target)
{
if(low <= high)
{
int mid = (low + high) / 2;//得到中间下标
if(array[mid] == target)
return mid;
else if(array[mid] < target)
return binSearch(array, low, mid - 1, target);
else
return binSearch(array, mid + 1, high, target);
}else
return -1;
}