常用Spark-SQL数据处理总结
导语: 本文是在实习工作当中就遇到的数据处理当中Spark-SQL相关的操作做一个总结。主要包含ArrayType, JSON等复杂数据类型的处理。以及UDF的各种实现, 希望通过更加简单的处理方式提高程序的可读性, 代码简洁性和优雅性。
本文是使用Scala-test框架写的测试用例。并且将SparkSession进行如下封装。下文的所有测试用例都遵循此规则。
trait SparkSessionTestWrapper {
lazy val spark: SparkSession = {
SparkSession
.builder()
.master("local[*]")
.appName("spark test example")
.config("spark.driver.bindAddress","127.0.0.1")
.getOrCreate()
}
}
UDF常用方法
-
无参数输入, 输出一列
下面是新添加一个空的Array列的示例
class UdfTest extends FunSuite with SparkSessionTestWrapper { test("testUdf") { import spark.implicits._ val sourceDf = Seq( ("测试") ).toDF("name") val emptyArray = udf(() => Array.empty[String]) val actualDf = sourceDf.withColumn("value", emptyArray()) actualDf.printSchema() actualDf.show() } }运行结果如下:
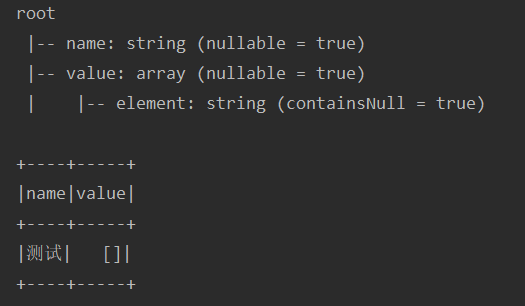
-
输入一列, 输出一列
test("testUdf2") { import spark.implicits._ // 定义UDF def sexMapFunction: UserDefinedFunction = udf((sex: String) => { sex match { case "0" => "F" case "1" => "M" case "2" => "N" case _ => "N" } }) val sourceDf = Seq( ("张三", "0"), ("李四", "1"), ("王五", "2"), ("刘六", "3") ).toDF("name", "code") val actualDf = sourceDf.withColumn("sex", sexMapFunction(col("code"))) actualDf.printSchema() actualDf.show() println("**************** following is sql test ****************") spark.udf.register("sexMap", sexMapFunction) sourceDf.createTempView("table_tmp") val sql = "SELECT name, code, sexMap(code) as sex FROM table_tmp"; val df = spark.sql(sql) df.printSchema() df.show() }运行结果如下:
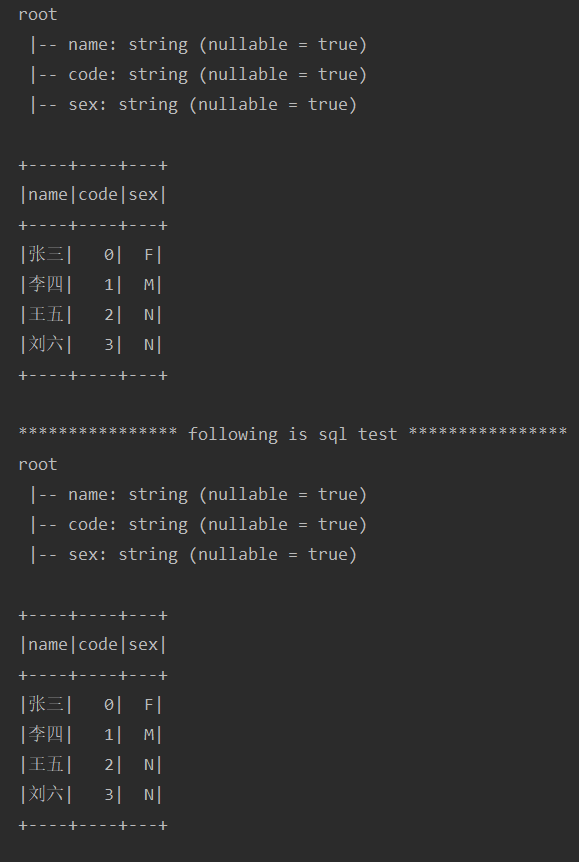
-
输入一列, 输出多列
test("testUdf3") { import spark.implicits._ case class Test(id: Int, name: String) val schema = StructType(List(StructField("id", IntegerType), StructField("name", StringType))) // 定义UDF def SplitFunction: UserDefinedFunction = udf((str: String) => { val splits = str.split(",") Test(splits(0).toInt, splits(1)) }, schema) val sourceDf = Seq( ("1,张三"), ("2,李四"), ("3,王五") ).toDF("case") var actualDf = sourceDf.withColumn("idname", SplitFunction(col("case"))) actualDf = actualDf.select("case", "idname.*") actualDf.printSchema() actualDf.show() }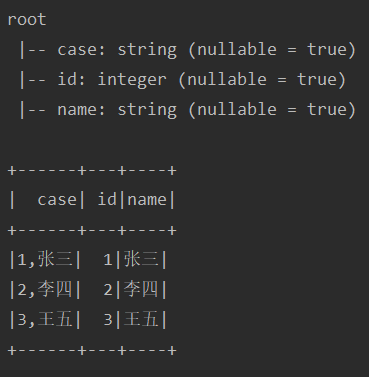
-
输入多列, 输出一列
test("testUdf4") { import spark.implicits._ def AvgScoreFunction: UserDefinedFunction = udf((row: Row) => { row.schema.fields.map { field => field.dataType match { case IntegerType => row.getAs[Int](field.name).toDouble case StringType => row.getAs[String](field.name).toDouble case FloatType => row.getAs[Float](field.name).toDouble case DoubleType => row.getAs[Double](field.name) case LongType => row.getAs[Long](field.name).toDouble } }.sum / row.schema.fields.length }) val sourceDf = Seq( ("张三", "34", 28, 19F, 29.0, 99L), ("李四", "90.5", 110, 80.8F, 88.88, 60L) ).toDF("姓名", "语文", "数学", "英语", "物理", "体育") sourceDf.printSchema() sourceDf.show() var actualDf = sourceDf.withColumn("语数外平均成绩", AvgScoreFunction(struct("语文", "数学", "英语"))) actualDf.printSchema() actualDf.show() actualDf = sourceDf.withColumn("全部课程平均成绩", AvgScoreFunction(struct(sourceDf.columns.drop(1).map(col): _*))) actualDf.show() }运行结果
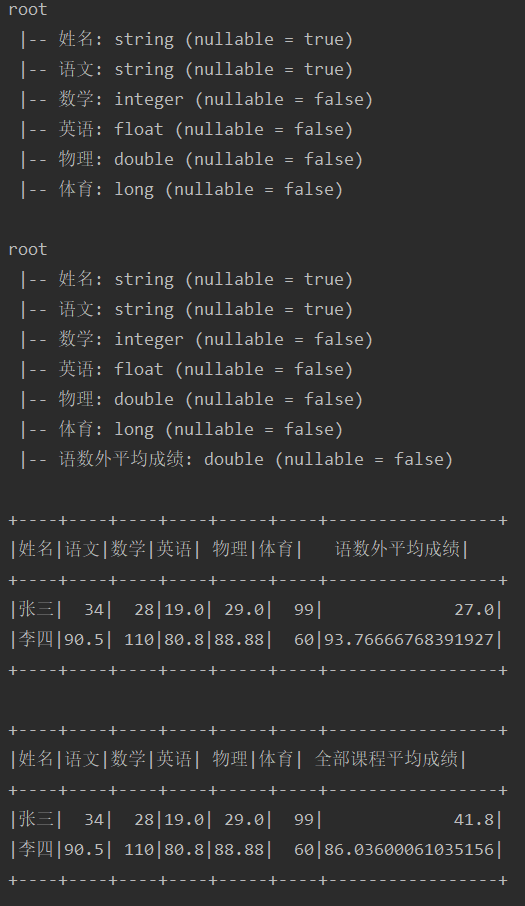
JSON数据类型处理
-
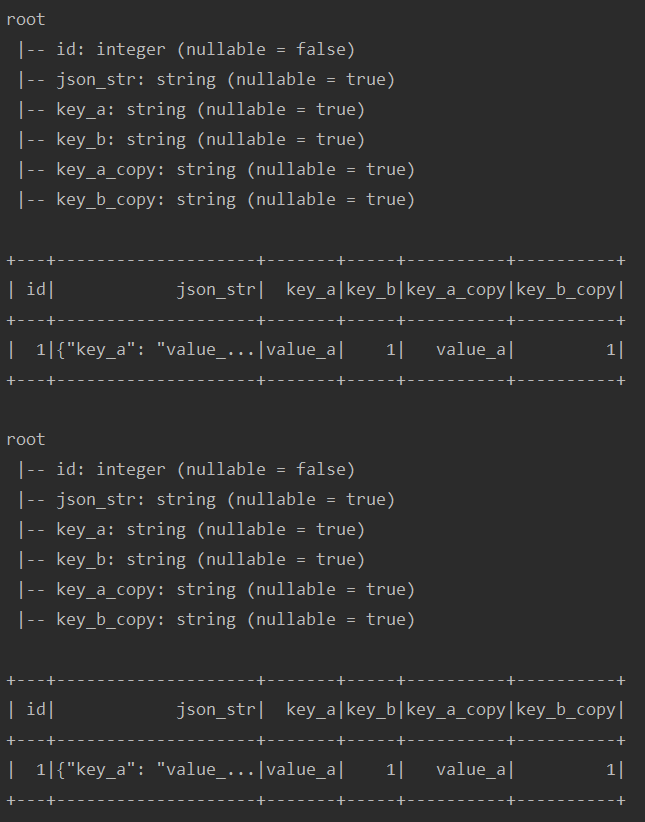
提取单个(多个)字段值
test("testUdf5") { import spark.implicits._ val sourceDf = Seq( (1, "{"key_a": "value_a", "key_b": 1}") ).toDF("id", "json_str") var actualDf = sourceDf.withColumn("key_a", get_json_object(col("json_str"), "$.key_a")) // get_json_object 获取单个json字段 .withColumn("key_b", get_json_object(col("json_str"), "$.key_b")) // json_tuple 获取多个字段 .select(col("id"), col("json_str"), col("key_a"), col("key_b"), json_tuple(col("json_str"), "key_a", "key_b").as(Seq("key_a_copy", "key_b_copy"))) actualDf.printSchema() actualDf.show() sourceDf.createTempView("table_tmp") val sql = """ | SELECT id, | json_str, | get_json_object(t.json_str, "$.key_a") as key_a, | get_json_object(t.json_str, "$.key_b") as key_b, | j.key_a_copy, | j.key_b_copy | FROM table_tmp t | LATERAL VIEW json_tuple(t.json_str, 'key_a', 'key_b') j as key_a_copy, key_b_copy |""".stripMargin actualDf = spark.sql(sql) actualDf.printSchema() actualDf.show() }运行结果
-
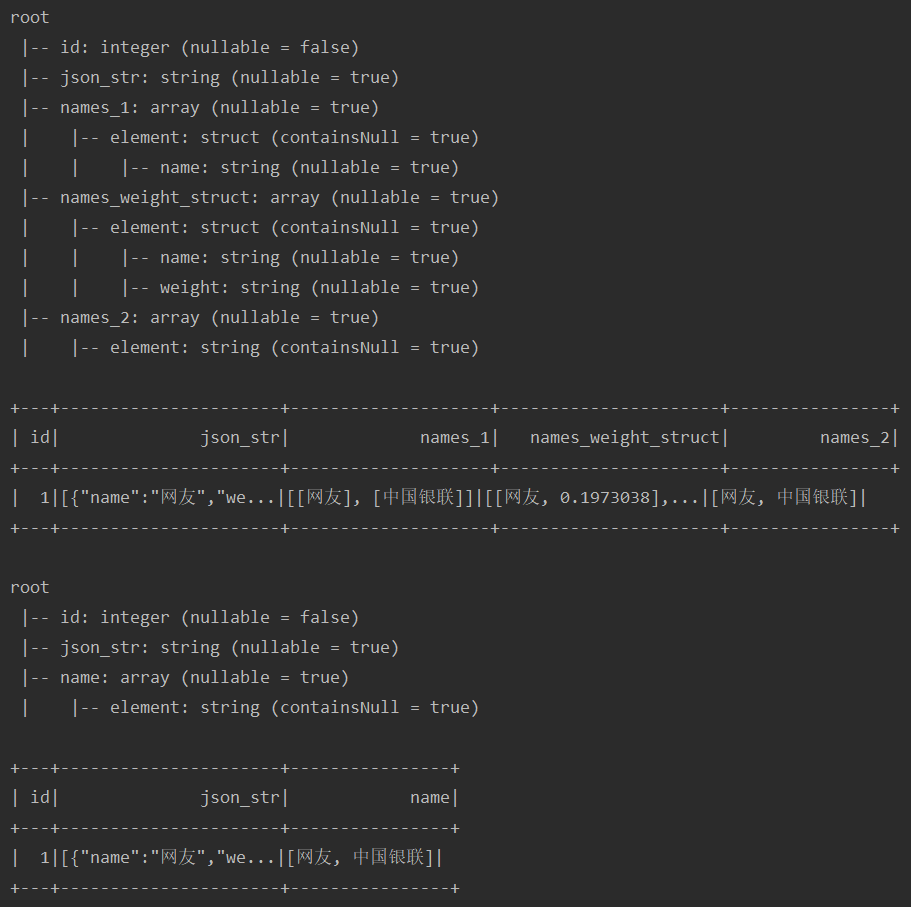
提取JSON数组
test("testUdf6") { import spark.implicits._ val sourceDf = Seq( (1, """ |[ | { | "name": "网友", | "weight": 0.1973038 | }, | { | "name": "中国银联", | "weight": 0.1973038 | } |] |""".stripMargin.replaceAll("\s", "")) ).toDF("id", "json_str") var actualDf = sourceDf // 获取单个字段 .withColumn("names_1", from_json(col("json_str"), ArrayType(StructType(List(StructField("name", StringType)))))) // 获取多个字段 .withColumn("names_weight_struct", from_json(col("json_str"), ArrayType(StructType(List(StructField("name", StringType), StructField("weight", StringType)))))) // 获取单个字段 .withColumn("names_2", split(regexp_replace(get_json_object(col("json_str"), "$[*].name"), ""|\[|\]", ""), ",")) actualDf.printSchema() actualDf.show() // 通过SQL的方式获取单个字段 sourceDf.createTempView("table_tmp") val sql = """ | SELECT id, | json_str, | split(regexp_replace(get_json_object(json_str, "$[*].name"), "\[|\]|"", ""), ",") as name | FROM table_tmp t |""".stripMargin actualDf = spark.sql(sql) actualDf.printSchema() actualDf.show() }运行结果
其他Spark-SQL操作
-
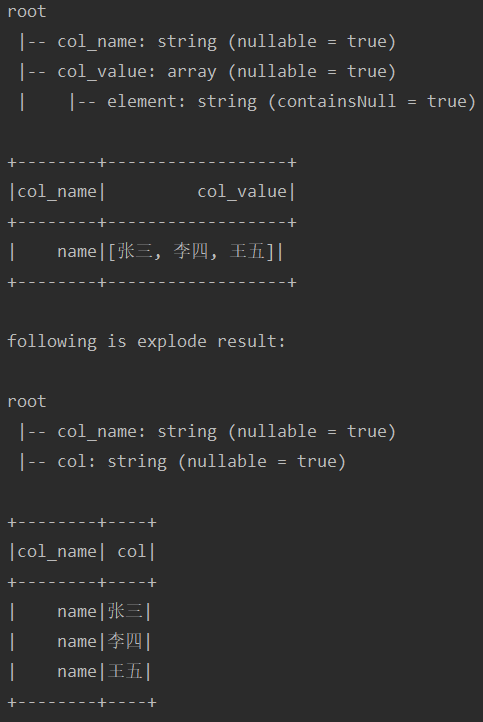
将某列的一行array展开。
test("testUdf7") { import spark.implicits._ val sourceDf = Seq( ("name", Array("张三", "李四", "王五")) ).toDF("col_name", "col_value") sourceDf.printSchema() sourceDf.show() println(" following is explode result: ") val actualDf = sourceDf.select(col("col_name"), explode(col("col_value"))) actualDf.printSchema() actualDf.show() }运行结果
-
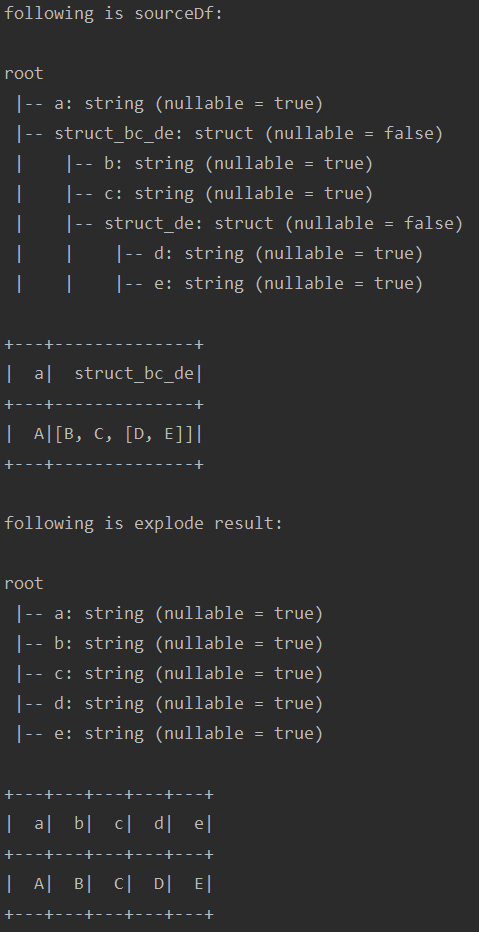
Flatten 嵌套的 struct 列
test("testUdf8") { import spark.implicits._ var sourceDf = Seq( ("A", "B", "C", "D", "E") ).toDF("a", "b", "c", "d", "e") sourceDf = sourceDf.withColumn("struct_de", struct("d", "e")) .withColumn("struct_bc_de", struct("b", "c", "struct_de")) .select("a", "struct_bc_de") println("following is sourceDf: ") sourceDf.printSchema() sourceDf.show() def flattenStructSchema(schema: StructType, prefix: String = null) : Array[Column] = { schema.fields.flatMap(f => { val columnName = if (prefix == null) f.name else (prefix + "." + f.name) f.dataType match { case st: StructType => flattenStructSchema(st, columnName) case _ => Array( col(columnName) // 这列别名可以不加 //.as(columnName.replace(".","_")) ) } }) } val actualDf = sourceDf.select(flattenStructSchema(sourceDf.schema): _*) println("following is explode result: ") actualDf.printSchema() actualDf.show() }运行结果
-
添加聚合列, 但是保留其他所有列
test("testUdf9") { import spark.implicits._ var sourceDf = Seq( ("a", "b", 1, "c", "d"), ("a", "b", 2, "m", "n"), ("a", "b", 3, "p", "q"), ("a", "B", 2, "u", "v"), ("a", "B", 1, "x", "y"), ("a", "B", 3, "r", "w") ).toDF("col_1", "col_2", "number", "col_other_1", "col_other_2") sourceDf.printSchema() sourceDf.show() val groupCols = Array("col_1", "col_2") val structCol = "struct" sourceDf = sourceDf.withColumn(structCol, struct(sourceDf.columns.diff(groupCols).map(col): _*)) println("following is result: ") var actualDf = sourceDf.groupBy(groupCols.map(col): _*) .agg( sum("number").as("sum"), avg("number").as("average"), collect_list(structCol).as(structCol)) actualDf = actualDf.select(actualDf.columns.diff(structCol).map(col) :+ explode(col(structCol)) : _*) .drop(structCol) actualDf = actualDf.select(flattenStructSchema(actualDf.schema): _*) actualDf.printSchema() actualDf.show() }运行结果如下:
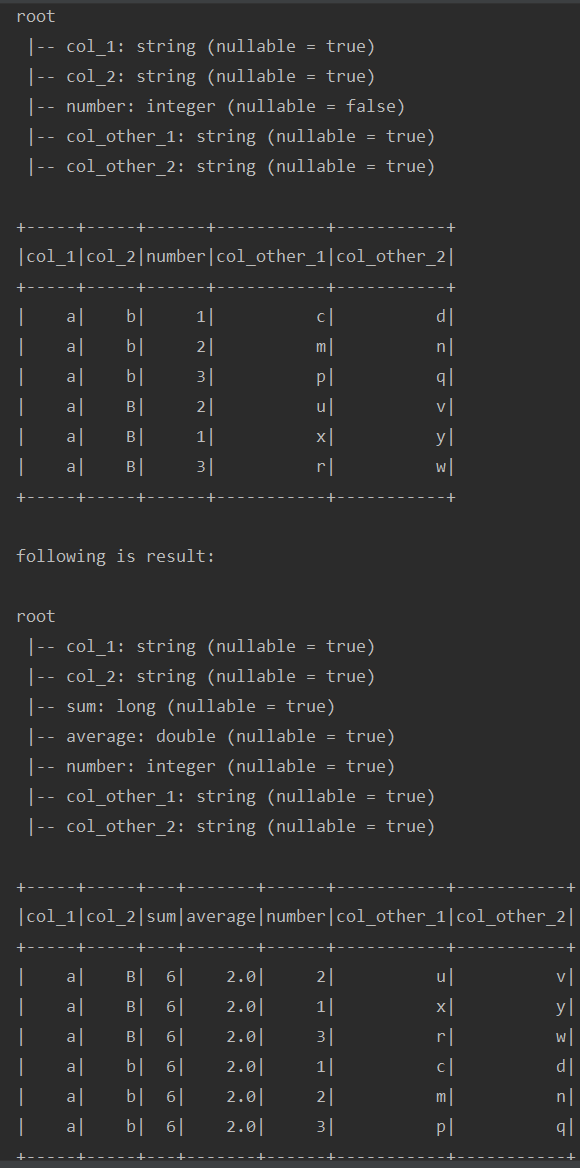
-
一个DataFrame JOIN 另一个DataFrame两次
test("testUdf10") { import spark.implicits._ var sourceDf = Seq( (1, 2), (3, 4) ).toDF("id_1", "id_2") var userDf = Seq( (1, "张三"), (2, "李四"), (3, "王五"), (4, "刘六") ).toDF("id", "name") sourceDf.show() userDf.show() var actualDf = sourceDf.join(userDf, sourceDf.col("id_1") === userDf.col("id"), "left") .withColumn("name_1", userDf.col("name")) actualDf = actualDf.join(userDf, actualDf.col("id_2") === userDf.col("id"), "left") .withColumn("name_2", userDf.col("name")) println("following is join result: ") actualDf.printSchema() actualDf.show() }上面程序是souceDf连续join userDf两次, 于是报了错。原因是检查到了笛卡尔积
Detected implicit cartesian product for LEFT OUTER join between logical plans Project [id_1#5, id_2#6, id#14, name#15, name#15 AS name_1#44] +- Join LeftOuter, (id_1#5 = id#14) :- LocalRelation [id_1#5, id_2#6] +- LocalRelation [id#14, name#15] and LocalRelation [id#50, name#51] Join condition is missing or trivial. Either: use the CROSS JOIN syntax to allow cartesian products between these relations, or: enable implicit cartesian products by setting the configuration variable spark.sql.crossJoin.enabled=true; org.apache.spark.sql.AnalysisException: Detected implicit cartesian product for LEFT OUTER join between logical plans Project [id_1#5, id_2#6, id#14, name#15, name#15 AS name_1#44] +- Join LeftOuter, (id_1#5 = id#14) :- LocalRelation [id_1#5, id_2#6] +- LocalRelation [id#14, name#15] and LocalRelation [id#50, name#51] Join condition is missing or trivial. Either: use the CROSS JOIN syntax to allow cartesian products between these relations, or: enable implicit cartesian products by setting the configuration variable spark.sql.crossJoin.enabled=true; at org.apache.spark.sql.catalyst.optimizer.CheckCartesianProducts$$anonfun$apply$22.applyOrElse(Optimizer.scala:1295)解决办法:给要Join的DataFrame加上别名, 如下
test("testUdf10") { import spark.implicits._ var sourceDf = Seq( (1, 2), (3, 4) ).toDF("id_1", "id_2").as("sourceDf") val userDf = Seq( (1, "张三"), (2, "李四"), (3, "王五"), (4, "刘六") ).toDF("id", "name").as("userDf") sourceDf.show() userDf.show() var leftJoinedDf = sourceDf.join(userDf, col("sourceDf.id_1") === col("userDf.id"), "left") .withColumn("name_1", userDf.col("name")).alias("leftJoinedDf") val actualDf = leftJoinedDf.join(userDf, col("leftJoinedDf.id_2") === col("userDf.id"), "left") .withColumn("name_2", userDf.col("name")) .select("id_1", "name_1", "id_2", "name_2") println("following is join result: ") actualDf.printSchema() actualDf.show() }运行结果如下:
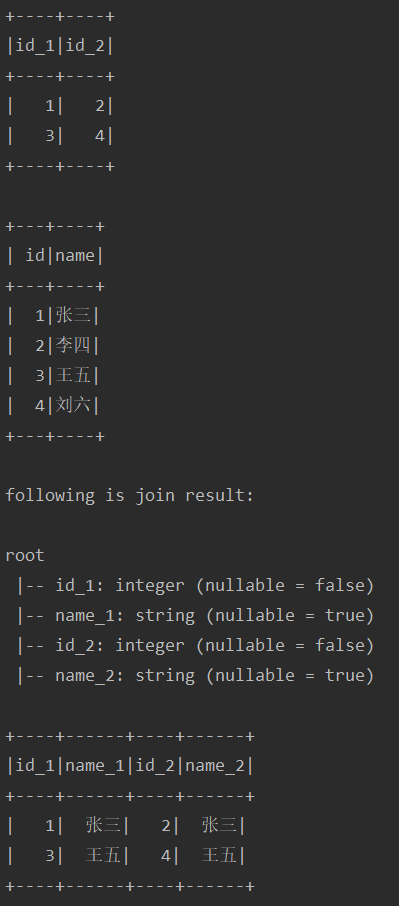
-
DataFrame转RDD使用Map方法的另一种写法
def mapFunction: UserDefinedFunction = udf((row: Row) => { // 自已在这里写需要的返回值, 可以是一列, 也可以是多列, 参照本文的第一部分UDF写法 }) df.withColumn("map_return", mapFunction(df.columns.map(col): _*)) -
填充空值为默认值
def naMap(df: DataFrame): Map[String, Any] = { df.schema.filter(field => Seq(StringType, LongType, IntegerType, DoubleType, ByteType, ShortType) .contains(field.dataType)) .map(column => { column.dataType match { case IntegerType | LongType | ByteType | ShortType => (column.name -> 0) case StringType => (column.name -> "") case DoubleType => (column.name -> 0.0) } }).toMap } df = df.na.fill(naMap(df)) -
存表前自动调整字段顺序并自动填充缺失列
def selectColumn(df: DataFrame, schema: StructType): DataFrame = { val original = df.dtypes.map(v => v._1) val defaultValueMap = Map("ByteType" -> 0, "IntegerType" -> 0, "LongType" -> 0, "StringType" -> "", "FloatType" -> 0.0, "DoubleType" -> 0.0) var rtn = df for (field <- schema.fields) { // 如果select的字段在df.schema中不存在 if (!original.contains(field.name)) { // 字段名称在defaultFieldMap中没有, 则使用字段类型映射默认值 rtn = rtn.withColumn(field.name, lit(defaultValueMap(field.dataType.toString))) } } val selectFields = schema.fields.map(v => v.name) rtn.select(selectFields(0), selectFields.drop(1): _*) } -
JDBC操作DataFrame
df.rdd.foreachPartition(iterator => { val db = DBUtils(url, name, password) db.prop.setProperty("rewriteBatchedStatements", "true") val conn = db.getConnection val args = List.fill(fieldLen)("?") val sql = s"INSERT IGNORE INTO table_name (`a`, `b`) values (?, ?) " val ps = conn.prepareStatement(sql) var size = 0 iterator.foreach(row => { for ((dataTypeMap, index) <- dataTypeMap.zipWithIndex) { dataTypeMap._2 match { case StringType => ps.setString(index + 1, row.getString(index)) case IntegerType => ps.setInt(index + 1, row.getInt(index)) case LongType => ps.setLong(index + 1, row.getLong(index)) case DoubleType => ps.setDouble(index + 1, row.getDouble(index)) case ByteType => ps.setByte(index + 1, row.getByte(index)) case ShortType => ps.setShort(index + 1, row.getShort(index)) } } size += 1 ps.addBatch() if (size == batchSize) { ps.executeBatch() ps.clearBatch() size = 0 } }) ps.executeBatch() conn.close() })