写SQL的时候 , 如果要分组取最新的数据 , 一般可以有两种方法
1 drop table if exists #a 2 3 select * into #a from ( 4 select symbol='001',price=10,tdate='20190601' 5 union all 6 select symbol='001',price=15,tdate='20190801' 7 union all 8 select symbol='002',price=20,tdate='20190601' 9 union all 10 select symbol='002',price=25,tdate='20190801' 11 )a order by tdate 12 13 select * from #a -- 查看表中数据 14 -- 常规写法 15 select * from #a x 16 where tdate=(select max(tdate) from #a where x.symbol=symbol) 17 18 -- 等价写法 19 select symbol,price,tdate from ( 20 select symbol,price,tdate,rn=row_number() over(partition by symbol order by tdate desc) from #a 21 )a where rn=1 22 23 drop table #a
结果如下图
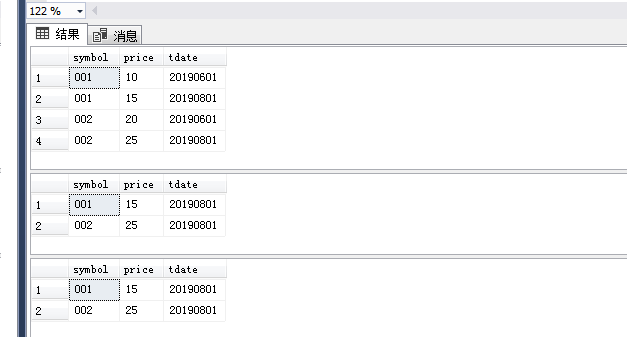
前提是 日期字段 tdate不会有重复
1.第一种是用子查询max , 这种方法常用而且简单 但是有局限性 就是只能对一个字段进行排序 , 分组条件即where 后面的条件
这里是symbol 还可以加上其他的条件比如 x.symbol=symbol and x.exchange=exchange
这里的条件和分组条件group by以及row_number()的partition by条件实现的功能是一样的
注意#a的表的别名 x 是写在哪里的 不能写在子查询里面
如果写在子查询里面那么where x.symbol=symbol就等于没写 相当于取整张表的max(tdate) 没有实现分组作用
但是刚开始写SQL的时候会难以理解 为啥这样也可以
2.另一种是row_number() 这种方法如果是只用在取最新数据 , 就有点大材小用了 而且不如上一种方法简单 但是他可以在order by tdate 排序之后增加其他的排序规则
比如 order by tdate desc,price desc
但这个例子后面再写其他的排序字段也没用了 因为tdate是唯一的
谢谢!