Introduction
准备做一个feature map浏览器,可以做些intuitive的观察。code在这里(tool目录下放的支持变形输入的module.py模块)。
可以支持对feature map和softmax output的浏览,其中feature map用了简单的平均化方法(可视化之前进行了归一化),这一方法似乎简洁有效,之前有fine grained的任务是照此进行的。
Similar Map
测试的时候,有一项是对feature map进行操作,用的是vgg16。偶然间发现没有经过mean处理的输入产生的feature map和经过的看起来没有什么区别,而probability有明显的变化。
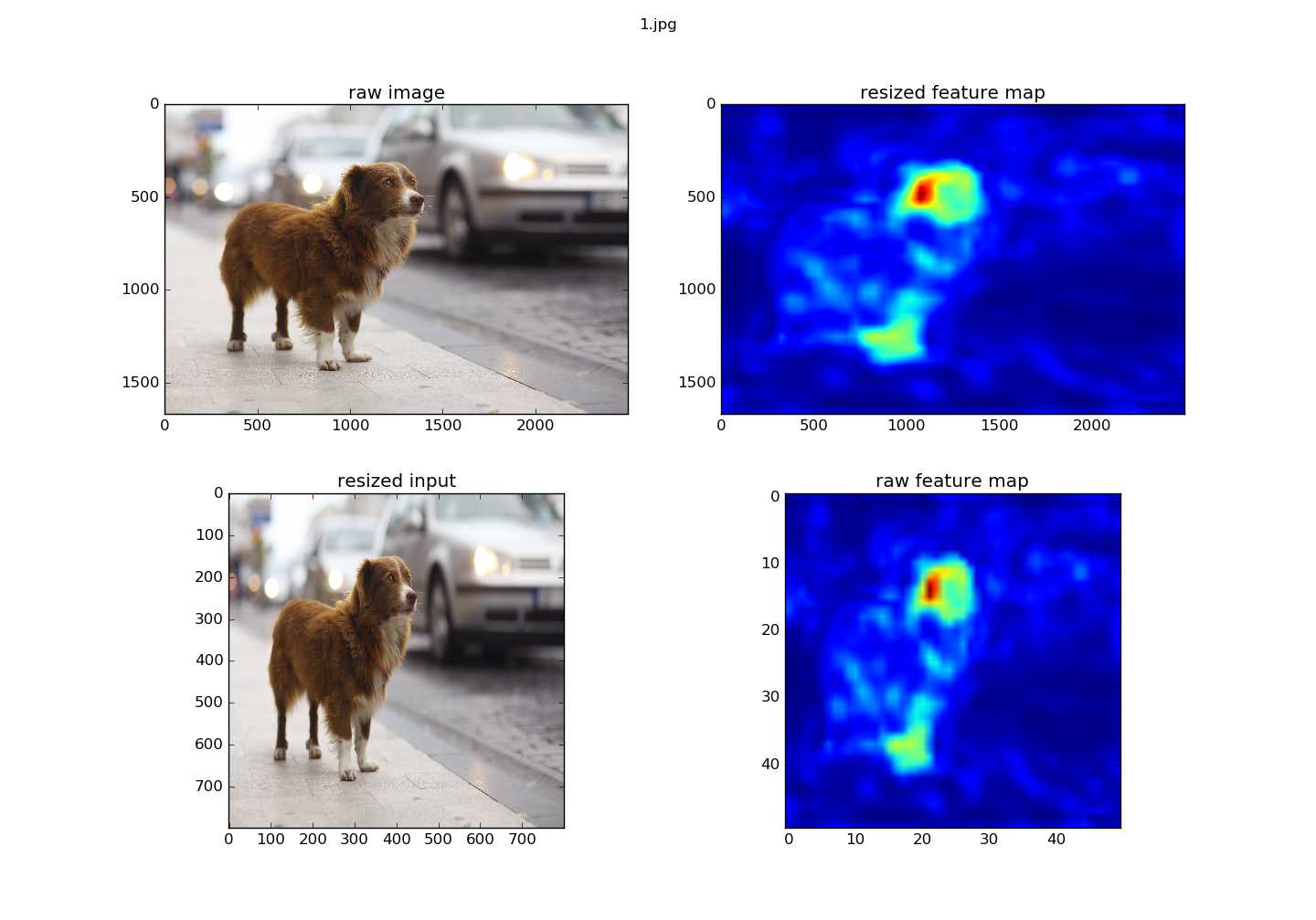 Figure 1. 经过中心化的featuremap
Figure 1. 经过中心化的featuremap
 Figure 2. 原图数据输入获得的featuremap
Figure 2. 原图数据输入获得的featuremap
 Figure 3. Histogram-经过中心化的featuremap
Figure 3. Histogram-经过中心化的featuremap
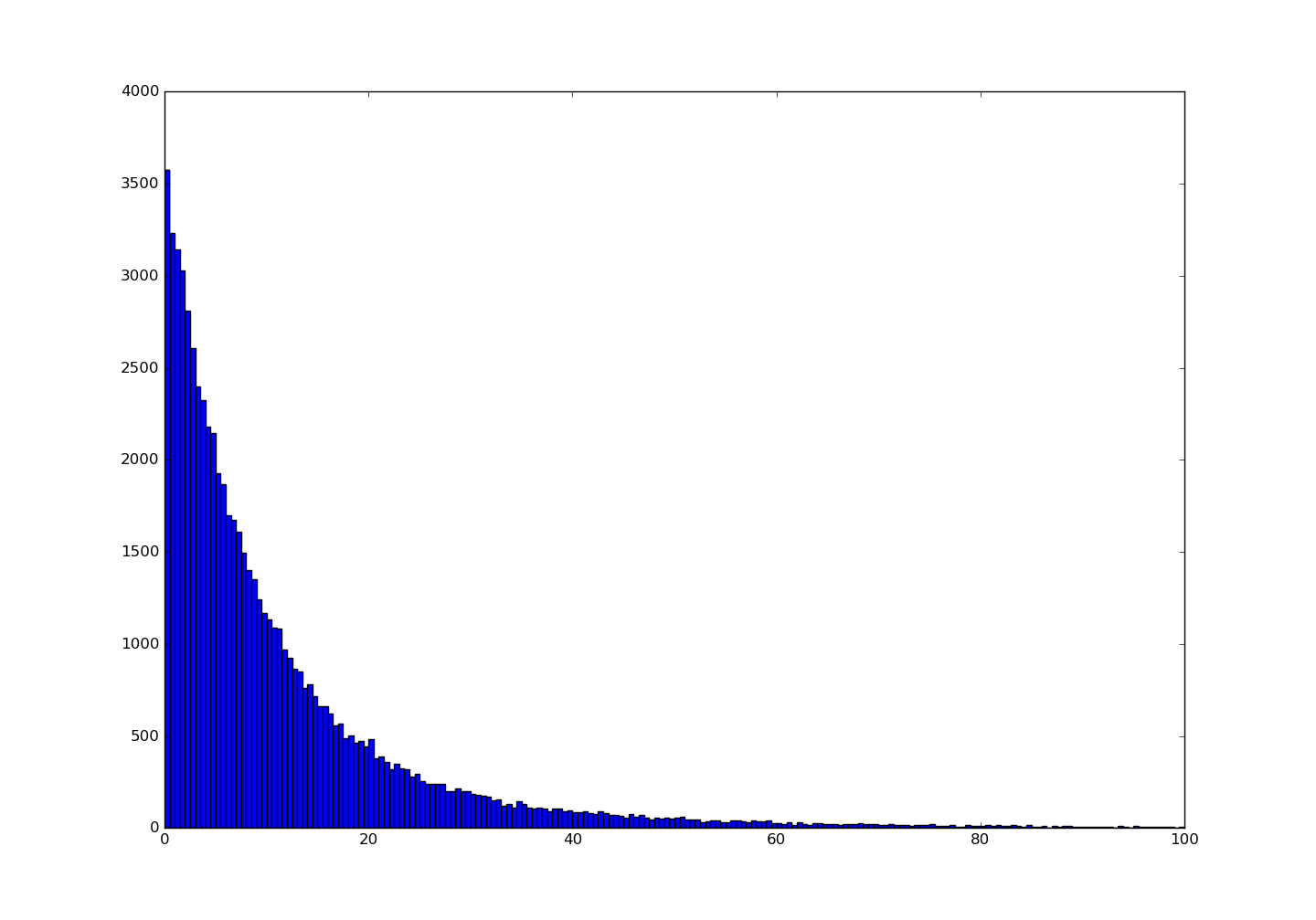 Figure 4. Histogram-原始图数据的featuremap
Figure 4. Histogram-原始图数据的featuremap
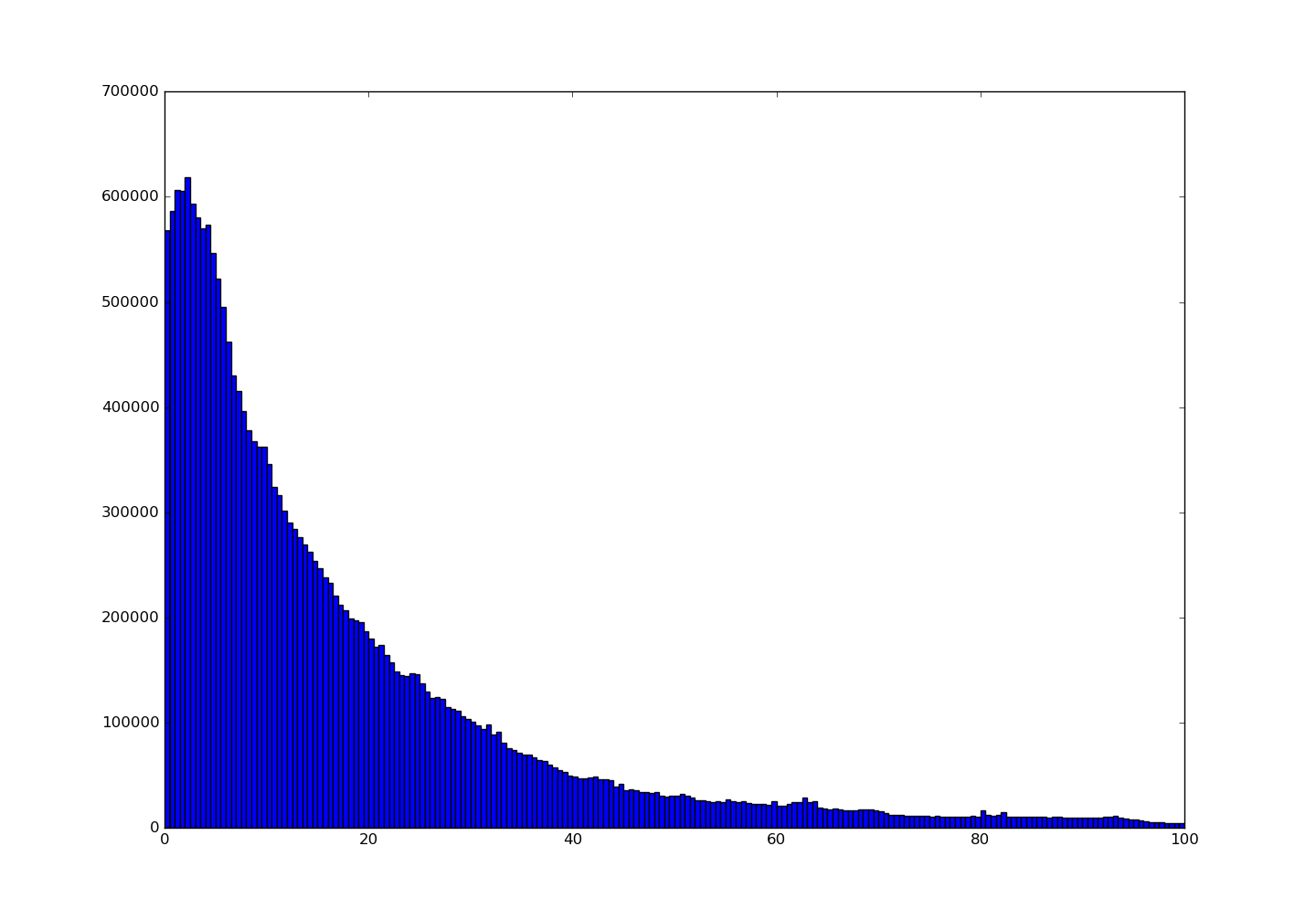 Figure 5. with *mean*
Figure 5. with *mean*
 Figure 6. no *mean*
Figure 6. no *mean*
方差
如果方差计算出来也是相同的,那么理论与观察又产生了一种成就感。
ef{eq:var1}中第二项根据相关假定,归结为(0),第一项,由独立假定处理。简化为:
这说明方差与(x)的均值是有关的。
考虑均值还是比较大的((150~vs.~[0,255])),所以,在两种情况下,情况应该是不同的,而且应该是有比较明显的不同。
Bias
这里考虑一下bias存在的情况,此种情况对应 ef{eq:var1}中右式加上标量(b),容易得出,bias对方差的计算没有影响。
关于方差的进一步考察
上面关于方差的计算在我的直觉上,感觉是一致的,但却与观察上有冲突;我把推导的结论和大师兄讨论了下,他表述了不一样的直觉。我打算先把第一个conv的输入/输出做些对比。
 Figure 7. distribution of the conv1_1's output with subtracting *mean*
Figure 7. distribution of the conv1_1's output with subtracting *mean*
下图是没有经过减均值处理的输出分布:
 Figure 8. distribution of the conv1_1's output **without** subtracting *mean*
Figure 8. distribution of the conv1_1's output **without** subtracting *mean*
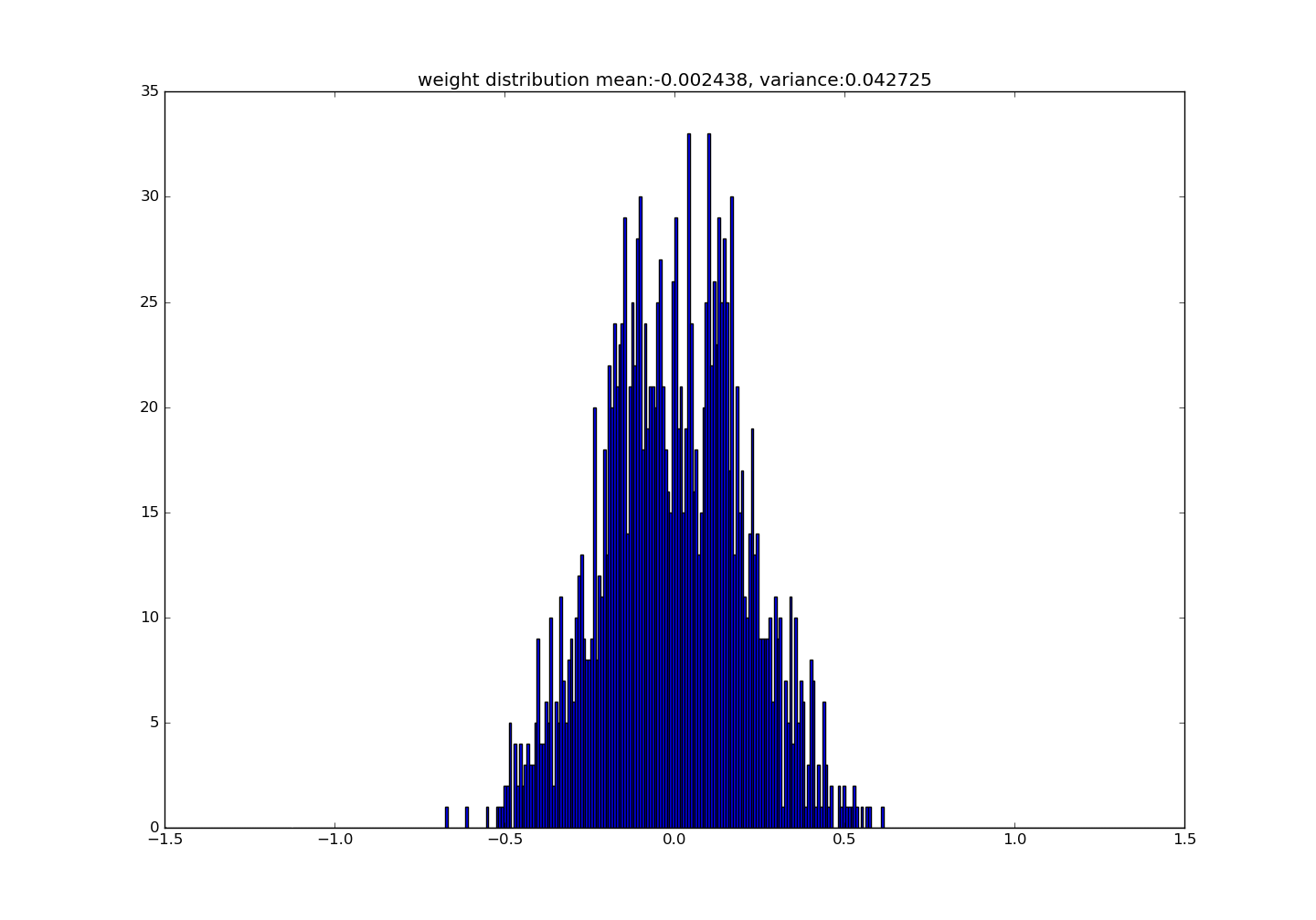 Figure 9. distribution of the conv1_1's weight**
Figure 9. distribution of the conv1_1's weight**
下面这张是原始图像的分布(实际上这里只需要关注方差的变化了,所以是否经过减均值处理并不影响后面想要得出的结论)
 Figure 10. distribution of the raw input image
Figure 10. distribution of the raw input image
Mathematical Formulation
数据已经足够,在开始进行数值验证前,再做一些假设以及验证方法的说明。
Note1
ef{eq:mean}是对某一分量进行的求解,在此处,假定所有(y_i)都是独立同分布的,这样就变成对单个随机变量的求解,记这个随机变量为(y);同理,设置随机变量(w,x),并且用一个常量(c)替换求和操作,于是改写
ef{eq:mean}:
Note2
再用(hat{y})表示经过中心化后的变量(z)经过卷基层后的输出随机变量:
Note3
于是验证的方法是比较通过
ef{eq:re-formulation-var-x}和
ef{eq:re-formulation-var-z}计算出来的(c)是否一致。
ef{eq:re-formulation-var-x}:
ef{eq:re-formulation-var-z}:
另外,看看(c)的意义,按照
ef{eq:mean},c应该是元素个数,第一层conv核尺寸为3x3,通道数为3,考虑到稀疏分布,一半应该算正常。
Conclusion
- 在这次讨论中,直观上看起来改变不大的分布,其方差却有了巨大改变,这是产生一种冲突的缘由;
- 正态分布的假设在实际数值计算中仍然有相当的效用;
- 过程中还发现,对变量的认定将影响数值方法的验证感受,比如对由两个满足正态分布的随机序列逐点相乘得到的序列的
和与均值,会发现两者给人的感受有很大差异。
Postscript
这个问题持续了一段时间,我最开始只是想对featureMap Viewer的code做些小结,顺便贴些图片,后面偶然发现两种特征图有极为相似的视觉感受,开始讨论了下相关的数学原理,本来以为结束了,回去却突然发现得出结论的逻辑刚好弄反了(第二天赶忙过来撤下),于是陷入某种僵局,最后发现Conclusion第三条中的观点,后面从直接的输入输出进行了验证。
这是一个与直觉有冲突的现象。看起来迷乱的猜测最后被计算贯彻。但也可以注意到softmax的输出并不是正态分布的(这很容易想象到,其分布应该相近与一个dirac函数)。
另外,像前面提到的Kaiming He的工作,提供了一些最初的想法。
References
- He, Kaiming, et al. "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification." international conference on computer vision (2015): 1026-1034.