在最近工作中,有因后台接口升级,前端需要配合改造的需求。在改造适配过程中,遇到了问题,再经过多次折腾后,最终调通。事后再回顾整个调试过程,觉的之前走过一些弯路,在回顾时才看的更加真切,在此需要总结归纳。
问题背景
先描述下问题背景,为简化后续讨论,后续以"查产品信息"和"查资金"两个接口为例子,后台对这两个接口有升级,具体包括
- "查产品信息"接口,优化内部实现,认证方式是参数签名。
- "查资金"接口升级,接口出入参没变,认证方式改为授权码,该授权码由另一个认证服务提供,不同服务的授权码不一样。
问题描述
旧版本的流程如下:
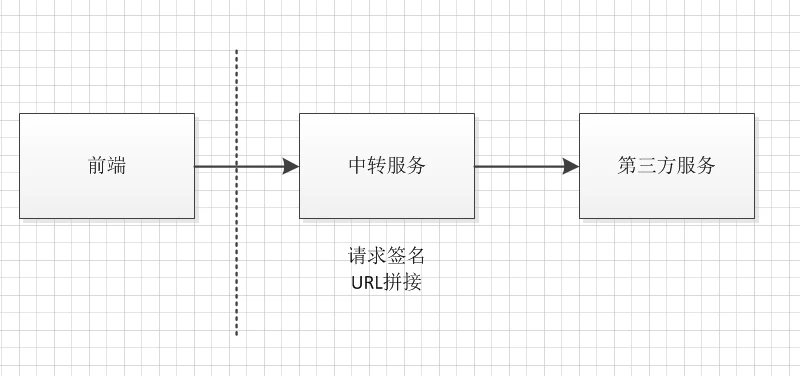
前端没有关心参数签名细节,将参数一股脑传给中转服务,由中转服务完成对签名操作,并将签名值附加在请求最后。
该中转服务是其他同事负责的,前端没有关心细节。
后台改造升级,新的流程如下:
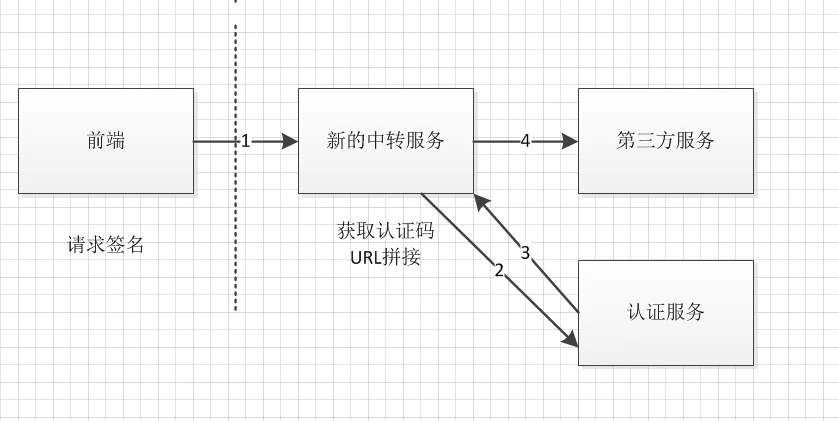
针对"查资金"接口,需要先向认证服务获取认证码,该认证码的权限很大,为了安全起见,获取认证码的操作放到中转服务中。这个中转服务是新写的,考虑到兼容对参数签名接入的兼容,对请求参数进行签名的职责交给前端。
按照上面新流程进行开发,很顺利。到联调阶段,发现走参数签名的方法总是失败,返回“签名不通过”的问题。
问题分析流程
根据接口文档的描述,参数签名的接入需要送两个特殊的参数:
- RandomKey: 由登陆相关参数拼接而成
- AppKey :由所有url请求参数按照指定规则拼接而成
旧版本的这两个参数是有中转服务来拼接,新版改为前端拼接,这里最初遗漏了对AppKey的处理,后来在新中转服务中,参照旧版实现,补充对AppKey的处理,发现还是返回“签名不通过”,这就奇怪了。
在调试遇到阻碍,无法进行下去时,通过询问同事以及旧模块的维护人员,静下心来分析,
旧版本是正常的,新版本返回签名不通过,新旧版本对接同一个第三方服务,那唯一的可能是新旧版本请求串不一样。
对比新旧请求url的异同,终于发现突破点,可能是 RandomKey 的问题。
新版本:RandomKey=inputtype%3dC%26inputid%3d123456%26custorgid%3d1000%26orgid%3d1100%26tradenode%3d9501%26ext1%3d0000%26userinfo%3d~~~1100%26authid%ABCDEFD
旧版本:RandomKey=authid%ABCDEFD%26custorgid%3D1000%26ext1%3D1000%26inputid%3D123456%26inputtype%3DC%26orgid%3D1100%26tradenode%3D9501%26userinfo%3D~~~1100
经过对比发现,新旧版本的RandomKey中构成元素是一样的,唯一区别在于顺序。旧版本是按照字母序进行排列,新版本是按照接口文档规定的顺序排列。
为什么按照接口文档规定的顺序无法访问,按照字母序可以访问呢?旧版本中对random进行字母序排列的依据是什么?带着这些疑问,进一步询问相关人员,发现三个问题:
- 接口文档中对randomkey中顺序没有明确要求,但在验证时隐含了此要求
- 旧的实现对第三方接口隐含的缺陷进行了兼容处理,而没有对此兼容处理做显式说明,导致后续维护人员踩入同样的坑
- 旧的实现在对接口签名时,有一些和前端的约定,比如编码是由哪一方来做,顺序是有哪一方来保证
问题解决方案
分析得到问题根源后,顺藤摸瓜,解决方案也就出来了。由前端或者中转服务来对Random进行处理,为了后续的灵活性,此处由中转服务来处理,前端无需关系。
知识点梳理
url编码知识
url标准规定,url采用ASCII码,RFC3986文档规定:Url中只允许[0-9a-zA-Z]、“-_.~”4个特殊字符以及所有保留字符(用于分隔不同组件),每个特殊符号有特定含义:
- 冒号":"用于分隔协议和主机
- "/"号用于分隔主机和路径
- "?"用于分隔路径和入参
- "="用于键值对区分
- "&"区分多个键值对
如遇到不安全的字符,使用安全字符来代替。例如中文,上述特殊字符。
为了不对内容有依赖,在拼接url时,需要对path、key和value进行utf8编码(解决中文传输问题),再对进行url编码(解决key或value中有可能包含URL特殊符号,引起后端解析错误)。
base64编码
base64是将非ASCII数据转换为ASCII数据的一种方法,编解码速度快,目的是:
- 兼容某些只能处理ASCII字符的系统。
- 解决传输设备(路由器、交换机)对不可见字符处理不一致而引发的问题
- 简单加密方式
有些Base64编码方案中包含url中的"+/="字符,采用这种方案,需要先进行base64编码,再进行url编码。
如果是针对Url特殊字符改进版的Base64编码,可不考虑先后顺序。
浏览器请求
以chrome为例子,当url请求中带有中文时,例如: “https://baike.baidu.com/item/春节/136876?fr=aladdin” 实际送的是"https://baike.baidu.com/item/春节/136876?fr=aladdin",其中,"春节"两字的先进行utf8编码,然后进行url编码。
对url中的key和value也是同样的处理方式。
小结
通过本次调试过程的梳理,有以下几点经验和思考:
- 后端在对接第三方服务时,要是发现接口描述不清,在经过沟通后发现需要特殊处理才能跑通,一定要敦促他们完善接口文档,这是最佳选择。
- 后端在遇到需要特殊处理的地方,要将处理依据以及对接人,明确写在注释以及提交记录上,让后续维护者了解此处的坑。
- 当前端在承接一些后台职责时,光看接口文档时是不够的,有时候后台会对接口中的缺陷进行隐含处理,错错得正,给前端造成一种错觉,觉的按照接口文档来,那就一定没问题的。
- 前后端联合开发时,一定要划分清楚职责并如实记录,哪里负责编码,哪些负责附加字段等问题,要在概要设计时,就明确下来。
- 编码问题,不能依着结果是一致就不去编码,面向逻辑开发,而不是结果开发。不能因为简单的几个例子跑对了,就不去管逻辑上可能的遗漏。