手机APP测试

Linux

接口自动化框架
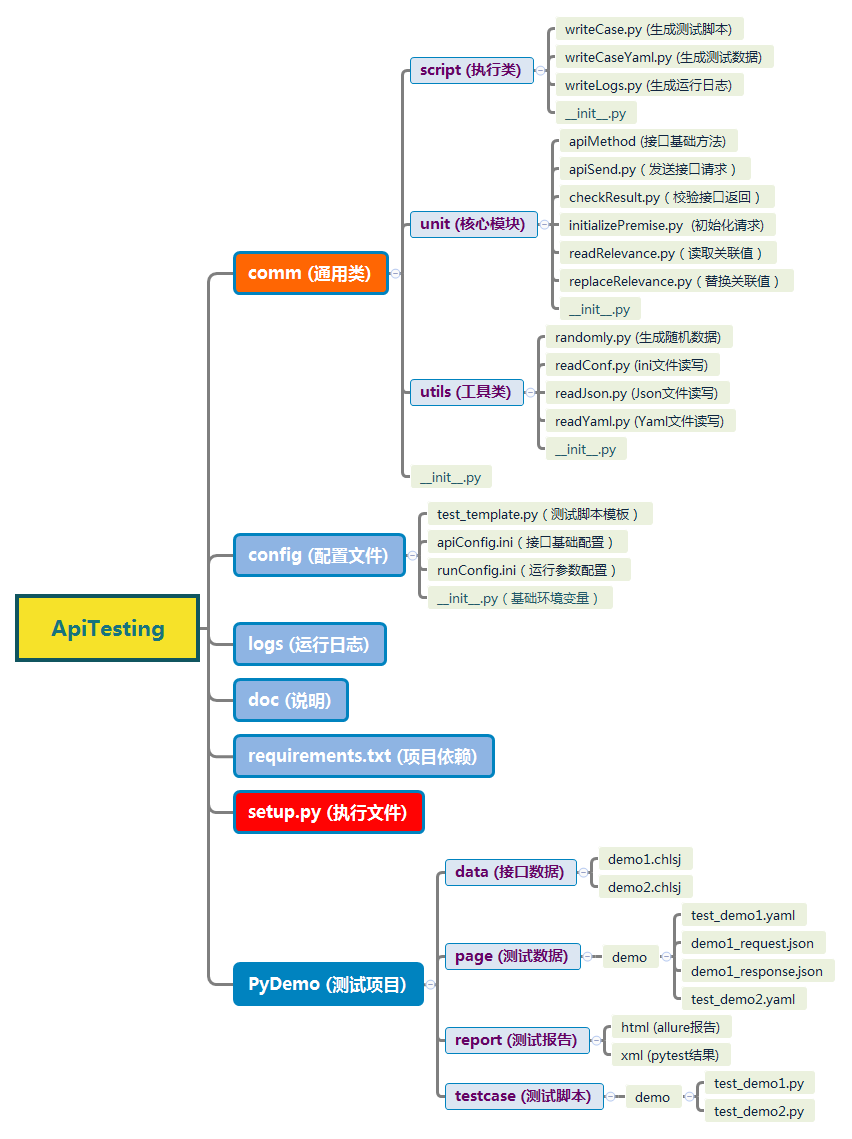
Web自动化测试框架

Web自动化学习
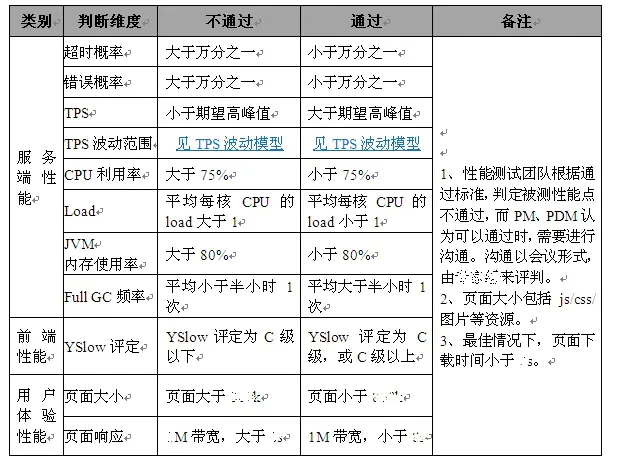
性能测试指标
Jmeter系列之Jmeter+Grafana+InfluxDB实时监控
1、硬件上的性能瓶颈: 一般指的是CPU、内存、磁盘读写等的瓶颈,为服务器硬件瓶颈。 2、应用软件上的性能瓶颈: 一般指的是服务器操作系统瓶颈(参数配置)、数据库瓶颈(参数配置)、web服务器瓶颈(参数配置)、中间件瓶颈(参数配置)等 3、应用程序上的性能瓶颈: 一般指的是开发人员,开发出来的应用程序(如sql语句、数据库设计、业务逻辑、算法等)。 4、操作系统上的性能瓶颈: 一般指的是Windows、linux等操作系统,如出现物理内存不足时,或虚拟内存设置不合理(虚拟内存设置不合理,会导致虚拟内存的交换率大大降低,从而导致行为的响应时间大大增加,
可以认为在操作系统上出现了性能瓶颈)。 5、网络设备上的性能瓶颈: 一般指的是防火墙、动态负载均衡器、交换机等设备

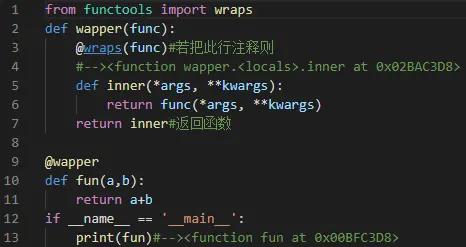
Python装饰器、迭代器、生成器
在 Python 中,使用了 yield 的函数被称为生成器;跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器;在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行;调用一个生成器函数,返回的是一个迭代器对象。

使用生成器生成斐波那些数列
装饰器
装饰器:在不改变原函数的基础上,对函数执行前后进行自定义操作。把目标函数作为参数传给装饰器函数,装饰器函数执行过程中,执行目标函数,达到在目标函数运行前后进行自定义操作的目的。
应用场景:如记录函数运行时间;flask里的路由、before_request;django中的缓存、用户登录等。

使用装饰器记录函数运行时间
装饰器在实现的时候,被装饰后的函数其实已经是另外一个函数了(函数名等函数属性会发生改变),为了不影响,Python的functools包中提供了一个叫wraps的装饰器来消除这样的副作用。写一个装饰器的时候,最好在实现之前加上functools的wrap,它能保留原有函数的名称和文档字符串。
Vue生命周期
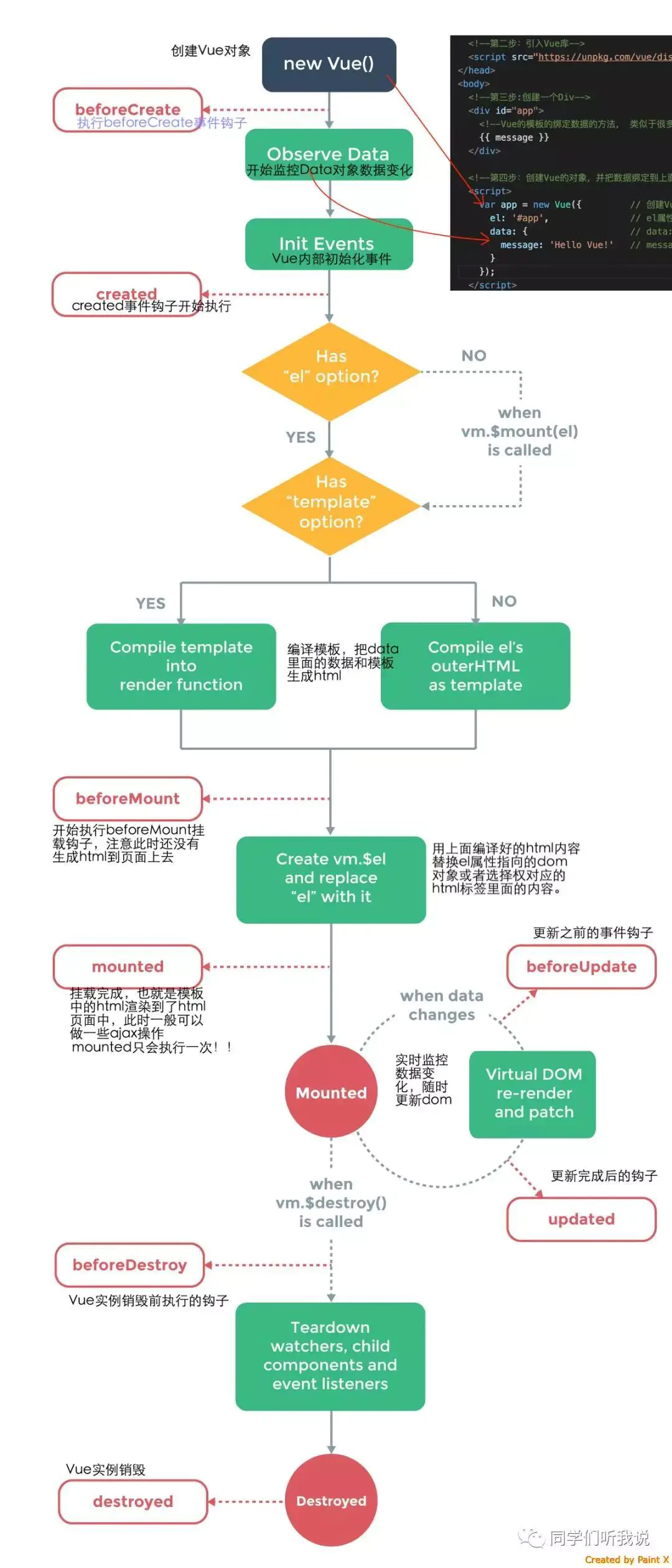
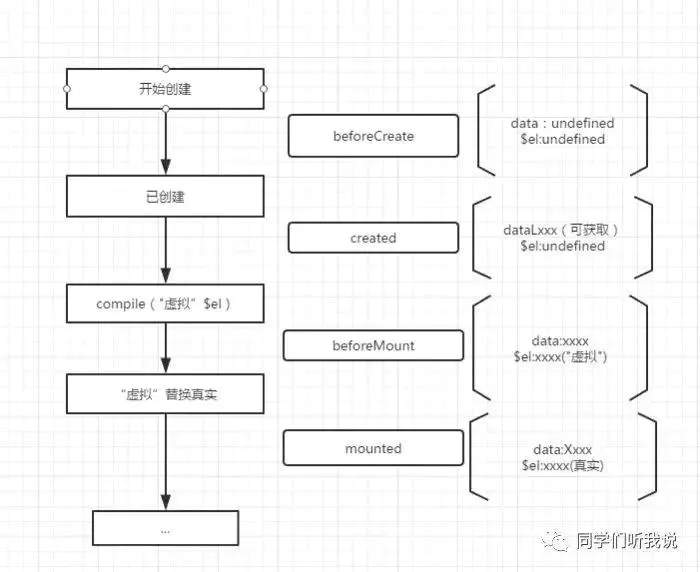
beforeCreate( 创建前 )
在实例初始化之后,数据观测和事件配置之前被调用,此时组件的选项对象还未创建,el 和 data 并未初始化,因此无法访问methods, data, computed等上的方法和数据。
created ( 创建后 )
实例已经创建完成之后被调用,在这一步,实例已完成以下配置:数据观测、属性和方法的运算,watch/event事件回调,完成了data 数据的初始化,el没有。 然而,挂在阶段还没有开始, $el属性目前不可见,这是一个常用的生命周期,因为你可以调用methods中的方法,改变data中的数据,并且修改可以通过vue的响应式绑定体现在页面上,,获取computed中的计算属性等等,通常我们可以在这里对实例进行预处理,也有一些童鞋喜欢在这里发ajax请求,值得注意的是,这个周期中是没有什么方法来对实例化过程进行拦截的,因此假如有某些数据必须获取才允许进入页面的话,并不适合在这个方法发请求,建议在组件路由钩子beforeRouteEnter中完成
beforeMount
挂在开始之前被调用,相关的render函数首次被调用(虚拟DOM),实例已完成以下的配置: 编译模板,把data里面的数据和模板生成html,完成了el和data 初始化,注意此时还没有挂在html到页面上。
mounted
挂在完成,也就是模板中的HTML渲染到HTML页面中,此时一般可以做一些ajax操作,mounted只会执行一次。
beforeUpdate
在数据更新之前被调用,发生在虚拟DOM重新渲染和打补丁之前,可以在该钩子中进一步地更改状态,不会触发附加地重渲染过程
updated(更新后)
在由于数据更改导致地虚拟DOM重新渲染和打补丁只会调用,调用时,组件DOM已经更新,所以可以执行依赖于DOM的操作,然后在大多是情况下,应该避免在此期间更改状态,因为这可能会导致更新无限循环,该钩子在服务器端渲染期间不被调用
beforeDestroy(销毁前)
在实例销毁之前调用,实例仍然完全可用,
- 这一步还可以用this来获取实例,
- 一般在这一步做一些重置的操作,比如清除掉组件中的定时器 和 监听的dom事件
destroyed(销毁后)
在实例销毁之后调用,调用后,所以的事件监听器会被移出,所有的子实例也会被销毁,该钩子在服务器端渲染期间不被调用
冒泡排序

九九乘法表
for i in range(1,10):
for j in range(1,i+1):
print("{}*{}={}".format(j,i,j*i),end=" ")
print()
执行以上脚本,输出结果如下:
1*1=1 1*2=2 2*2=4 1*3=3 2*3=6 3*3=9 1*4=4 2*4=8 3*4=12 4*4=16 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
列表去重
#!usr/bin/env python #encoding:utf-8 ''' __Author__:沂水寒城 功能:去除列表中的重复元素 ''' def func1(one_list): ''''' 使用集合,个人最常用 ''' return list(set(one_list))
def func2(one_list): ''''' 使用字典的方式 ''' return {}.fromkeys(one_list).keys()
def func3(one_list): ''''' 使用列表推导的方式 ''' temp_list=[] for one in one_list: if one not in temp_list: temp_list.append(one) return temp_list
def func4(one_list): ''''' 使用排序的方法 ''' result_list=[] temp_list=sorted(one_list) i=0 while i<len(temp_list): if temp_list[i] not in result_list: result_list.append(temp_list[i]) else: i+=1 return result_list
if __name__ == '__main__': one_list=[56,7,4,23,56,9,0,56,12,3,56,34,45,5,6,56] print "脚本之家测试结果:" print func1(one_list) print func2(one_list) print func3(one_list) print func4(one_list)
Python 二分查找
二分搜索是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。

# 返回 x 在 arr 中的索引,如果不存在返回 -1
def binarySearch (arr, l, r, x):
# 基本判断
if r >= l:
mid = int(l + (r - l)/2)
# 元素整好的中间位置
if arr[mid] == x:
return mid
# 元素小于中间位置的元素,只需要再比较左边的元素
elif arr[mid] > x:
return binarySearch(arr, l, mid-1, x)
# 元素大于中间位置的元素,只需要再比较右边的元素
else:
return binarySearch(arr, mid+1, r, x)
else:
# 不存在
return -1
# 测试数组
arr = [ 2, 3, 4, 10, 40 ]
x = 10
# 函数调用
result = binarySearch(arr, 0, len(arr)-1, x)
if result != -1:
print ("元素在数组中的索引为 %d" % result )
else:
print ("元素不在数组中")
python文件操作
文件上传:上传图片的类型是file,这里没有用到头部信息
import requests
def sendImg(img_path, img_name, img_type='image/jpeg'):
"""
:param img_path:图片的路径
:param img_name:图片的名称
:param img_type:图片的类型,这里写的是image/jpeg,也可以是png/jpg
"""
url = 'https://www.xxxxxxxxxx.com' # 自己想要请求的接口地址
with open(img_path + img_name, "rb")as f_abs:# 以2进制方式打开图片
body = {
# 有些上传图片时可能会有其他字段,比如图片的时间什么的,这个根据自己的需要
'camera_code': (None, "摄像头1"),
'image_face': (img_name, f_abs, img_type)
# 图片的名称、图片的绝对路径、图片的类型(就是后缀)
"time":(None, "2019-01-01 10:00:00")
}
# 上传图片的时候,不使用data和json,用files
response = requests.post(url=url, files=body).json
return response
if __name__=='__main__':
# 上传图片
res = sendImg(img_path, img_name) # 调用sendImg方法
print(res)
**如果上传图片是数组时,value直接写图片路径就可以**
文件上传:上传的类型是file,用到头部信息
# "Content-Type": "multipart/form-data; boundary=76a22e30da2bb7790828887966871012"
from urllib3 import encode_multipart_formdata
import requests
def sendFile(filename, file_path):
"""
:param filename:文件的名称
:param file_path:文件的绝对路径
"""
url = "https://www.xxxxxxx.com" # 请求的接口地址
with open(file_path, mode="r", encoding="utf8")as f: # 打开文件
file = {
"file": (filename, f.read()),# 引号的file是接口的字段,后面的是文件的名称、文件的内容
"key": "value", # 如果接口中有其他字段也可以加上
}
encode_data = encode_multipart_formdata(file)
file_data = encode_data[0]
# b'--c0c46a5929c2ce4c935c9cff85bf11d4
Content-Disposition: form-data; name="file"; filename="1.txt"
Content-Type: text/plain
...........--c0c46a5929c2ce4c935c9cff85bf11d4--
headers_from_data = {
"Content-Type": encode_data[1],
"Authorization": token
}
# token是登陆后给的值,如果你的接口中头部不需要上传字段,就不用写,只要前面的就可以
# 'Content-Type': 'multipart/form-data; boundary=c0c46a5929c2ce4c935c9cff85bf11d4',这里上传文件用的是form-data,不能用json
response = requests.post(url=url, headers=headers_from_data, data=file_data).json()
return response
if __name__=='__main__':
# 上传文件
res = sendFile(filename, file_path) # 调用sendFile方法
print(res)