HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统
HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBASE利用Hadoop HDFS作为其文件存储系统
HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据
HBASE利用Zookeeper作为协同服务。
Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单
Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便
|
hdfs是适于存储大容量文件的分布式文件系统 |
hbase是建立在hdfs上的数据库 |
|
hdfs不支持快速单独记录查找 |
hbase提供较大的表快速查询 |
|
高延迟 |
低延迟记录访问 |
|
数据只能顺序访问 |
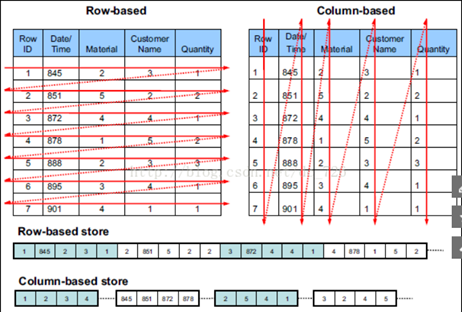
1.1. 与传统数据库的对比
1、传统数据库遇到的问题:
1) 数据量很大的时候无法存储
2) 没有很好的备份机制
3) 数据达到一定数量开始缓慢,很大的话基本无法支撑
2、HBASE优势:
1)线性扩展,随着数据量增多可以通过节点扩展进行支撑
2)数据存储在hdfs上,备份机制健全
3)通过zookeeper协调查找数据,访问速度块。
hbase表优点:
大:一个表可以有数亿行,列
无模式:每一行都有一个可排序的主键和任意多的列,列可以根据需要动态的添加,同一张表中的不同行可以有不同的列
面向列:列可以独立检索
稀疏:空(null)不占用存储空间,表可以设计的非常稀疏
数据多版本:每个单元中的数据可以有多个版本,默认情况下版本自动分配是插入数据时的
时间戳
数据类型单一:hbase中的数据都是字符串,没有类型
缺点:
不支持条件查询,只支持按照row key来查询
暂时不支持master server的故障切换,当master宕机后,整个存储系统挂掉
补充:
- 数据类型,Hbase只有简单的字符类型,所有的类型都是交由用户自己处理,它只保存字符串。而关系数据库有丰富的类型和存储方式。
- 数据操作:HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,而传统数据库通常有各式各样的函数和连接操作。
- 存储模式:HBase是基于列存储的,每个列族都由几个文件保存,不同的列族的文件时分离的。而传统的关系型数据库是基于表格结构和行模式保存的
- 数据维护,HBase的更新操作不应该叫更新,它实际上是插入了新的数据,而传统数据库是替换修改
- 可伸缩性,Hbase这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻松增加或减少硬件的数量,并且对错误的兼容性比较高。而传统数据库通常需要增加中间层才能实现类似的功能
hbase数据模型:
|
row key |
time stamp |
column family |
||
|
id |
name |
age |
||
|
id:1001 |
name:lisa |
age:21 |
||
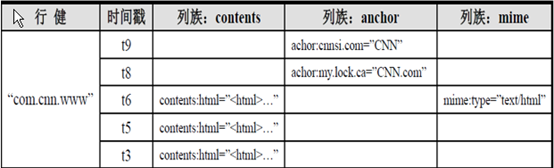
row key:是字节数组,是表中每条记录的主键,table中的记录按照row key进行排序
column family:列簇拥有一个名称,table在水平方向上可以有一个或者多个列簇,每个列簇包含一个或者多个相关列(column),支持动态扩展,无需预先定义Column的数量以及类型
(version number)timestamp:默认是时间戳,用户可自定义
列簇由多个列组成,无需定义列的数量以及类型,支持动态扩展
随着table的数据内容增加,会被分成多个regions,每一个被分配到不同的regionserver进行管理
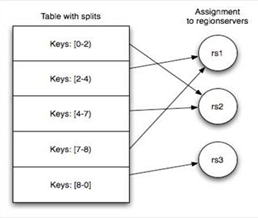
两张特殊的表MATE和ROOT
l MATE记录用户表的region信息,可以有多个region
l ROOT记录META表的region信息,只有一个region
zookeeper记录着ROOT表的location
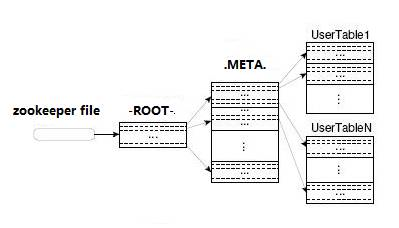
用户访问数据过程:
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过client端会做cache缓存。
zookeeper在hbase中的作用
|
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态 通过选举,保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册 存贮所有Region的寻址入口 实时监控Region server的上线和下线信息。并实时通知给Master 存储HBase的schema和table元数据 默认情况下,HBase 管理ZooKeeper 实例,比如, 启动或者停止ZooKeeper Zookeeper的引入使得Master不再是单点故障 |
Hmaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:
- 管理用户对table的增、删、改、查操作
- 管理HRegionServer的负载均衡,调整Region分布
- 在Region Split后,负责新Region的分配
- 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
HregionServer
主要负责响应用户的I/O请求,向hdfs中读写数据,是hbase中最核心的模块
hbase的存储:
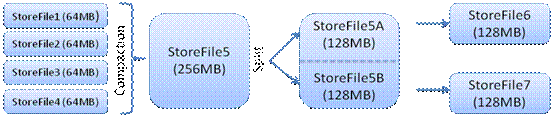
Hstore由memstore和storefile组成
用户写入数据会先放到memstore,当memstore满了以后会flush成一个storefile
当多个storefile增加到阈值会触发compact 合并操作,合并成一个storfile,这个过程中会进行版本合并和数据删除
Hlog对象
每个HregionServer都有一个Hlog对象
每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中
当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复